Bypass do block layer: extraindo latência ultrabaixa com NVMe passthrough e io_uring

Descubra como eliminar o overhead do kernel Linux usando io_uring e comandos NVMe passthrough. Aprenda a contornar o block layer para atingir latência na casa dos microssegundos.
Quando os discos rígidos magnéticos dominavam os datacenters, a latência era medida em milissegundos. O sistema operacional tinha tempo de sobra para enfileirar requisições, reordenar blocos e executar dezenas de milhares de ciclos de CPU enquanto o braço mecânico do disco buscava o setor correto. Hoje, com unidades de estado sólido baseadas no protocolo NVMe (Non-Volatile Memory Express) conectadas diretamente ao barramento PCIe, a latência caiu para a casa dos microssegundos.
O hardware evoluiu de forma brutal, mas as interfaces de software tradicionais não acompanharam esse ritmo. O resultado é um cenário onde a CPU se torna o gargalo do storage. Cada chamada de sistema (syscall) tradicional desperdiça ciclos preciosos com trocas de contexto, cópias de memória e bloqueios de thread. Para extrair o máximo de IOPS (Input/Output Operations Per Second) de um SSD NVMe moderno, precisamos repensar a forma como a aplicação conversa com o hardware.
Resumo em 30 segundos
- O kernel Linux tradicional adiciona latência indesejada ao processar I/O de dispositivos NVMe ultrarrápidos devido ao overhead do block layer.
- A interface io_uring revolucionou o I/O assíncrono ao usar buffers circulares compartilhados, eliminando a necessidade de syscalls constantes.
- O recurso de NVMe passthrough permite enviar comandos diretos ao driver, ignorando o subsistema de blocos e reduzindo drasticamente a latência de cauda.
O teto invisível de IOPS quando a CPU se torna o gargalo do storage
Se você monitorar um servidor de banco de dados de alta performance sob carga extrema, notará um comportamento peculiar. O uso de CPU atinge 100% em um núcleo específico, mas o disco NVMe reporta que está ocioso boa parte do tempo. Esse é o teto invisível de IOPS. A aplicação está gerando requisições mais rápido do que o kernel consegue processá-las e entregá-las ao hardware.
O problema reside na arquitetura clássica do sistema operacional. Para ler um bloco de dados, a aplicação em espaço de usuário (user space) precisa invocar uma syscall. Isso gera uma interrupção de software, forçando a CPU a salvar o estado atual, trocar para o modo kernel (kernel space), validar ponteiros, atravessar camadas de abstração e, finalmente, falar com o driver.
 Figura: Representação visual do gargalo de CPU limitando o potencial de um SSD NVMe moderno.
Figura: Representação visual do gargalo de CPU limitando o potencial de um SSD NVMe moderno.
Quando o dado está pronto, o dispositivo NVMe gera uma interrupção de hardware (IRQ). A CPU para o que está fazendo, processa a interrupção, acorda a thread da aplicação e realiza outra troca de contexto. Em um disco que responde em 10 microssegundos, gastar 3 microssegundos apenas transitando entre o kernel e a aplicação representa um desperdício inaceitável de 30% do tempo total da operação.
A jornada de um I/O tradicional pelas filas do kernel Linux
Para entender o impacto do bypass, precisamos mapear a rota padrão de uma operação de leitura ou escrita no Linux. Quando você chama a função read() ou write(), o dado inicia uma longa jornada.
Primeiro, a requisição passa pelo VFS (Virtual File System), a camada que abstrai se você está escrevendo em um sistema de arquivos Ext4, XFS ou ZFS. Em seguida, a requisição desce para o Block Layer (subsistema de blocos). Esta é uma peça de software complexa, projetada originalmente na era dos discos rotacionais.
O Block Layer possui filas de submissão, algoritmos de escalonamento (como o MQ-Deadline) e lógicas de fusão de requisições (merging). A ideia era agrupar pequenas escritas adjacentes em uma única operação grande para evitar que a agulha do HD ficasse pulando. Para um SSD NVMe, que pode ler blocos aleatórios quase na mesma velocidade que blocos sequenciais, essa lógica de reordenação frequentemente adiciona mais latência computacional do que benefícios de performance.
💡 Dica Pro: Em servidores com múltiplos SSDs NVMe, certifique-se de que o escalonador de I/O do sistema operacional esteja configurado como
none. Isso desativa lógicas de reordenação desnecessárias no Block Layer, economizando ciclos de CPU.
Após sobreviver ao Block Layer, a requisição finalmente chega ao driver NVMe, que a traduz em um comando nativo e a coloca na Submission Queue (SQ) do hardware via PCIe. É um caminho longo e tortuoso para um dispositivo que exige comunicação direta.
