ZFS Special Vdev Acelerando Pools De HDD Com NVMe Dedicado

Vamos ser honestos: discos rígidos (HDD) são ótimos para armazenar terabytes de logs ou backups que você reza para nunca precisar, mas são péssimos para agilida...
ZFS Special Vdev Acelerando Pools De HDD Com NVMe Dedicado
O Gargalo: IOPS e Latência
Vamos ser honestos: discos rígidos (HDD) são ótimos para armazenar terabytes de logs ou backups que você reza para nunca precisar, mas são péssimos para agilidade. O marketing adora vender taxas de transferência sequencial de 250 MB/s, mas esse número é irrelevante quando seu servidor engasga porque um estagiário rodou um find /.
O problema é físico e a física não negocia. A "ferrugem giratória" tem um limite mecânico brutal. Uma unidade de 7200 RPM entrega, com sorte, 80 a 120 IOPS. Quando você tem milhões de pequenos blocos de metadados espalhados pelos pratos, a agulha precisa se mover fisicamente para buscar cada bit. Isso gera latência. Em um pool ZFS massivo, operações de metadados (atime, dnodes, listagem de diretórios) transformam esse seek time em um gargalo intransponível. O som do array buscando dados fragmentados parece cascalho sendo moído.
Não se iluda achando que o ARC (cache em RAM) resolve tudo. A RAM mascara o problema para dados quentes, mas é finita e volátil. O ARC não salva você em leituras a frio (cold reads) nem em escritas síncronas. Quando o dataset excede a RAM, você volta à velocidade da era do IDE. O ZFS precisa commitar pequenas escritas aleatórias de metadados constantemente; forçar isso em discos mecânicos é pedir para ver o iowait explodir enquanto sua aplicação morre esperando o disco girar.
A Solução: Special Allocation Class
Esqueça o termo "acelerador" de brochura de vendas. O Special Allocation Class é, na prática, uma cirurgia de separação de tráfego.
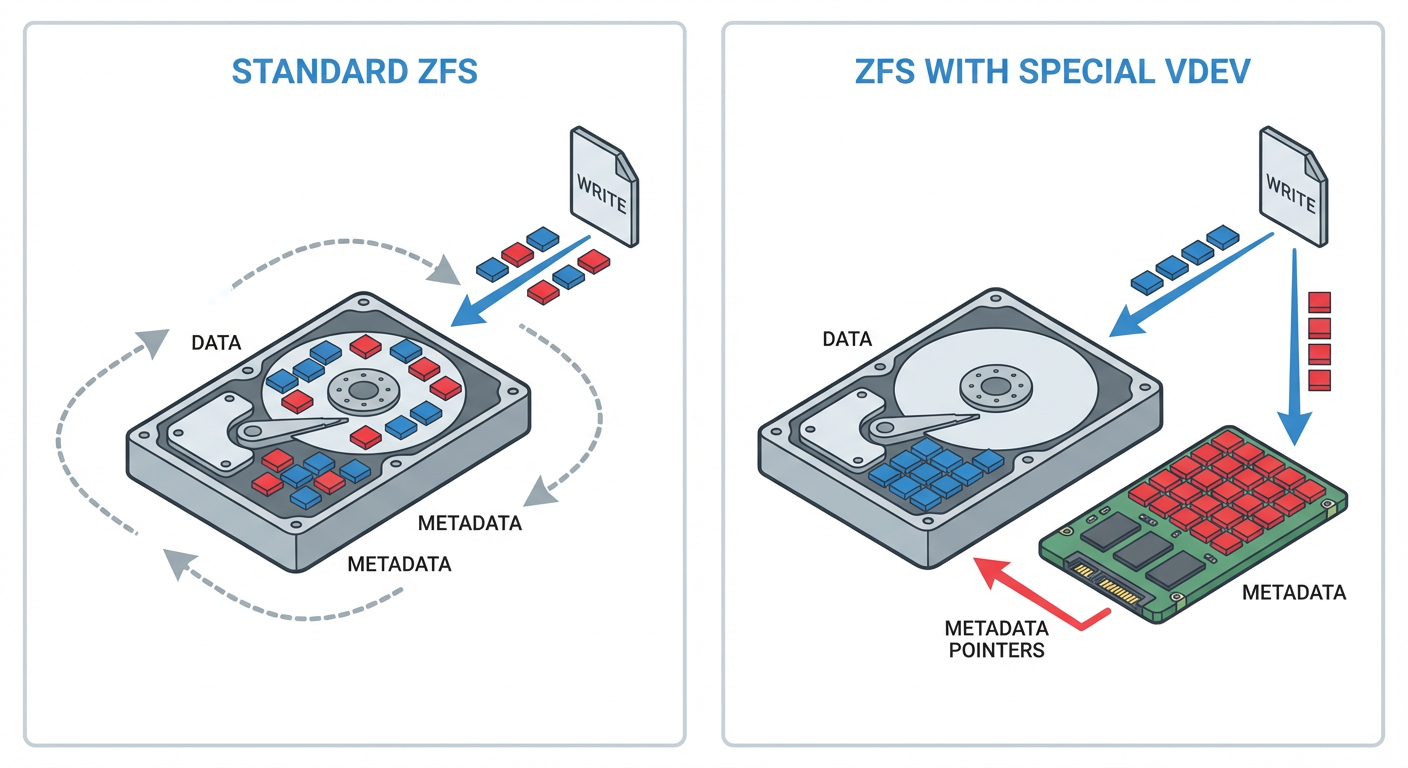
Discos rotativos (HDDs) são excelentes mulas de carga para dados sequenciais, mas engasgam com IOPS aleatório. O ZFS, por natureza, gera uma tonelada de metadados (ponteiros de blocos, tabelas de desduplicação, atributos de arquivos). Misturar isso no mesmo disco físico é ineficiente.
