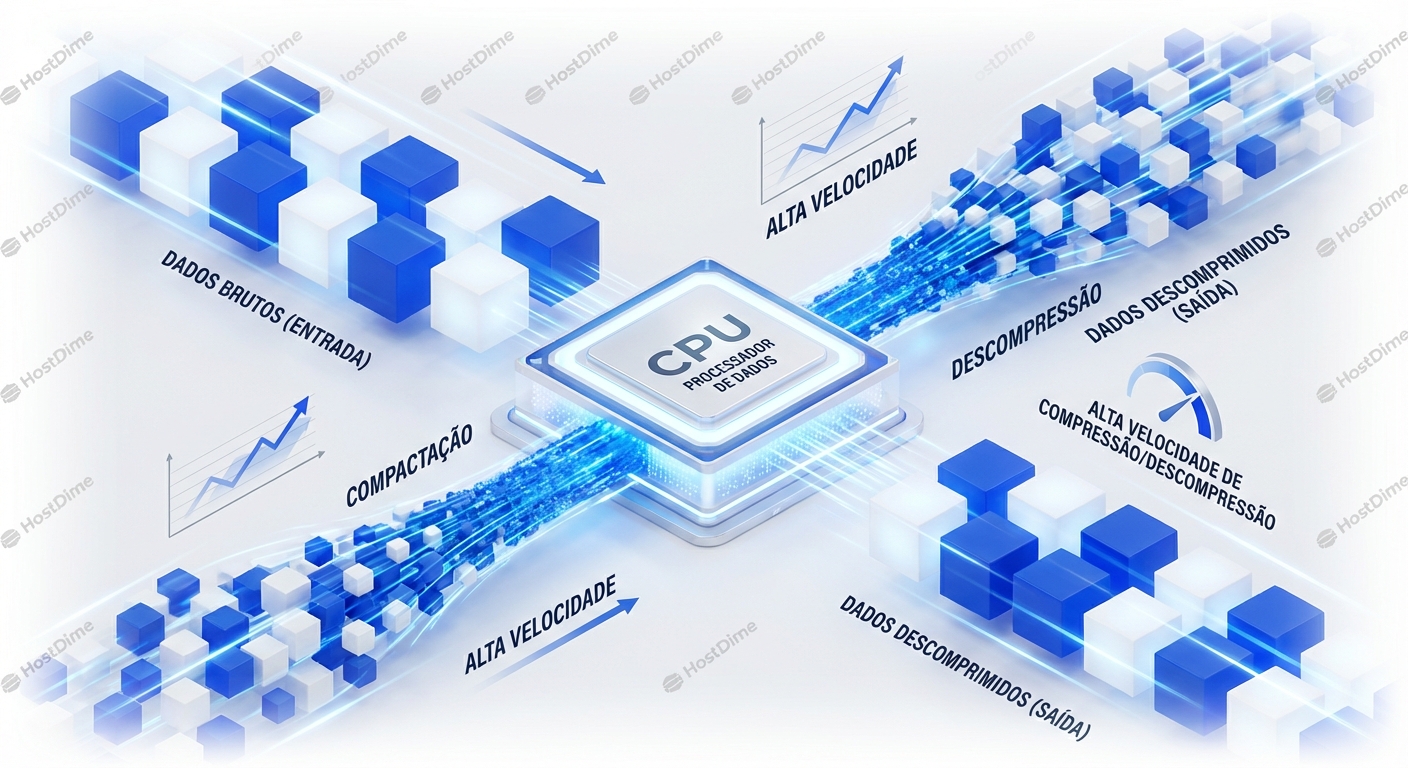
Compressao Impacto Em CPU E Latencia
A compressão de dados é uma faca de dois gumes. Por um lado, reduz o espaço de armazenamento e a largura de banda de transmissão, diminuindo custos e melhorando...

