ZFS vs MDADM vs Hardware RAID: A Batalha do NVMe e o Custo do Rebuild

Análise forense do impacto em CPU e latência entre ZFS, MDADM e Hardware RAID em arrays NVMe. Descubra quem sobrevive a um rebuild sem travar seu servidor.
Você recebe o chamado às 3 da manhã. O banco de dados está engasgando, a latência de disco disparou para 50ms, mas os discos NVMe novos em folha mostram apenas 20% de utilização. O sintoma é claro: o storage está lento. Mas a causa raiz raramente é o disco em si. Na era do HDD, o disco era sempre o culpado. Na era do NVMe, o culpado geralmente é a camada de software que tenta gerenciá-lo.
Como investigador forense de sistemas, aprendi que abstrações têm um custo. Quando você empilha camadas de proteção (RAID) sobre hardware extremamente rápido (NVMe), a física do sistema muda. O gargalo sai do prato magnético e sobe para o barramento PCIe e para a CPU.
Este artigo é uma autópsia das três principais arquiteturas de redundância de armazenamento modernas, dissecando onde cada uma falha quando submetida à pressão de gigabytes por segundo.
O que define a escolha da Arquitetura de Storage?
A escolha entre ZFS, MDADM e Hardware RAID para NVMe depende fundamentalmente de onde você aceita ter o gargalo: na CPU ou no Controlador. Enquanto o Hardware RAID offloada o cálculo de paridade para um chip dedicado (que se torna um funil em velocidades NVMe), o ZFS e o MDADM utilizam a CPU do host. O ZFS troca ciclos de CPU e latência por integridade absoluta dos dados (checksums), enquanto o MDADM prioriza a velocidade bruta com menor sobrecarga, mas com reconstruções (rebuilds) ineficientes.
O Paradigma NVMe: Quando o Gargalo vira a CPU
Para entender o crime, precisamos examinar a cena. Um HDD SAS de 15k RPM entrega cerca de 200 IOPS. Um SSD NVMe moderno entrega facilmente 500.000 IOPS. A diferença não é apenas de escala; é de natureza.
