ZFS Vs RAID Tradicional Diferencas Conceituais
RAID te protege de falha de disco. ZFS te protege de *corrupção* de dados. Entenda a diferença, ou prepare-se para noites em claro....
ZFS Vs RAID Tradicional Diferencas Conceituais
RAID te protege de falha de disco. ZFS te protege de corrupção de dados. Entenda a diferença, ou prepare-se para noites em claro.
O RAID tradicional, em sua essência, é uma forma de espelhar ou distribuir dados entre múltiplos discos para aumentar a disponibilidade e/ou performance. Mas ele foi projetado em uma época onde a densidade dos discos era baixa e a corrupção de dados era considerada um evento raro. Hoje, com discos de 20TB+, a história é bem diferente.
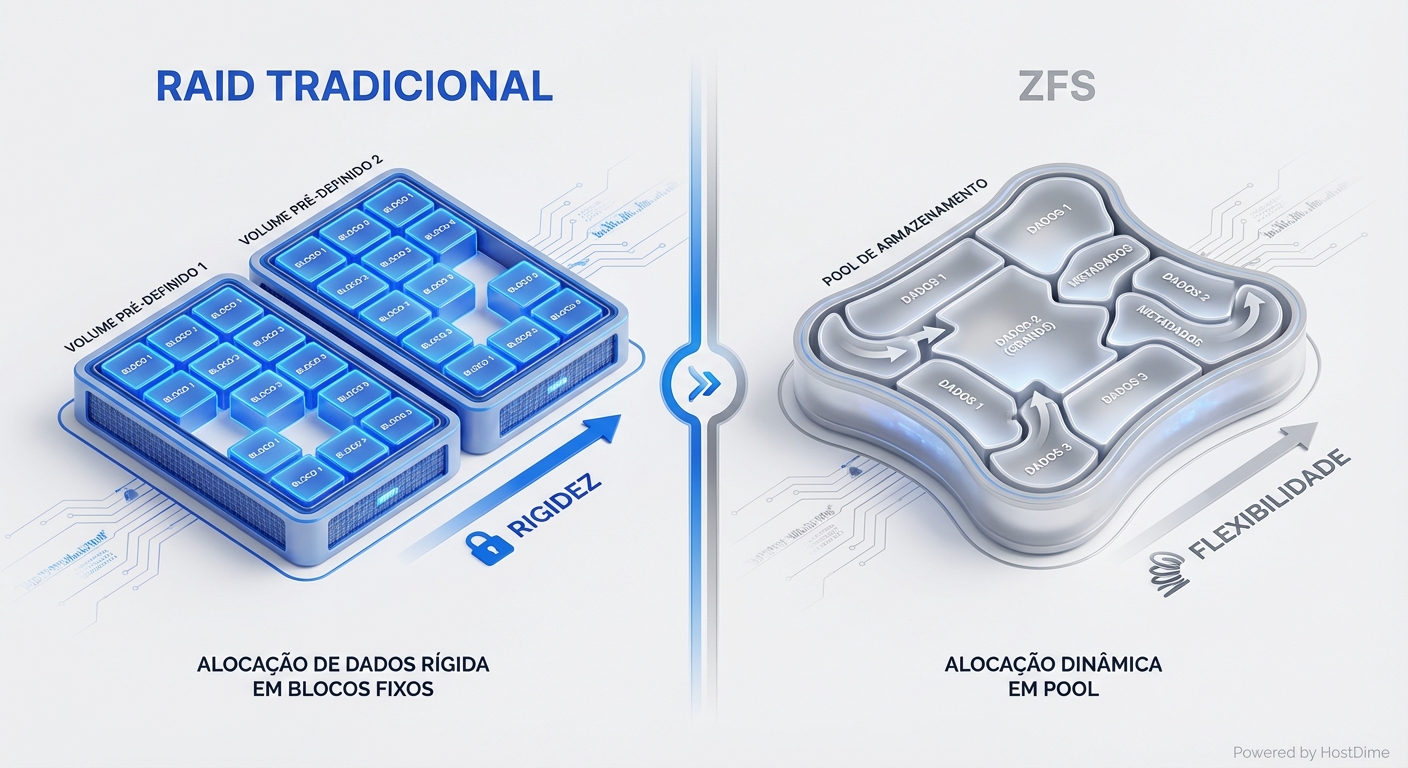
A primeira grande diferença está na alocação de dados. RAID tradicional trabalha com blocos de tamanho fixo, pré-alocados em volumes. ZFS, por outro lado, usa alocação dinâmica dentro de um pool de armazenamento. Isso significa que o ZFS pode usar o espaço de forma muito mais eficiente e flexível, adaptando-se às necessidades do momento. RAID, por ser rígido, pode levar à fragmentação e desperdício de espaço.