Engenheiro de Performance (Kernel/IO)
Vivo no kernel space caçando latência com eBPF. Para mim, context switches excessivos são inimigos pessoais e cada ciclo de CPU desperdiçado é uma ofensa técnica.
A compressão de dados é uma faca de dois gumes. Por um lado, reduz o espaço de armazenamento e a largura de banda de transmissão, diminuindo custos e melhorando...

Para um Sysadmin Sênior, a rede não é um tubo contínuo de dados. É uma série de eventos discretos. Cada pacote que entra ou sai da interface de rede (NIC) é um ...

Muitas empresas caem na armadilha de buscar RPO e RTO próximos de zero sem entender as implicações. Um RPO de zero significa que você não pode perder *nenhum* d...
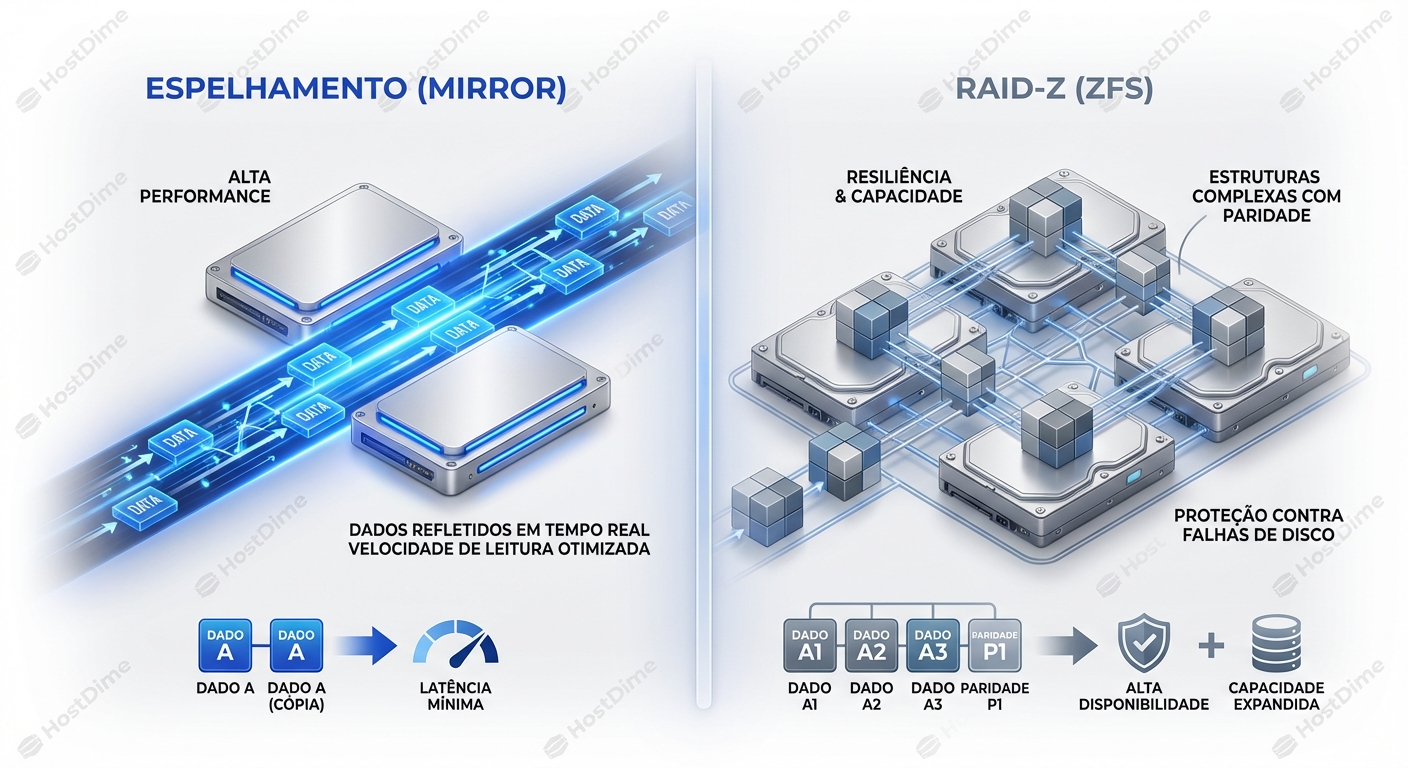