Antigamente, a CPU passava a maior parte do tempo em I/O Wait, esperando o disco girar. Com NVMe, o disco responde tão rápido que a CPU mal tem tempo de trocar de contexto. Se você insere uma camada de RAID no meio, cada operação de escrita exige cálculo de paridade, alocação de memória e bloqueio de interrupções.
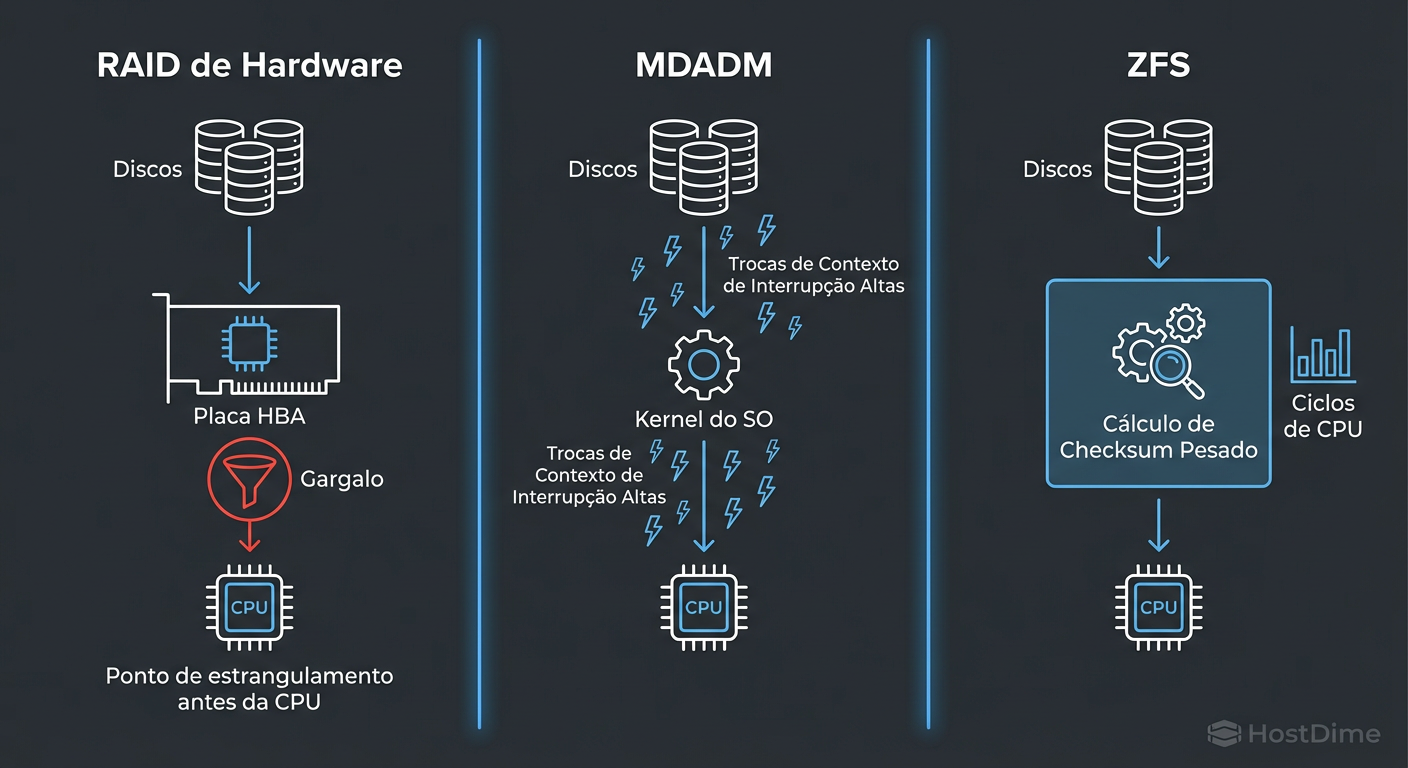 Figura: O Caminho do I/O: Onde a latência é introduzida em cada arquitetura de armazenamento.
Figura: O Caminho do I/O: Onde a latência é introduzida em cada arquitetura de armazenamento.
A imagem acima ilustra o caminho crítico. Em arranjos NVMe, a latência introduzida pelo software (ou pelo controlador RAID) frequentemente excede a latência da própria mídia. O "custo" de proteger seus dados agora é medido em ciclos de processador, não em milissegundos de rotação.
A Morte Lenta do Hardware RAID em Cenários Flash
Durante décadas, o Hardware RAID (placas PERC, MegaRAID, etc.) foi o padrão ouro. Ele oferecia um cache com bateria (BBU) e retirava a carga de cálculo de paridade (XOR) da CPU principal.
No entanto, em uma investigação forense de performance, o Hardware RAID em NVMe é frequentemente o principal suspeito. Por quê?
O Limite do ASIC: O processador da placa RAID tem um limite de largura de banda (throughput). Uma placa RAID topo de linha pode gerenciar 12GB/s. Dois drives NVMe Gen4 em RAID 0 já saturam isso. A placa, que deveria acelerar, vira um freio.
A Caixa Preta: Quando um array de Hardware RAID corrompe, você está à mercê do suporte do fabricante e de ferramentas proprietárias. Não há
dmesgouzpool statusque lhe diga exatamente qual setor falhou e por quê.Queue Depth: Drives NVMe suportam filas de comando massivas (64k filas com 64k comandos). Controladoras RAID antigas ou mal otimizadas afunilam isso em filas únicas ou limitadas, matando o paralelismo do protocolo NVMe.
Veredito Forense: Use Hardware RAID apenas para HDDs rotacionais ou para o disco de boot (OS) se precisar de simplicidade. Para dados em NVMe, ele é um gargalo arquitetural.
