ZFS Special VDEVs: O Fim do Gargalo de IOPS (Sem Perder Dados)
Acelere pools de HDD movendo metadados para Flash. Entenda a arquitetura do ZFS Special VDEV, os riscos críticos de redundância e o tuning do special_small_blocks.
Você montou um array de armazenamento impressionante. Dezenas de Terabytes, discos de classe enterprise, um controlador HBA decente. Nos benchmarks de escrita sequencial (aquele dd que todo mundo adora rodar para inflar o ego), os números são lindos. Você vê 800MB/s, talvez 1GB/s.
Então você coloca o servidor em produção. Um diretório com 500.000 imagens pequenas, ou um servidor de e-mail, ou uma compilação de código. E de repente, seu monstro de armazenamento engasga. O comando ls -la demora 15 segundos para retornar. A latência dispara.
O que aconteceu? Você bateu no muro da física. Discos mecânicos (HDDs) são excelentes para throughput (vazão), mas patéticos para IOPS (operações por segundo). Um HDD de 7200 RPM entrega cerca de 80 a 120 IOPS aleatórios. Se você precisa ler metadados espalhados pelo disco para listar arquivos, a agulha do disco precisa se mover fisicamente. Isso é tempo. Isso é latência.
Durante anos, a solução era "mais RAM para o ARC" ou "adicione um L2ARC (cache)". Mas o cache precisa ser aquecido e, eventualmente, despejado.
A partir do OpenZFS 0.8, ganhamos uma arma cirúrgica: o Special VDEV (Allocation Class). Não é cache. É armazenamento preferencial. E se você não respeitar a arquitetura dele, ele vai destruir seus dados.
Vamos entender como isso funciona, como medir e como não cometer suicídio digital.
O Problema da Agulha no Palheiro
Para entender por que o Special VDEV é revolucionário, você precisa entender como o ZFS grava dados em discos rotativos.
Quando você grava um arquivo, o ZFS também grava metadados (ponteiros de bloco, permissões, timestamps, checksums). Em um pool convencional, esses metadados são misturados com os dados. Eles ficam espalhados pelos pratos dos discos.
Para ler um arquivo pequeno, o disco precisa:
Buscar o metadado (Seek mecânico 1).
Ler onde está o dado.
Buscar o dado (Seek mecânico 2).
Multiplique isso por mil arquivos e seu array está paralisado fazendo seeks, não transferindo dados. O throughput cai para KB/s.
A Arquitetura de Segregação (Não é Cache!)
O Special VDEV permite criar uma classe de dispositivos dedicada (geralmente SSDs NVMe rápidos) dentro do mesmo pool. O ZFS é instruído a interceptar tipos específicos de dados — principalmente metadados e blocos pequenos — e gravá-los fisicamente apenas nos SSDs, enquanto os blocos grandes de dados continuam indo para os HDDs baratos.