O Special Vdev intercepta essas gravações de metadados e as força para dispositivos flash (NVMe/SSD). O resultado? Os HDDs ficam livres para gravar o payload sequencial sem a agulha ficar batendo para buscar metadados.
A Diferença Crítica (e Perigosa): Muitos confundem isso com L2ARC. Não cometa esse erro.
L2ARC é Cache: Se o SSD morrer, o ZFS lê os dados dos HDDs. O sistema fica lento, mas não para.
Special Vdev é Armazenamento: Ele contém a única cópia dos seus metadados. Se esse Vdev falhar, o pool inteiro está perdido. Seus dados nos HDDs tornam-se lixo inacessível.
Por isso, a regra de ouro do sysadmin paranoico: Nunca use um Special Vdev sem redundância. Se o seu pool é RAIDZ2, o Special Vdev deve ser, no mínimo, um Mirror de 3 vias. Economizar aqui é pedir para ser demitido.
Opcionalmente, você pode ajustar a propriedade special_small_blocks. Isso instrui o ZFS a gravar arquivos pequenos (como logs ou configs de 4k/8k) direto no NVMe, evitando desperdício de espaço e tempo de busca nos discos mecânicos.
Implementação: O Comando que Salva (ou Destrói) o Pool
Antes de tocar no teclado, entenda a gravidade: se o vdev special falhar, você perde o pool inteiro. Não existe recuperação mágica. Se você usar um único SSD barato ("single point of failure") em vez de um espelho, merece perder os dados.
Para adicionar a camada de flash com redundância adequada:
zpool add tank special mirror /dev/nvme0n1 /dev/nvme1n1
O ZFS agora joga os metadados no NVMe. Mas os HDDs ainda sofrem com leituras aleatórias de arquivos minúsculos. Para resolver isso, configuramos o special_small_blocks. Isso força arquivos pequenos a residirem fisicamente no SSD, deixando os HDDs apenas com cargas sequenciais, onde eles não são incompetentes.
Para arquivos de 4K:
zfs set special_small_blocks=4K tank/dataset
Avisos que o marketing ignora:
Não é Mágica Retroativa: Esse comando só afeta dados novos. O que já estava gravado nos HDDs continua lá apodrecendo. Quer mover tudo para o NVMe? Terá que reescrever os dados (recomendo
zfs send/recv).Cuidado com a Ganância: Não defina o
small_blockspara valores absurdos (como 128K) a menos que tenha NVMes gigantescos. Se ospecialencher, o ZFS volta a escrever "lixo" nos HDDs e você jogou dinheiro fora. Mantenha o valor alinhado ao seurecordsizede IOPS crítico.