Por que aumentar as threads de submissão e usar AIO não resolve a latência de cauda
Historicamente, a resposta da indústria para contornar o bloqueio de I/O foi o uso de múltiplas threads ou interfaces assíncronas. O POSIX AIO e o Linux AIO (acessado via io_submit) foram tentativas de resolver isso. A premissa do Linux AIO é permitir que a aplicação submeta várias requisições de uma vez e seja notificada quando elas terminarem, sem bloquear a thread principal.
No entanto, o Linux AIO possui falhas arquitetônicas graves. Ele suporta apenas I/O não-bufferizado (usando a flag O_DIRECT), o que ignora o page cache do sistema operacional. Pior ainda, o Linux AIO frequentemente bloqueia a thread de forma imprevisível caso falte memória ou metadados precisem ser lidos do disco.
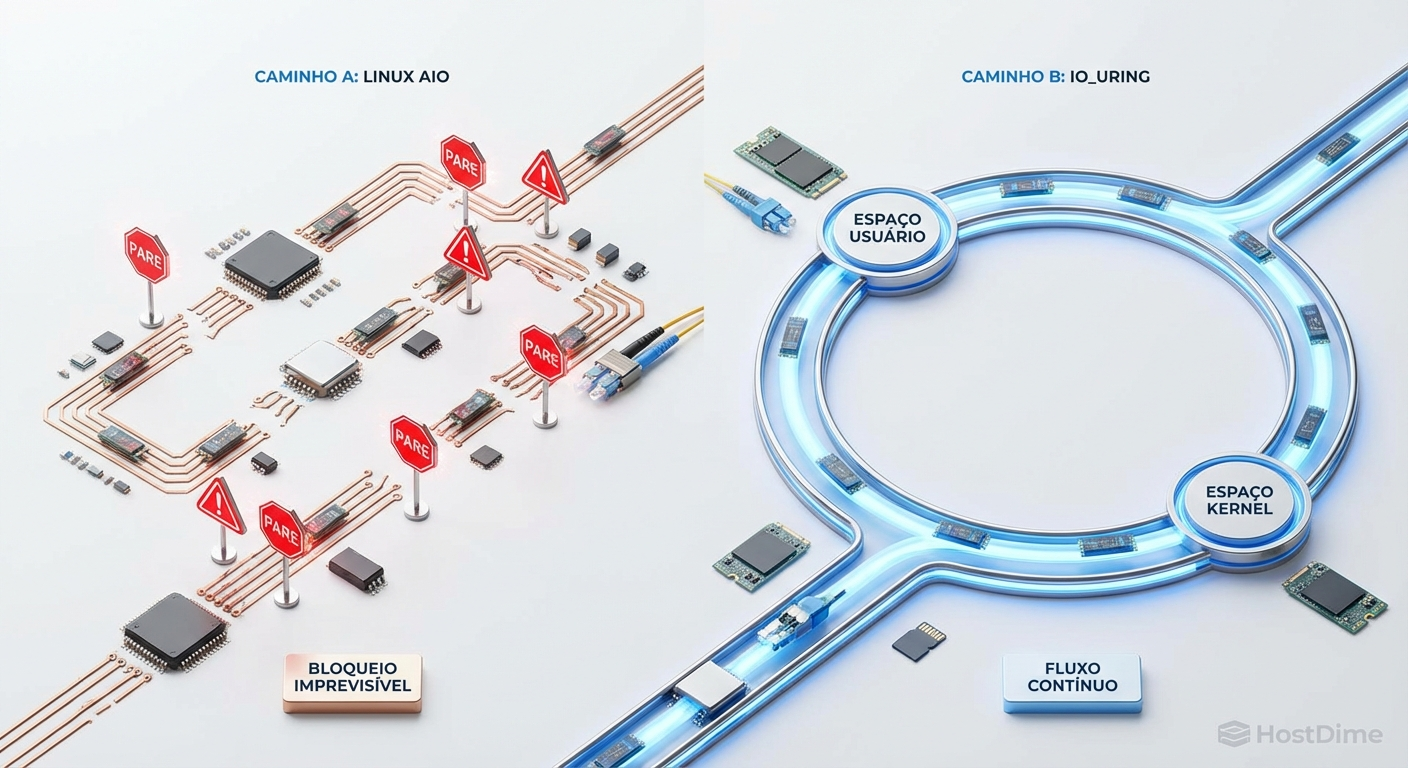 Figura: Comparativo de fluxo entre o bloqueio imprevisível do Linux AIO e a fluidez dos anéis do io_uring.
Figura: Comparativo de fluxo entre o bloqueio imprevisível do Linux AIO e a fluidez dos anéis do io_uring.