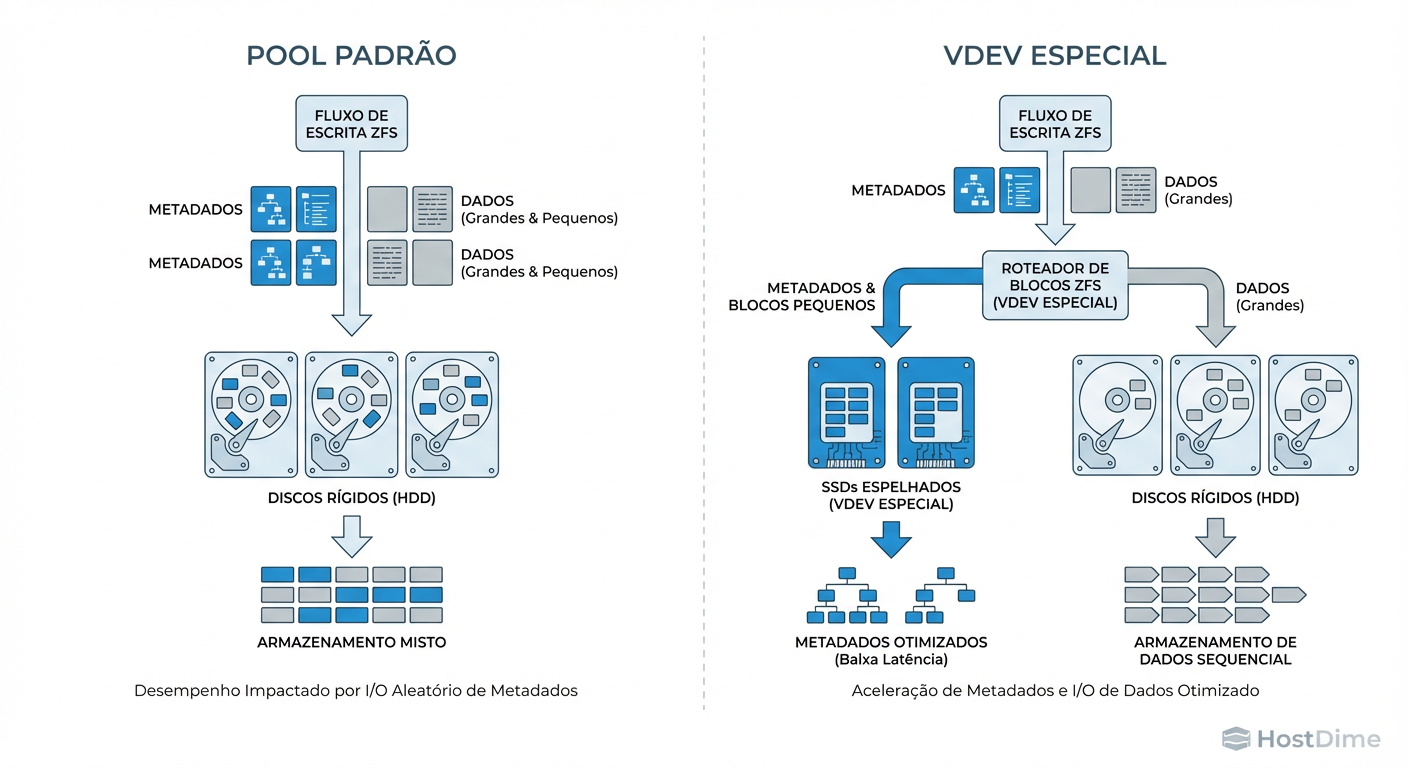 Figura: Fluxo de Alocação: O Special VDEV intercepta fisicamente metadados e blocos pequenos, impedindo que eles fragmentem o array mecânico.
Figura: Fluxo de Alocação: O Special VDEV intercepta fisicamente metadados e blocos pequenos, impedindo que eles fragmentem o array mecânico.
A diferença fundamental para o L2ARC ou SLOG é que o Special VDEV é parte integrante da estrutura de dados.
L2ARC (Cache de Leitura): Se o SSD morrer, você perde o cache. O sistema fica lento, mas os dados estão seguros nos HDDs.
Special VDEV (Storage Tiering): Se o SSD morrer, você perde os metadados. Se você perde os metadados, você perde o arquivo. Se você perde o Special VDEV inteiro, você perde o pool inteiro.
A Matemática da Sobrevivência (Redundância)
Aqui é onde vejo administradores cometerem erros fatais. A empolgação de "acelerar o pool" faz com que coloquem um único NVMe consumer-grade como Special VDEV em frente a um array RAIDZ2 de 8 discos.
Isso é um suicídio estatístico.
Pense na confiabilidade do seu pool como uma corrente. A força da corrente é definida pelo elo mais fraco.
Seus dados (HDDs) suportam a falha de 2 discos (RAIDZ2).
Seus metadados (Special VDEV Single) não suportam nenhuma falha.
Se esse único NVMe falhar, seu array de 100TB torna-se um peso de papel criptografado. O ZFS não consegue montar o pool sem os metadados.
A Regra de Ouro da Redundância
A redundância do Special VDEV deve igualar ou exceder a redundância dos vdevs de dados.
| Configuração de Dados (HDDs) | Configuração Mínima do Special (SSDs) | Nível de Paranoia |
|---|---|---|
| Stripe (Sem redundância) | Stripe (1 SSD) | Baixo (Dados descartáveis) |
| Mirror (Espelhamento) | Mirror (2 SSDs) | Padrão |
| RAIDZ1 | Mirror (2 SSDs) | Aceitável |
| RAIDZ2 | 3-way Mirror (3 SSDs) | Recomendado (Enterprise) |
| RAIDZ3 | 3-way Mirror (3 SSDs) | Obrigatório |
Nota: Special VDEVs usam espelhamento (Mirror), não RAIDZ. O overhead de paridade do RAIDZ em blocos pequenos (4k/8k) destrói a performance e a eficiência de espaço (amplificação de escrita), anulando o benefício do SSD. Use Mirrors.
O Botão Mágico: special_small_blocks
Por padrão, ao adicionar um Special VDEV, o ZFS move apenas os metadados para lá. Isso já acelera operações de diretório (ls, find), scrub e resilvering.