MDADM (Linux RAID): Eficiência do Kernel vs. Rebuild "Burro"
O mdadm é o operário padrão do Linux. Ele roda em kernel space, é extremamente leve e, ao contrário do ZFS, não tenta ser um sistema de arquivos; ele é apenas um gerenciador de blocos.
A Vantagem da Latência
Por ser simples, o MDADM adiciona pouquíssima latência. Ele pega o I/O, calcula o XOR (usando instruções AVX da CPU, que são rapidíssimas hoje em dia) e despacha para o disco. Em testes de performance pura de escrita sequencial, o MDADM geralmente vence o ZFS e o Hardware RAID em arrays NVMe.
O "Crime" do MDADM: O Sync Cego
O problema do MDADM aparece quando algo quebra. Digamos que você tem um RAID 5 de 10TB, mas apenas 100GB de dados gravados. Um disco falha. Você insere um novo.
O MDADM não sabe o que é "arquivo" e o que é "espaço vazio". Ele opera em nível de bloco.
O Processo: Ele vai ler os 10TB inteiros dos discos restantes, calcular a paridade e escrever 10TB no disco novo.
O Resultado: Um rebuild que demora horas (ou dias em HDDs), estressando os discos restantes ao máximo, para sincronizar 9.9TB de zeros inúteis.
Isso não é apenas ineficiente; é perigoso. Durante o rebuild, a performance do array cai drasticamente e o risco de falha de um segundo disco (URE - Unrecoverable Read Error) aumenta estatisticamente com a quantidade de dados lidos.
ZFS e o Custo da Integridade: Checksums a 7GB/s
O ZFS não confia no hardware. Ele assume que o disco vai mentir, que o cabo vai corromper bits e que o controlador vai falhar. Por isso, ele calcula um checksum para cada bloco de dados gravado e o verifica a cada leitura.
O Imposto da CPU (ZFS Tax)
Calcular checksums (como Fletcher4 ou SHA-256) para fluxos de dados de 7GB/s ou mais custa caro. Em arrays NVMe rápidos, é comum ver um núcleo de CPU saturado apenas gerenciando o ZFS.
Se você observar o top durante um teste de carga em ZFS com NVMe, verá processos como z_wr_iss ou z_rd_int consumindo tempo considerável.
A Vantagem Forense: Self-Healing
Apesar do custo, o ZFS oferece algo que nem o MDADM nem o Hardware RAID possuem: a garantia de que o dado lido é o dado gravado.
Cenário: Um bit vira ("bit rot") em um dos discos.
MDADM/HW RAID: Entregam o dado corrompido para a aplicação. Você só descobre quando o banco de dados falha ao abrir a tabela.
ZFS: Detecta que o checksum não bate, lê a cópia de paridade/espelho, corrige o dado em voo, entrega o dado correto para a aplicação e repara o bloco no disco defeituoso. Tudo transparente.
Anatomia de um Rebuild: Resilver (ZFS) vs Sync (MDADM)
Aqui reside a maior diferença operacional para quem mantém sistemas em produção. O tempo de recuperação é a métrica mais crítica quando você está operando em modo degradado.
