Acelerando ZFS com Special VDEVs: O guia de engenharia para armazenamento híbrido

Desvende a arquitetura dos Special VDEVs no ZFS. Aprenda a eliminar a latência de metadados em discos rotacionais e otimize IOPS segregando blocos pequenos em NVMe.
A latência é o assassino silencioso da infraestrutura. Enquanto arquitetos desenham diagramas de throughput em gigabytes por segundo, o engenheiro de kernel sabe que a batalha real acontece no nível dos microssegundos. Cada vez que a CPU precisa esperar um braço mecânico se mover fisicamente sobre um prato magnético para ler um ponteiro de metadados, ciclos de clock são desperdiçados e filas de I/O (Input/Output) explodem.
No universo do ZFS, um sistema de arquivos copy-on-write transacional, a integridade dos dados tem um custo computacional e físico. A estrutura de árvore de Merkle, que garante que seus dados nunca corrompam silenciosamente, exige leituras adicionais. Em discos rígidos rotacionais (HDDs), isso se traduz em seeks — o movimento físico mais lento em toda a computação moderna. A introdução dos Special VDEVs (Allocation Classes) no OpenZFS 0.8 mudou fundamentalmente essa equação, permitindo segregar a lógica (metadados) da massa (dados) em mídias fisicamente distintas.
Não estamos falando de cache. Estamos falando de arquitetura de armazenamento híbrido determinística.
Resumo em 30 segundos
- O Gargalo: Discos rotacionais (HDDs) são limitados pela física a ~100 IOPS aleatórios; o ZFS exige múltiplas leituras aleatórias de metadados para acessar um único arquivo.
- A Solução: Special VDEVs não são cache (L2ARC). Eles são vdevs de armazenamento primário dedicados a metadados e blocos pequenos, forçando esse I/O crítico para flash (SSD/NVMe).
- O Resultado: A latência de navegação em diretórios e scrubs cai drasticamente, pois os HDDs ficam livres para fazer o que fazem melhor: leituras e escritas sequenciais.
A tirania da física e o custo dos seeks
Para entender por que o ZFS "parece lento" em arrays puramente mecânicos ao lidar com milhões de arquivos pequenos, precisamos olhar para o tempo de serviço do disco. Um HDD de 7200 RPM tem uma latência rotacional média de 4,16 ms e um tempo médio de busca (seek time) de 8 a 9 ms.
Somando o overhead do controlador e o tempo de transferência, um único I/O aleatório custa cerca de 12 a 15 milissegundos. Em um segundo, você tem um orçamento físico de aproximadamente 80 a 100 operações (IOPS). Se o seu sistema de arquivos precisa ler três blocos de metadados espalhados pelo disco para encontrar o endereço do seu arquivo, você acabou de gastar 45 ms apenas para começar a ler o dado.
Para uma CPU moderna operando em gigahertz, 45 milissegundos é uma eternidade. É tempo suficiente para o processador fazer milhões de cálculos e entrar em estado de espera (iowait), travando a thread da aplicação.
A estrutura de árvore do ZFS e o pesadelo dos blocos indiretos
O ZFS não é apenas um sistema de arquivos; é um gerenciador de volume com consciência da estrutura de dados. Tudo no ZFS é uma árvore de objetos. No topo, temos o Uberblock. Abaixo dele, o MOS (Meta Object Set), e descendo a hierarquia, chegamos aos dnodes (nós de dados) e blocos indiretos.