Além disso, o Linux AIO ainda exige pelo menos duas syscalls por ciclo de operação: uma para submeter o I/O e outra para colher os resultados. Em cargas de trabalho de altíssima densidade, como bancos de dados NoSQL ou sistemas de storage definidos por software (SDS), a latência de cauda (o tempo de resposta do 99º percentil das requisições) sofre picos severos devido a essas ineficiências. Aumentar o número de threads apenas piora a situação, gerando contenção de locks e destruindo a localidade de cache da CPU.
Injetando comandos NVMe diretos com io_uring passthrough
A verdadeira revolução no I/O do Linux chegou com o io_uring, desenvolvido por Jens Axboe. A arquitetura do io_uring é baseada em dois anéis de memória (ring buffers) compartilhados diretamente entre a aplicação (user space) e o kernel: a Submission Queue (SQ) e a Completion Queue (CQ).
Como a memória é compartilhada, a aplicação pode enfileirar dezenas de requisições de leitura e escrita na SQ sem fazer uma única syscall. O kernel lê essas requisições de forma assíncrona, processa o I/O e coloca os resultados na CQ. A aplicação então lê a CQ, novamente sem syscalls. Isso elimina quase totalmente o overhead de troca de contexto.
Mas a comunidade de performance de storage foi além. Se o io_uring já é rápido, por que não usá-lo para pular completamente o Block Layer? É aqui que entra o NVMe passthrough.
Utilizando um opcode específico chamado IORING_OP_URING_CMD, uma aplicação pode construir um comando NVMe puro (como um NVMe Read, Write ou até comandos de administração) e enviá-lo diretamente para o driver de caractere do dispositivo (ex: /dev/ng0n1), ignorando o dispositivo de bloco tradicional (/dev/nvme0n1).
Comparativo de Arquiteturas de I/O
Abaixo, detalhamos as diferenças cruciais entre as abordagens de I/O disponíveis no Linux moderno.
| Característica | Linux AIO Tradicional | io_uring (Padrão) | io_uring + NVMe Passthrough |
|---|---|---|---|
| Syscalls por Operação | Múltiplas (Submissão e Coleta) | Zero (com SQPOLL ativado) | Zero (com SQPOLL ativado) |
| Caminho no Kernel | VFS -> Block Layer -> Driver | VFS -> Block Layer -> Driver | Direto para o Driver NVMe |
| Suporte a Page Cache | Não (Apenas O_DIRECT) | Sim (Bufferizado e O_DIRECT) | Não (Acesso direto ao hardware) |
| Overhead de CPU | Alto (Trocas de contexto) | Baixo (Memória compartilhada) | Mínimo (Bypass total de abstrações) |
| Complexidade de Código | Média | Alta | Muito Alta (Exige lidar com LBA e setores) |
Ao usar o NVMe passthrough, a aplicação assume a responsabilidade de gerenciar os endereços lógicos de bloco (LBA). Não há sistema de arquivos. Não há VFS. É a aplicação conversando diretamente com a controladora de silício do SSD. Isso reduz a latência de submissão de software para a casa dos nanossegundos.
⚠️ Perigo: Fazer o bypass do Block Layer significa que ferramentas padrão do sistema operacional, como o
iostat, deixarão de registrar o tráfego de disco dessa aplicação. O kernel fica cego para esse I/O, exigindo que a própria aplicação exporte suas métricas de telemetria.
Medindo a redução de microssegundos com fio e eBPF
Afirmações sobre performance exigem provas empíricas. Para validar os ganhos do NVMe passthrough com io_uring, engenheiros de performance utilizam ferramentas rigorosas de benchmark e observabilidade.
O fio (Flexible I/O Tester) é o padrão da indústria para estressar dispositivos de storage. Nas versões mais recentes, o fio suporta nativamente o motor de I/O io_uring_cmd. Ao configurar um teste de leitura aleatória de 4KB (tamanho padrão de página de memória) apontando para o dispositivo de caractere NVMe, os resultados são reveladores.
Em um SSD NVMe PCIe Gen4 de classe enterprise, a transição do Linux AIO para o io_uring padrão já demonstra um aumento de cerca de 15% a 20% no limite máximo de IOPS. No entanto, ao ativar o NVMe passthrough (io_uring_cmd), observamos não apenas um aumento adicional no throughput, mas uma estabilização dramática na latência de cauda. O percentil 99.99% (p99.99), que antes sofria com picos gerados pelas filas do Block Layer, torna-se quase plano.