A escolha entre ZFS Mirror e RAIDZ (RAIDZ1, RAIDZ2, RAIDZ3) é crucial para determinar o desempenho, a capacidade de armazenamento e a tolerância a falhas do seu...
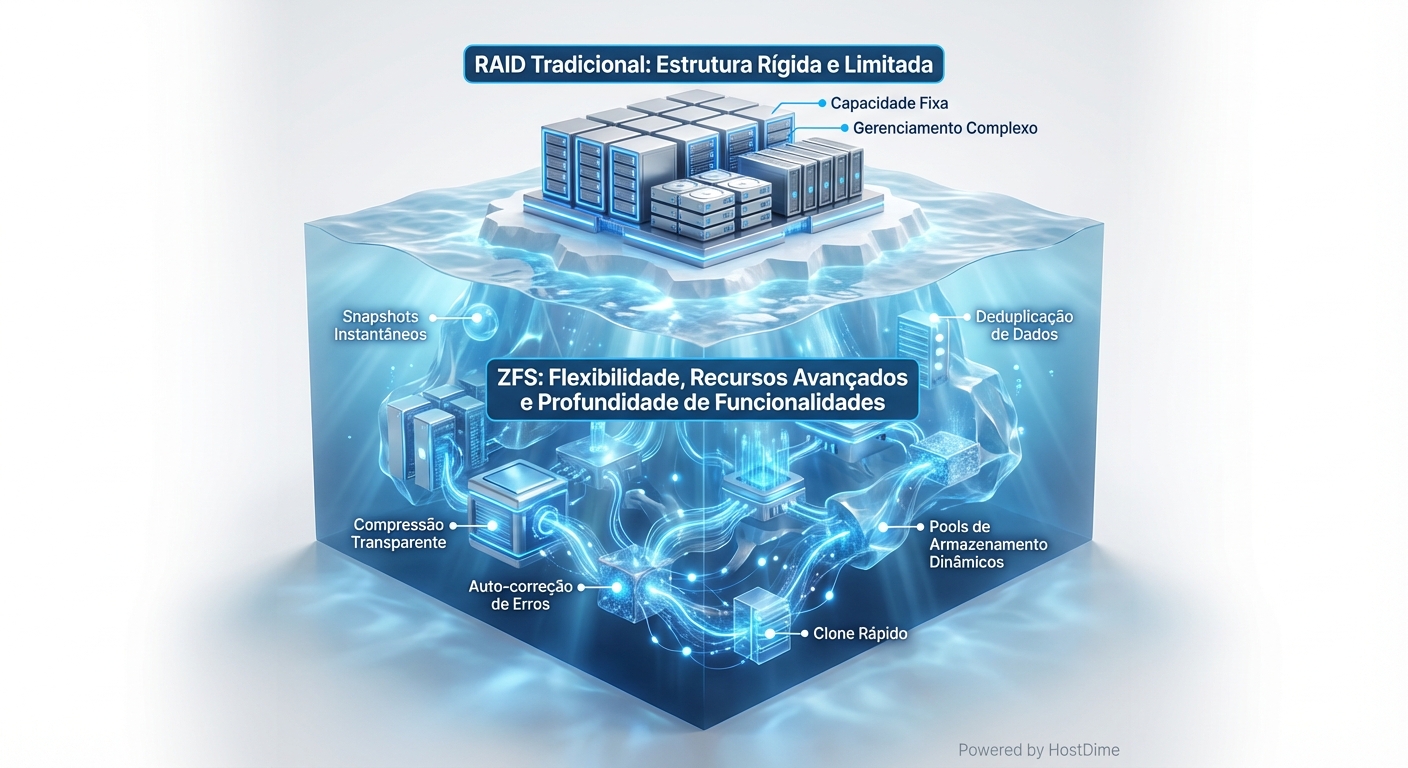
RAID te protege de falha de disco. ZFS te protege de *corrupção* de dados. Entenda a diferença, ou prepare-se para noites em claro....
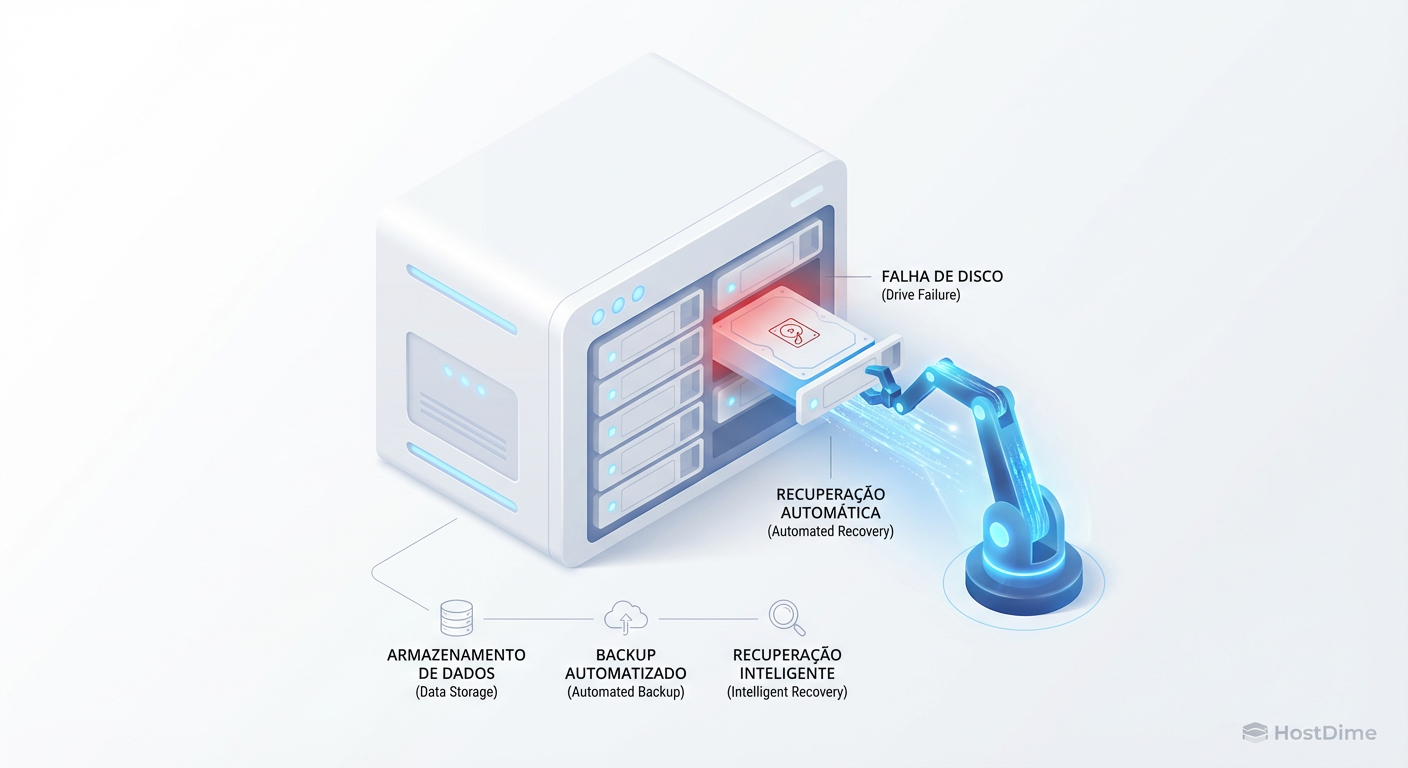