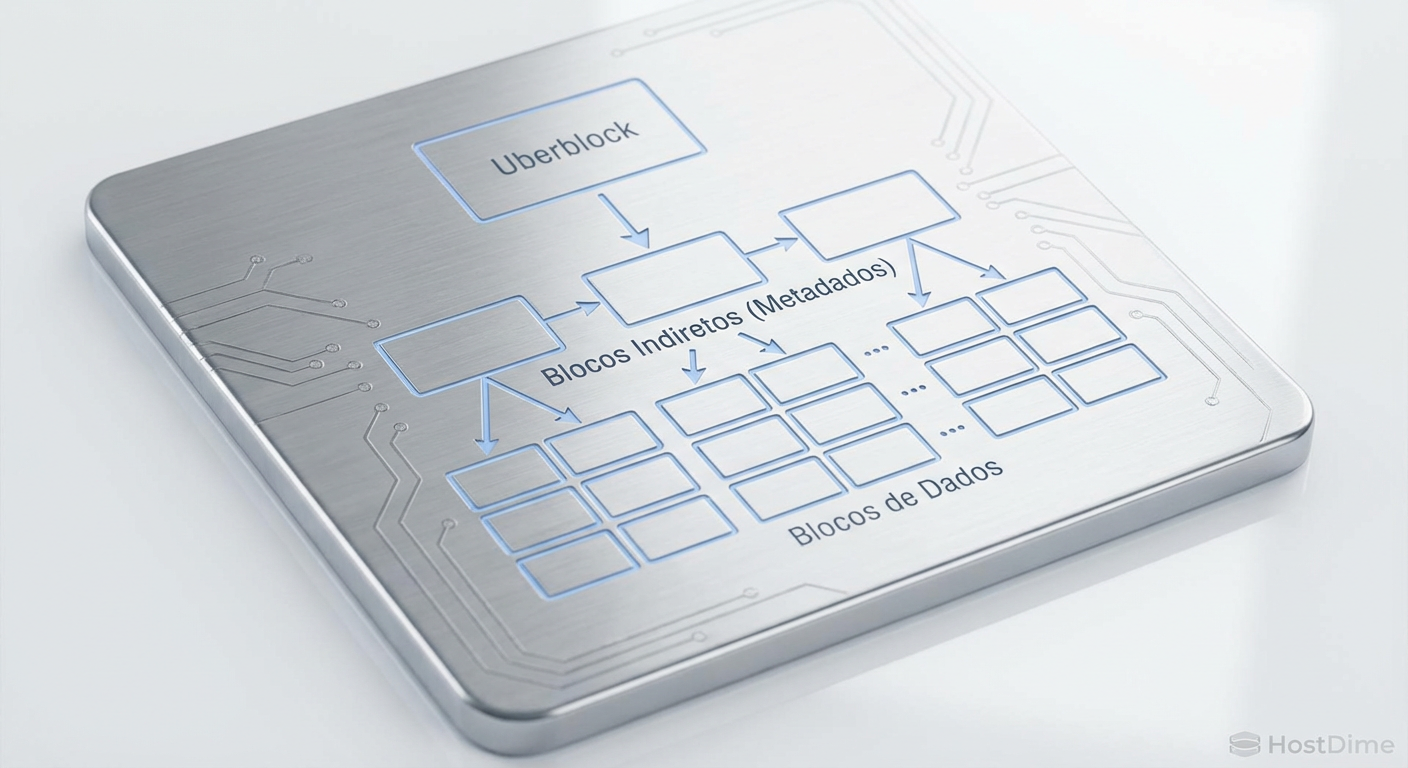 Fig. 1: A árvore de Merkle do ZFS. Para ler um dado, o disco precisa buscar e ler múltiplos níveis de metadados antes.
Fig. 1: A árvore de Merkle do ZFS. Para ler um dado, o disco precisa buscar e ler múltiplos níveis de metadados antes.
Quando você solicita a leitura de um arquivo, o ZFS não vai direto ao endereço LBA (Logical Block Addressing) do dado. Ele precisa:
Ler o diretório pai.
Ler o dnode do arquivo para obter os ponteiros de bloco.
Se o arquivo for grande ou fragmentado, ler um ou mais níveis de blocos indiretos (L1, L2, L3...).
Finalmente, ler o bloco de dados.
Em um pool composto apenas por HDDs, cada um desses passos (1, 2 e 3) é um seek aleatório. O braço do disco fica "dançando" sobre o prato apenas para descobrir onde o dado está. Isso é conhecido como amplificação de leitura de metadados. Em cargas de trabalho como servidores de e-mail, compilação de código ou bancos de dados, o disco passa mais tempo buscando metadados do que transferindo payload útil.
Por que o L2ARC não resolve o gargalo
Muitos administradores tentam mitigar isso adicionando um SSD como L2ARC (Level 2 Adaptive Replacement Cache). Embora ajude, o L2ARC tem falhas arquiteturais para esse problema específico:
Natureza Volátil: O L2ARC precisa ser "aquecido". Ao reiniciar o servidor, o cache está frio e você volta à performance nativa dos HDDs até que os dados sejam lidos novamente. (Embora o Persistent L2ARC tenha melhorado isso, a reconstrução do mapa de memória ainda leva tempo).
Custo de RAM: Para indexar o L2ARC, o ZFS consome RAM do ARC principal. Se você adicionar um L2ARC massivo, você pode, ironicamente, reduzir o tamanho do seu cache primário (ARC), piorando a performance geral.
Evicção: O L2ARC é um cache de anel. Se sua carga de trabalho de leitura for maior que o cache, metadados vitais serão expulsos, forçando leituras lentas no HDD.