Mas o verdadeiro ganho de performance para bancos de dados, VMs e servidores de arquivos vem com a propriedade special_small_blocks.
Esta configuração diz ao ZFS: "Qualquer bloco físico menor ou igual a X deve ser gravado no SSD, não no HDD."
# Exemplo: Jogar metadados E arquivos/blocos menores que 32K para o SSD
zfs set special_small_blocks=32K tank/minha-dataset
Isso elimina o "IOPS Penalty" dos HDDs. Arquivos de texto, logs pequenos, e thumbnails vão para o flash. Arquivos de vídeo e ISOs vão para o disco rotativo.
O Perigo do Excesso
Não seja ganancioso. Se você definir special_small_blocks=1M, você estará jogando quase tudo para o SSD. Seus SSDs vão encher rápido, e quando o Special VDEV enche, os dados transbordam de volta para os HDDs (o que é seguro, mas perde a performance).
Você precisa encontrar o "joelho da curva". Onde está o maior ganho de IOPS com o menor custo de capacidade?
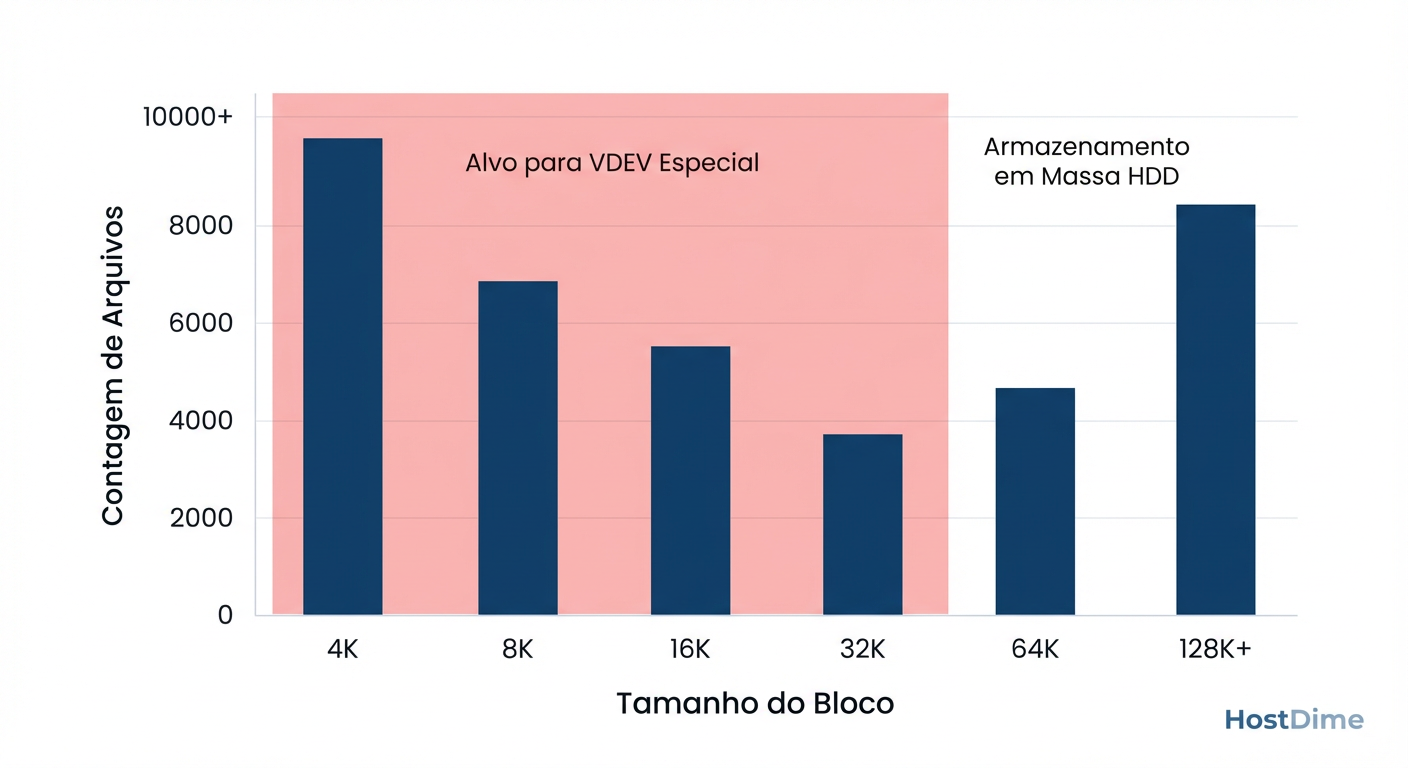 Figura: A Curva de Eficiência: Identificando o 'ponto de corte' ideal para o
Figura: A Curva de Eficiência: Identificando o 'ponto de corte' ideal para o special_small_blocks. Jogar blocos de 128K no SSD é desperdício; focar em 4K-32K é onde o ganho de IOPS brilha.