Não desperdice discos. Entenda a matemática entre Hot Spares Globais e Dedicados, o impacto no MTTR e por que o Spare Distribuído (dRAID) é o futuro da recuperação.
Entenda por que o Ceph parece lento em testes sintéticos mas escala em produção. Aprenda a medir latência distribuída, fila de I/O e a evitar a armadilha do 'dd'.
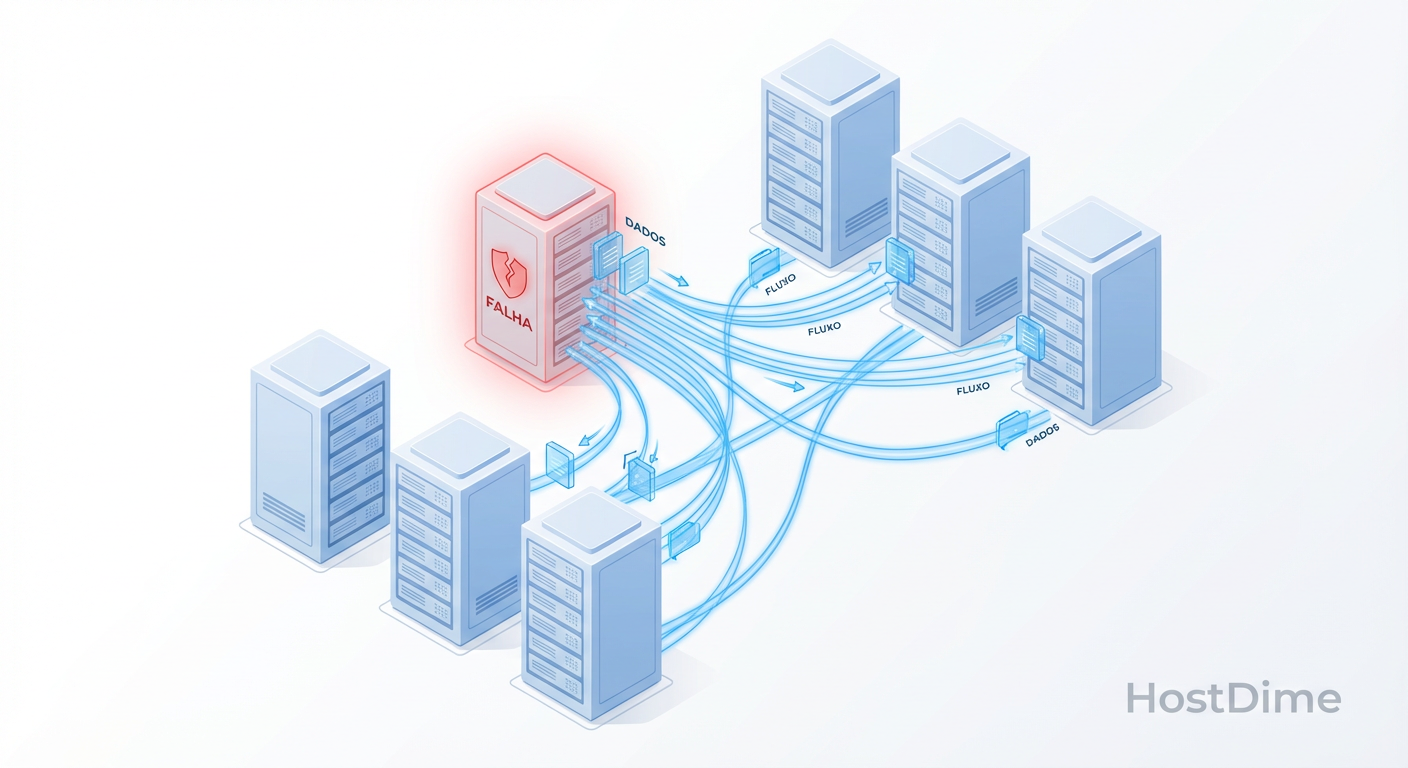