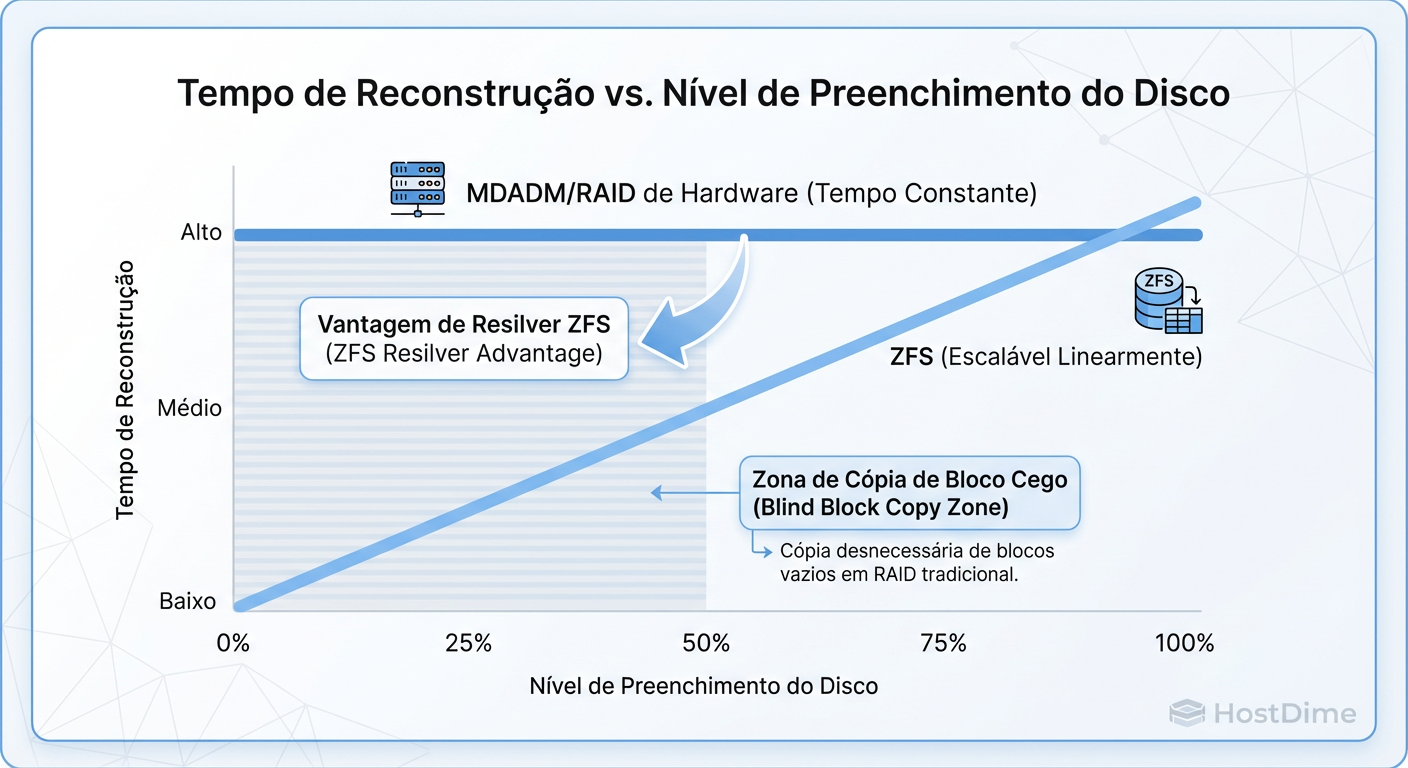 Figura: Comparativo de Tempo de Rebuild: ZFS Resilver vs MDADM Sync em relação ao uso do disco.
Figura: Comparativo de Tempo de Rebuild: ZFS Resilver vs MDADM Sync em relação ao uso do disco.
ZFS Resilver: Cirúrgico
O ZFS conhece a árvore de metadados. Se você tem um pool de 10TB com 100GB de dados:
Ele navega pela árvore de dados ativos.
Copia apenas os 100GB que realmente existem.
Ignora o espaço vazio.
Resultado: O rebuild (chamado de resilver) termina em minutos, não horas. O estresse nos discos sobreviventes é fracionário comparado ao MDADM.
MDADM Sync: Força Bruta
Como mencionado, o MDADM fará a sincronização linear de todo o dispositivo de bloco. Em SSDs grandes (ex: 8TB ou 16TB), isso gera um ciclo de escrita massivo que consome a vida útil (TBW) do SSD desnecessariamente.