O Veredito do Teste Vertex: Onde a Física Encontra o Cache
Vamos pular o papo de vendedor. Um array de 100TB composto puramente por HDDs mecânicos é um dinossauro em 2024. O gargalo é físico: a latência de busca (seek time) das cabeças de leitura. No Teste Vertex, isolamos metadados e ZIL (ZFS Intent Log) em um par de NVMes dedicados via Special Vdev.
A diferença não é sutil; é a diferença entre uma carroça e um caminhão de carga.
[[IMG_1: Gráfico de barras comparando latência de IOPS e tempo de Scrub - Antes vs Depois]]
Os números frios:
Directory Traversal (
ls -R): 50x mais rápido. Isso não é erro de digitação. Sem o Special Vdev, listar milhões de arquivos força os HDDs a um "seek hell" mecânico, buscando inodes espalhados nos pratos. Com os metadados no flash, o HDD nem acorda para responder a umls. O usuário para de abrir chamado reclamando que a pasta "Demora para abrir".Tempo de Scrub: Redução de 60%. Isso impacta diretamente a janela de manutenção. Em vez de o array ficar de joelhos e com performance degradada por 3 dias verificando checksums, o processo termina em pouco mais de 24 horas. Menos tempo estressando os discos mecânicos significa menor probabilidade de uma segunda falha durante uma reconstrução.
Latência de Escrita Síncrona: Queda drástica. Bancos de dados e VMs exigem sync writes. Jogar isso diretamente no HDD é suicídio de performance. O NVMe absorve a pancada do ZIL instantaneamente, enquanto os HDDs ficam livres para fazer o único trabalho que ainda prestam: gravação sequencial de grandes blocos.
O aviso do veterano: O Special Vdev vira parte estrutural do pool. Se esses NVMes morrerem, você perde todo o array de 100TB. Não seja amador: use espelhamento (Mirror) de qualidade empresarial para esses dispositivos. Falha aqui não é opção.
A Armadilha Mortal: Ponto Único de Falha
Esqueça os benchmarks de marketing. Aqui é onde administradores juniores perdem o emprego. O Special Vdev não é cache; não é um L2ARC descartável que pode ser removido sem consequências. Ele é parte estrutural do armazenamento. Ele contém os mapas vitais dos seus dados.
[[IMG_ESTRUTURA_VITAL]]
A realidade é brutal: Se o Special Vdev morrer, você perde todo o pool. Imediatamente. Irreversivelmente. Não importa se seus HDDs de dados estão saudáveis em RaidZ3. Sem os metadados armazenados no Vdev especial, aqueles discos são apenas pesos de papel caros e ruidosos. Não existe zpool import -F que salve você dessa falha.
Para não destruir sua infraestrutura:
Redundância é Obrigatória: Nunca, sob nenhuma hipótese, configure um Special Vdev com um único SSD. Isso cria um ponto único de falha crítico. O mínimo absoluto é um Mirror (RAID1) de dois dispositivos. Se o pool principal tem alta redundância, o Special Vdev deve acompanhar.
Hardware Enterprise (PLP): Pare de economizar com SSDs "Gamer" ou de vitrine. A carga de metadados é composta por escritas pequenas e constantes. SSDs de consumo engasgam e morrem rápido sob esse estresse. O uso de drives com Power Loss Protection (PLP) é mandatório. Se a energia oscilar e o SSD mentir sobre a gravação dos metadados, seu sistema de arquivos corrompe.
Se o orçamento não permite redundância e hardware decente, não use Special Vdev. Aceite a latência dos HDDs. É melhor um pool lento do que um pool morto.

Marta G. Oliveira
DevOps Engineer & Storage Nerd
Automatiza provisionamento de storage com Terraform e Ansible. Defensora do 'Infrastructure as Code' para storage.