Dimensionamento Pragmático: Use o zdb
Não adivinhe o tamanho dos SSDs que você precisa comprar. Meça seus dados atuais. O comando zdb é a ferramenta de diagnóstico baixo-nível do ZFS. Ele pode varrer seus metadados e dizer exatamente a distribuição de tamanho dos blocos.
Se você já tem dados no pool, execute isto para simular quanto espaço você precisaria:
# -L: não resolva caminhos (mais rápido)
# -b: estatísticas de blocos
# -bbbs: super detalhado
# tank: nome do seu pool
zdb -Lbbbs tank
A saída será longa. Procure pela tabela final, parecida com esta (simplificada):
Block Size Histogram
block psize lsize asize
size Count Size Cum. Count Size Cum. Count Size Cum.
512: 15k 7.5M 7.5M 15k 7.5M 7.5M 0 0 0
1K: 42k 42M 50M 42k 42M 50M 0 0 0
2K: 12k 24M 74M 12k 24M 74M 0 0 0
4K: 1.2M 4.8G 4.9G 1.2M 4.8G 4.9G 1.1M 4.5G 4.5G
8K: 50k 400M 5.3G 50k 400M 5.3G 60k 500M 5.0G
16K: 20k 320M 5.6G 20k 320M 5.6G 25k 400M 5.4G
32K: 10k 320M 5.9G 10k 320M 5.9G 12k 384M 5.8G
...
Análise:
Olhe para a coluna
asize(Allocated Size) eCum.(Cumulative).Se você definir
special_small_blocks=4K, você precisará de espaço para todos os blocos de 512B a 4K.No exemplo acima, até 4K temos cerca de 4.5GB. Até 32K, temos 5.8GB.
Some a isso o tamanho dos metadados (geralmente 0.1% a 0.3% da capacidade total do pool, mas o
zdbtambém informa isso especificamente na seção "L1, L2... object arrays").
Cálculo de Compra:
(Tamanho dos Metadados + Tamanho dos Blocos Pequenos Escolhidos) * 2 (Margem de Segurança)
Por que margem de segurança de 2x?
O ZFS usa Copy-on-Write. Se o disco estiver 90% cheio, a performance degrada e a fragmentação aumenta.
Metadados crescem com o tempo.
Você não quer ter que trocar esses SSDs daqui a 6 meses.
Métricas de Sucesso: Provando o Valor
Você instalou os SSDs, configurou o espelhamento e ajustou o special_small_blocks. Como saber se funcionou?
Use o zpool iostat com a flag -v (verbose) para ver o tráfego por vdev.
# Monitorar a cada 2 segundos
zpool iostat -v tank 2
Você verá algo assim:
capacity operations bandwidth
pool alloc free read write read write
---------- ----- ----- ----- ----- ----- -----
tank 140T 60T 450 120 500M 80M
mirror-0 ... ... 20 10 40M 60M
mirror-1 ... ... 20 10 40M 60M
special
mirror-2 200G 800G 410 100 420M 20M
O que procurar:
Operations (IOPS): Note como a seção
special(mirror-2) está absorvendo a vasta maioria das operações de leitura (410 de 450).Bandwidth: Os HDDs (mirror-0, mirror-1) estão lidando com menos operações, mas provavelmente com blocos maiores (se houver streaming).
Se você vir os contadores de IOPS dos HDDs caindo perto de zero enquanto o Special VDEV trabalha duro, parabéns. Você acabou de transformar seu array barulhento em algo que responde como um array All-Flash para a maioria das interações humanas e de banco de dados.
Veredito Técnico: Use com Respeito
Special VDEVs são a ferramenta mais poderosa no arsenal moderno do ZFS para performance. Eles resolvem o problema físico da latência de busca em discos mecânicos. Mas eles exigem respeito.
Não trate como cache. Trate como a joia da coroa dos seus dados. Dimensione corretamente, use espelhamento de qualidade e monitore o desgaste (TBW) desses SSDs, pois eles vão apanhar bastante. Feito certo, você estende a vida útil do seu armazenamento mecânico por anos. Feito errado, você tem um desastre esperando para acontecer.

Priya Patel
Data Center Operations Lead
Gerencia milhares de discos físicos. Sabe exatamente qual modelo de HDD vibra mais e qual SSD morre primeiro.