Entenda a física do Ceph Recovery e Backfill. Descubra por que falhas de OSD geram tempestades de I/O e aprenda a ajustar o mClock e throttles para proteger a latência de produção.
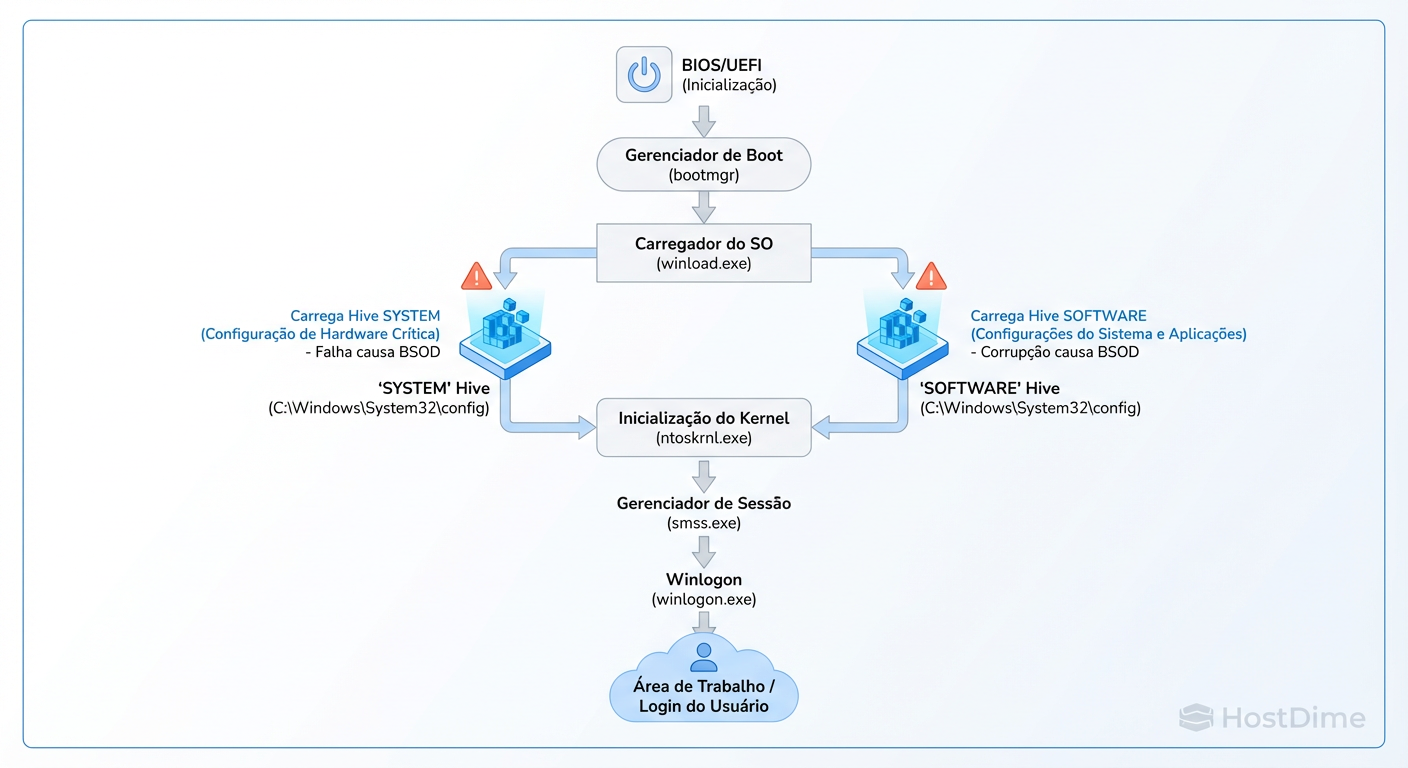
Edições no Registro do Windows 11 realmente melhoram a performance? Analisamos os mitos, os riscos de corrupção de hives e o único método seguro de rollback.