O Special VDEV elimina a incerteza. Ele não é um cache; é o local de armazenamento permanente e autoritativo para os tipos de dados que você definir.
A arquitetura dos allocation classes
Introduzido no OpenZFS 0.8, o recurso de Allocation Classes permite criar VDEVs dedicados dentro do pool com a classe special. O alocador de blocos do ZFS (SPA - Storage Pool Allocator) verifica a classe do dado antes de escrever.
Se for metadado (DTL, tabelas de blocos indiretos, diretórios), ele é enviado obrigatoriamente para o dispositivo special (geralmente NVMe ou SSD Enterprise). Se for dado comum, vai para os VDEVs normal (HDDs).
 Fig. 2: Segregação física de I/O. O Special VDEV absorve o ruído aleatório, deixando os HDDs livres para throughput sequencial.
Fig. 2: Segregação física de I/O. O Special VDEV absorve o ruído aleatório, deixando os HDDs livres para throughput sequencial.
O impacto nos HDDs
Ao remover os metadados dos discos rotacionais, ocorre um fenômeno de "limpeza de I/O". O ruído aleatório de pequenas leituras de 4K/8K desaparece dos HDDs. O que sobra para os discos mecânicos são grandes sequências de leitura e escrita de dados.
Como a física dita, HDDs são excelentes em transferências sequenciais. Ao especializar as mídias, você permite que cada tecnologia opere na sua zona de eficiência máxima.
💡 Dica Pro: O ganho de performance em operações de
zfs send/recvezpool scrubcom Special VDEVs é massivo. O scrub não precisa mais buscar metadados nos HDDs, permitindo que a varredura de dados ocorra na velocidade linear máxima dos discos.
Engenharia e dimensionamento do Special VDEV
Implementar um Special VDEV exige rigor. Diferente do L2ARC, se o seu dispositivo special falhar e não houver redundância, você perde o pool inteiro. Os metadados são a estrutura do sistema de arquivos; sem eles, os dados nos HDDs são apenas bits sem significado.
Regra de Ouro da Redundância
Nunca, jamais, adicione um único SSD como special. Use sempre espelhamento (Mirror). Se o seu pool principal é RAID-Z2 ou RAID-Z3 (tolerância a 2 ou 3 falhas), seu Special VDEV deve ser, no mínimo, um mirror de 3 vias (3-way mirror) para manter a paridade de confiabilidade.
Dimensionamento (Sizing)
Uma regra prática comum é que os metadados ocupam cerca de 0,3% a 3% do tamanho total dos dados, dependendo do tamanho médio do arquivo (arquivos menores = mais metadados). Para um pool de 100 TB, um par de SSDs de 480GB ou 960GB em RAID-1 geralmente é suficiente.
Pequenos Blocos (Small Blocks)
Você pode ir além dos metadados. Com a propriedade special_small_blocks, você pode instruir o ZFS a armazenar arquivos inteiros no SSD se eles forem menores que um certo tamanho.
zfs set special_small_blocks=64K tank/vm-storage
Neste exemplo, qualquer I/O menor que 64K (típico de logs, arquivos de configuração, ou inodes de bancos de dados) será gravado diretamente no NVMe, ignorando os HDDs. Isso transforma seu armazenamento híbrido em um All-Flash Array para as cargas de trabalho que mais puniriam os discos mecânicos.
 Fig. 3: A zona de eficiência. Allocation Classes permitem que cada mídia opere onde sua física é mais favorável.
Fig. 3: A zona de eficiência. Allocation Classes permitem que cada mídia opere onde sua física é mais favorável.
Mensurando a redução de latência
Como engenheiros de performance, não confiamos em sensações; confiamos em métricas. Para verificar a eficácia do Special VDEV, utilizamos ferramentas de observabilidade do kernel e do próprio ZFS.
1. Histograma de Latência
O comando zpool iostat -w exibe histogramas de latência por VDEV.
Antes do Special VDEV (apenas HDDs):
total_wait disk_wait syncq_wait asyncq_wait
latency read write read write read write read write
...
10ms 500 0 480 0 10 0 10 0
20ms 12k 200 11k 150 500 20 500 30
...
Observe a concentração de leituras na casa dos 10ms-20ms (tempo de seek).
Após o Special VDEV (NVMe absorvendo metadados):
Os VDEVs de dados (HDD) mostrarão uma redução drástica nas operações de leitura pequenas, e o VDEV special mostrará latências na casa dos microssegundos (us/ns).