Trade-offs Reais: Tabela Comparativa
A decisão não é sobre qual é "melhor", mas qual problema você quer resolver.
| Característica | Hardware RAID | MDADM (Linux RAID) | ZFS (OpenZFS) |
|---|---|---|---|
| Gargalo em NVMe | Controlador RAID (Alto) | CPU (Baixo) | CPU (Médio/Alto) |
| Integridade de Dados | Confia no Disco | Confia no Disco | Checksum End-to-End |
| Eficiência de Rebuild | Baixa (Sync Total) | Baixa (Sync Total) | Alta (Apenas Dados Ativos) |
| Portabilidade | Baixa (Proprietário) | Alta (Qualquer Linux) | Alta (Cross-platform) |
| Uso de RAM | Baixo (Cache na placa) | Baixo | Alto (ARC Cache) |
| Complexidade | Baixa ("Plug & Play") | Média | Alta (Tuning necessário) |
Metodologia de Teste: Como validar seu Storage
Não acredite na folha de especificações. Como investigador, você precisa de provas. Antes de colocar um array NVMe em produção, execute testes que simulem a carga real e o pior cenário.
1. Teste de Stress de I/O (FIO)
Não use dd. O dd é single-threaded e enganoso. Use fio para gerar profundidade de fila.
# Simulação de Banco de Dados (Random Read/Write 70/30)
# Atenção: Isso vai estressar seus discos.
fio --name=db_test --ioengine=libaio --rw=randrw --rwmixread=70 \
--bs=8k --numjobs=4 --iodepth=32 --size=10G --runtime=60 \
--time_based --filename=/caminho/para/mountpoint/teste.dat --group_reporting
O que medir:
IOPS: O número total.
lat (ms): Latência média e, mais importante, o percentil 99 (p99). O ZFS tende a ter p99 mais alto se não estiver bem ajustado (devido a transações TXG).
2. Teste de Rebuild em Carga
O teste que ninguém faz, mas que salva empregos:
Inicie o teste
fioacima.Enquanto o teste roda, remova fisicamente (ou via software) um disco do array.
Meça a queda de IOPS.
Insira um disco novo e inicie o rebuild.
Meça o tempo até a conclusão e o impacto na latência durante o processo.
Se o seu sistema trava ou a latência sobe para segundos durante o passo 4, sua arquitetura falhou, não importa quão rápido seja o NVMe.
Veredito Técnico Investigativa
Na batalha do NVMe:
Hardware RAID é um suspeito obsoleto. Ele introduz latência e pontos de falha proprietários que não compensam mais.
MDADM é o corredor de velocidade. Se você precisa de IOPS brutos e seu banco de dados já lida com integridade (e você tem backups rápidos), é uma escolha válida e leve.
ZFS é o tanque de guerra. Ele vai consumir mais CPU e pode ter uma latência de escrita ligeiramente maior, mas a eficiência do resilver e a garantia de integridade dos dados o tornam a escolha superior para armazenamento de longo prazo e virtualização crítica.
Decisão Final: Em sistemas modernos com CPUs multicore sobrando, o custo de CPU do ZFS é um preço barato a se pagar para não ter que acordar às 3 da manhã com um rebuild de RAID que nunca termina.
Referências & Leitura Complementar
OpenZFS Documentation: ZFS Architecture and Performance Tuning.
Linux Kernel Documentation: Software RAID (md) and optimizations.
NVMe Specification (NVM Express): Base Specification 2.0 - Queue Management.
Gregg, Brendan: Systems Performance: Enterprise and the Cloud, 2nd Edition (Capítulo 9 e 10).
RFC 3720: Internet Small Computer Systems Interface (iSCSI) - Considerações sobre latência em bloco.

Marta G. Oliveira
DevOps Engineer & Storage Nerd
Automatiza provisionamento de storage com Terraform e Ansible. Defensora do 'Infrastructure as Code' para storage.