Domine o Write Amplification (WA) em SSDs NVMe. Do perfilamento com blktrace ao tuning de sistemas de arquivos e filas de bloco para reduzir latência e desgaste.

Desvende a arquitetura dos Special VDEVs no ZFS. Aprenda a eliminar a latência de metadados em discos rotacionais e otimize IOPS segregando blocos pequenos em NVMe.

Descubra como combinar Zoned Namespaces (ZNS) e io_uring passthrough para eliminar a latência de cauda e maximizar IOPS no Linux 6.x.

Esqueça a guerra de fans. Uma análise profunda de engenharia sobre filas, interrupções, ksmbd, nconnect e como saturar 10GbE+ sem desperdício de CPU.

Análise técnica detalhada: Como os novos SSDs QLC de ultra densidade (61.44TB+) estão dizimando o TCO dos HDDs em cenários de IA e Big Data. Comparativo de arquitetura, consumo e performance.

Descubra como eliminar a sobrecarga da camada de bloco e interrupções usando io_uring passthrough e polling. Guia avançado para engenharia de performance em storage.

Elimine o gargalo da Flash Translation Layer. Descubra como o NVMe Zoned Namespaces (ZNS) reduz a amplificação de escrita para 1.1x e estabiliza a latência em servidores de alta performance.

Descubra como o NVMe FDP (TP4146) reduz o Write Amplification Factor (WAF) e estabiliza a latência de cauda em SSDs Enterprise sem a complexidade do ZNS.

Descubra como o io_uring passthrough (kernel 5.19+) elimina o overhead da camada de bloco, permitindo acesso direto ao hardware NVMe com latência mínima e máxima eficiência de CPU.

Descubra como a nova implementação de tabelas hash no IOPOLL do io_uring elimina o gargalo de CPU em NVMes de alta performance, reduzindo a latência de cauda drasticamente.

Descubra como reduzir o WAF e eliminar a latência de cauda em SSDs Enterprise combinando NVMe Flexible Data Placement (FDP) e io_uring passthrough no Linux.

Descubra como eliminar o overhead de interrupções em SSDs NVMe usando io_uring e IOPOLL. Análise técnica de engenharia de performance para reduzir latência e maximizar throughput no Linux.

Engenharia de I/O profunda: Como o NVMe FDP (TP4146) reduz o WAF, elimina o 'Blender Effect' e estabiliza a latência de cauda em SSDs Enterprise sem a complexidade do ZNS.

Descubra como as atomic writes do protocolo NVMe eliminam a necessidade de double buffering no MySQL e PostgreSQL, reduzindo a latência e dobrando a vida útil do SSD.

Descubra se você deve usar chips PLX ou bifurcação nativa para seus arrays NVMe. Analisamos latência, custo e isolamento de falhas para servidores e workstations.

Análise técnica profunda sobre como o io_uring e o polling mode eliminam o overhead de syscalls e interrupções em SSDs NVMe, reduzindo a latência drasticamente no Linux.

Descubra por que schedulers como mq-deadline e bfq destroem a performance de SSDs NVMe. Entenda a arquitetura blk-mq, o impacto dos spinlocks na CPU e como otimizar o kernel Linux para latência de microssegundos.

Descubra como eliminar o overhead do kernel Linux usando io_uring e comandos NVMe passthrough. Aprenda a contornar o block layer para atingir latência na casa dos microssegundos.

Descubra como o padrão NVMe Zoned Namespaces (ZNS) transfere o controle da FTL para o host, zerando a amplificação de escrita e estabilizando a latência de cauda.