O Problema do "Write Hole" e a Vantagem do Copy-on-Write
Imagine a seguinte situação: você está escrevendo dados em um volume RAID 5. Um disco falha durante a escrita. O RAID tenta reconstruir os dados usando a paridade, mas a informação está incompleta. Resultado: dados corrompidos, sem que o RAID sequer perceba. Isso é o "write hole".
ZFS resolve isso com uma arquitetura copy-on-write. Em vez de sobrescrever os dados diretamente, o ZFS escreve as modificações em um novo bloco e, somente depois de verificar a integridade da nova escrita, atualiza os metadados para apontar para o novo bloco. Se algo der errado durante a escrita, os dados antigos permanecem intactos.
Checksums: A Arma Secreta Contra a Corrupção Silenciosa
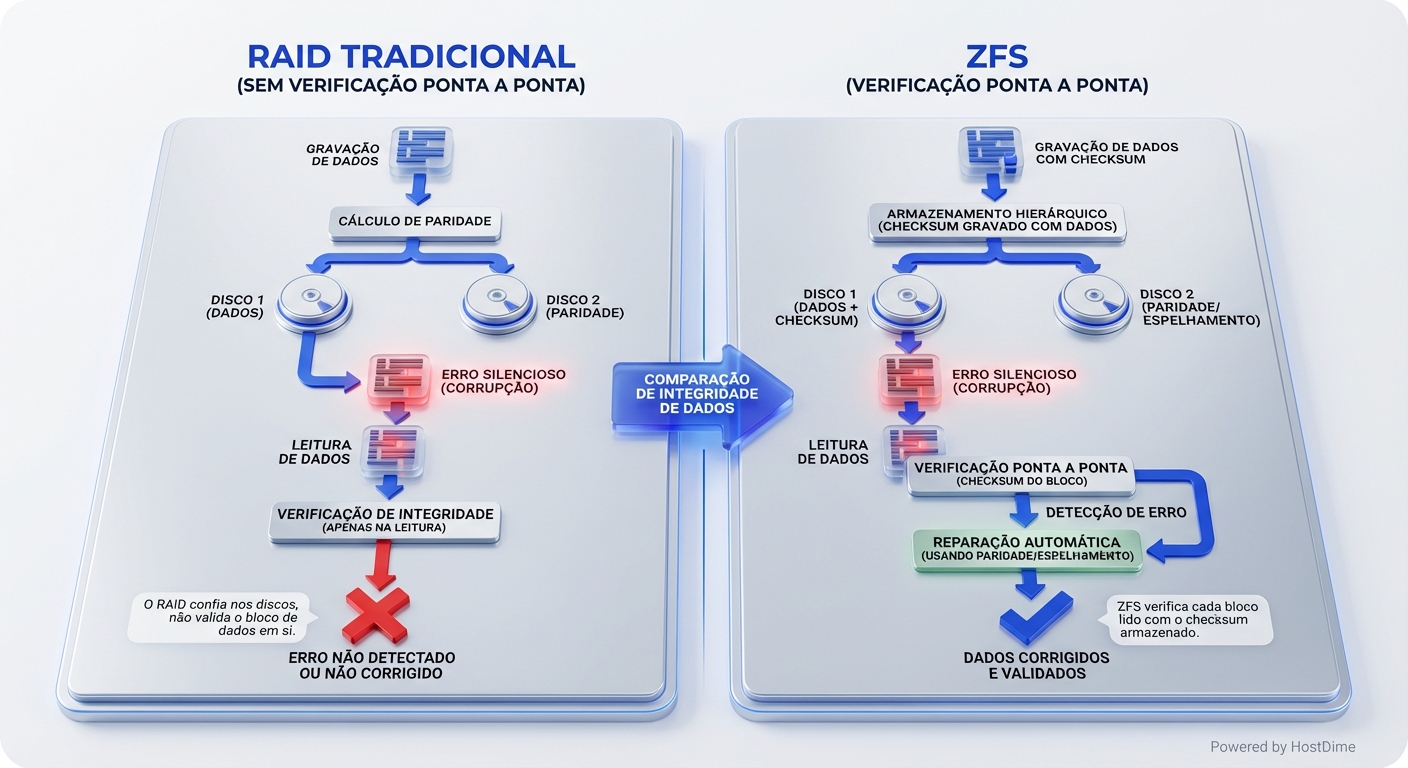
Discos modernos são densos e complexos. Erros de leitura/escrita podem acontecer sem que o hardware reporte nada. Bit flips, setores corrompidos... o estrago pode ser silencioso e devastador. É a chamada "corrupção silenciosa" (silent data corruption).