2. Verificando a distribuição de I/O
Use zpool iostat -v 1 para ver o fluxo em tempo real.
capacity operations bandwidth
pool alloc free read write read write
---------- ----- ----- ----- ----- ----- -----
tank 40.0T 20.0T 200 150 200M 100M
mirror-0 10.0T 5.0T 10 80 50M 40M (HDD)
mirror-1 10.0T 5.0T 10 80 50M 40M (HDD)
special - - - - - -
mirror-2 200G 300G 180 10 5M 1M (NVMe)
Neste cenário hipotético, note como o NVMe (special) está absorvendo 180 IOPS de leitura (provavelmente metadados e listagens de arquivos), enquanto os HDDs estão lidando com apenas 10 IOPS de leitura, mas entregando alta largura de banda. Isso é a segregação perfeita.
Fig. 4: Representação conceitual de um histograma de latência. A cauda longa (latência alta) é eliminada quando os seeks aleatórios são removidos da equação mecânica.
⚠️ Perigo: Monitore o preenchimento do Special VDEV. Se ele encher, os metadados transbordarão para os HDDs, reintroduzindo a penalidade de performance de forma imprevisível. O ZFS não "rebalanceia" isso automaticamente de volta para o SSD se você liberar espaço depois.
O veredito do silício
A implementação de Special VDEVs não é uma atualização trivial; é uma mudança de paradigma na engenharia de armazenamento. Ao reconhecer que nem todos os bytes são criados iguais, paramos de tratar o armazenamento como um bloco monolítico e passamos a tratá-lo como um sistema hierárquico onde a latência dita a localização física.
Para ambientes virtualizados, bancos de dados ou file servers com milhões de arquivos, essa estratégia estende a vida útil de arrays mecânicos e entrega uma experiência de usuário próxima ao All-Flash, a uma fração do custo por terabyte.
No entanto, a complexidade introduzida exige vigilância. Você está criando novos domínios de falha. Se sua tolerância a risco operacional for baixa, garanta que seus NVMe sejam de classe Enterprise (PLP - Power Loss Protection) e que a redundância seja matematicamente sólida. O ganho de performance é inebriante, mas a integridade dos dados é inegociável.
Referências & Leitura Complementar
OpenZFS Pull Request #5182: "Allocation Classes (Special VDEVs)". O código-fonte original que introduziu a funcionalidade, detalhando as mudanças no DMU (Data Management Unit).
ZFS On-Disk Specification: Documentação técnica sobre a estrutura dos dnodes e block pointers.
NVMe Specification 1.4: Detalhes sobre latência determinística e filas de comando em drives de estado sólido modernos.
RFC 3530 (NFSv4): Útil para entender como a latência de metadados no sistema de arquivos afeta protocolos de rede sensíveis a lookup como NFS.
Perguntas Frequentes
1. Posso remover um Special VDEV depois de adicioná-lo? Depende da configuração do pool. Se o Special VDEV for um mirror, você geralmente não pode removê-lo se for o único vdev top-level de sua classe, pois ele contém metadados vitais que não cabem em outro lugar instantaneamente. Em versões mais recentes do OpenZFS, a remoção de vdevs top-level é possível mas envolve a evacuação de dados para outros vdevs, o que é uma operação intensiva e arriscada. Planeje como se fosse permanente.
2. Qual a diferença entre SLOG (ZIL) e Special VDEV?
Confusão comum. O SLOG (Separate Intent Log) acelera apenas escritas síncronas (como NFS ou iSCSI com sync=always), absorvendo a latência de commit. O Special VDEV acelera leituras de metadados e escritas aleatórias de blocos pequenos. Eles resolvem problemas diferentes. Você pode (e deve, em muitos casos) usar ambos.
3. Preciso de SSDs Optane para Special VDEV? Não é estritamente necessário, mas é o cenário ideal. Como o Special VDEV sofre com muitas escritas pequenas e leituras constantes, a latência ultra-baixa e a alta durabilidade (DWPD) do Optane ou NVMe Enterprise são perfeitas. SSDs QLC de consumo (SATA/NVMe baratos) devem ser evitados a todo custo, pois falharão rapidamente sob a carga de metadados.
4. O que acontece se o Special VDEV encher?
O ZFS começará a gravar novos metadados nos vdevs normais (HDDs). A performance degradará para as novas gravações, mas o sistema não parará. O problema é que, mesmo liberando espaço no SSD depois, os dados gravados no HDD permanecerão lá até serem reescritos (ex: via zfs send/recv ou reescrita da aplicação).

André Linhares
Engenheiro de Performance (Kernel/IO)
"Vivo no kernel space caçando latência com eBPF. Para mim, context switches excessivos são inimigos pessoais e cada ciclo de CPU desperdiçado é uma ofensa técnica."