RAID tradicional não detecta corrupção de dados. Ele assume que os dados lidos do disco estão corretos. ZFS, por outro lado, calcula um checksum (uma espécie de "impressão digital") de cada bloco de dados. Quando o ZFS lê um bloco, ele recalcula o checksum e compara com o valor armazenado. Se os valores não coincidirem, o ZFS sabe que houve corrupção e pode, dependendo da configuração (espelhamento, RAIDZ), corrigir o erro usando as cópias redundantes dos dados.
O Que Acontece Quando um Disco Falha?
RAID: Inicia-se a reconstrução dos dados no disco substituto. Durante esse processo, a performance do sistema é severamente impactada. Além disso, quanto maior o disco, maior a probabilidade de um erro de leitura não recuperável (Unrecoverable Read Error - URE) durante a reconstrução. Se isso acontecer, adeus volume.
ZFS: Também inicia a reconstrução, mas com algumas vantagens cruciais. Primeiro, ele só lê os blocos necessários para a reconstrução, não o disco inteiro. Segundo, se encontrar um erro de checksum durante a leitura, ele tenta corrigir usando as cópias redundantes. Terceiro, a arquitetura copy-on-write minimiza o risco de corrupção adicional durante a reconstrução.
ZFS Salva Vidas (e Dados): Cenários Reais
- Bit Rot em Arquivos Mortos: Um servidor de arquivos com dados arquivados por anos. Com RAID, a corrupção silenciosa se acumularia, tornando os arquivos inúteis. ZFS detectaria e corrigiria a corrupção, garantindo a integridade dos dados a longo prazo.
- Falha de Disco Durante Reconstrução: Um array RAID 5 com discos de 16TB. A probabilidade de um URE durante a reconstrução é altíssima. ZFS, com RAIDZ2 ou RAIDZ3, aguentaria múltiplas falhas e ainda manteria os dados íntegros.
- Sistema de Arquivos Corrompido: Um banco de dados com arquivos corrompidos devido a um bug no sistema operacional. RAID não detectaria a corrupção. ZFS, com seus checksums, alertaria sobre o problema e permitiria restaurar os dados a partir de um snapshot.
ZFS Não É Bala de Prata: Onde Ele Não Te Salva
- Falha de Energia: Se a energia cair durante uma escrita, mesmo o ZFS pode perder dados. Invista em um bom UPS (Uninterruptible Power Supply).
- Erro Humano: ZFS não te protege de comandos
rm -rf /. Tenha backups! - Bugs no ZFS: Sim, eles existem. Mantenha o ZFS atualizado e teste as atualizações em um ambiente de homologação.
- Falta de Memória: ZFS usa a RAM como cache. Se a RAM for insuficiente, a performance cai drasticamente.
Diagnóstico: Comandos Essenciais
zpool status: Mostra o estado do pool, erros, discos degradados. Olhe para isso diariamente.zpool scrub <pool>: Inicia uma verificação completa do pool, procurando por erros de checksum. Agende isso semanalmente.smartctl -a /dev/sda: Mostra os dados SMART do disco, como temperatura, horas de uso, erros de leitura/escrita. Use para monitorar a saúde dos discos.iostat -xz 1: Monitora a atividade de I/O dos discos. Use para identificar gargalos.
Veredito
RAID é bom para disponibilidade básica. ZFS é para integridade de dados. Se seus dados são importantes, use ZFS. Se você ainda usa RAID 5/6 com discos de alta capacidade, prepare-se para o desastre. A complexidade adicional do ZFS vale a pena a tranquilidade que ele oferece. Use RAIDZ2/RAIDZ3 para tolerância a múltiplas falhas. E, pelo amor de tudo que é sagrado, faça backups.

Marta G. Oliveira
DevOps Engineer & Storage Nerd
Automatiza provisionamento de storage com Terraform e Ansible. Defensora do 'Infrastructure as Code' para storage.