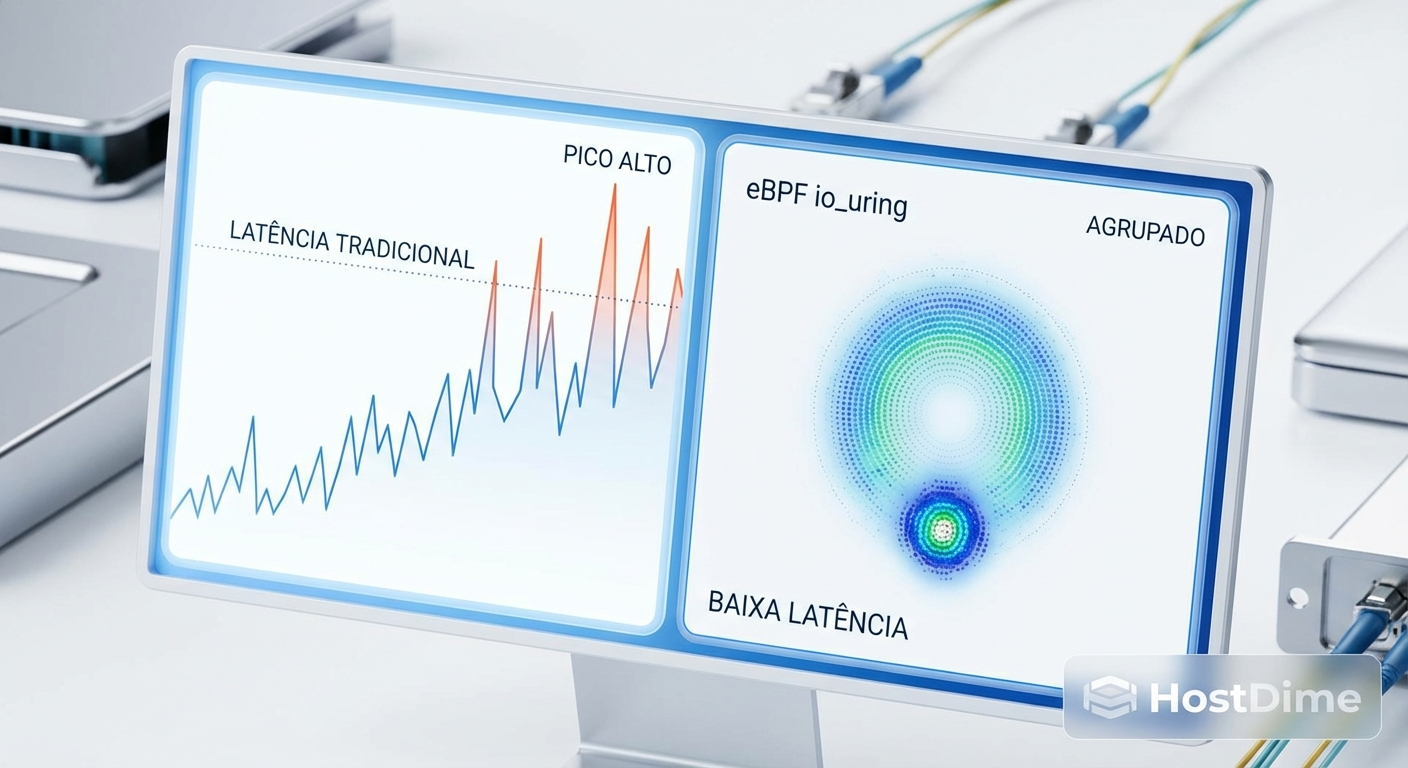 Figura: Visualização de telemetria comparando a latência errática do I/O tradicional com a consistência do NVMe passthrough.
Figura: Visualização de telemetria comparando a latência errática do I/O tradicional com a consistência do NVMe passthrough.
Para enxergar o que acontece dentro do kernel durante esses testes, utilizamos o eBPF (Extended Berkeley Packet Filter). Com scripts baseados em BCC (BPF Compiler Collection), como o biolatency ou ferramentas customizadas, podemos rastrear o tempo exato que uma requisição leva desde a entrada na Submission Queue do io_uring até o retorno da interrupção de hardware.
O eBPF prova matematicamente o ganho: o tempo gasto na camada de software cai drasticamente. A CPU, antes saturada gerenciando filas e trocas de contexto, agora fica livre para processar a lógica de negócios da aplicação, permitindo que o servidor faça mais trabalho com o mesmo hardware.
A redefinição das interfaces POSIX e o futuro do storage
A busca implacável por latência ultrabaixa está forçando uma quebra de paradigma na engenharia de sistemas. A interface POSIX, projetada há décadas para abstrair fitas magnéticas e discos rotacionais, tornou-se um obstáculo para o hardware moderno.
O sucesso do io_uring e a adoção do NVMe passthrough indicam uma tendência clara: o futuro do storage de altíssima performance reside no bypass do kernel. Aplicações críticas, como bancos de dados in-memory, motores de inteligência artificial e infraestruturas de nuvem, não podem mais se dar ao luxo de pagar o pedágio das abstrações genéricas do sistema operacional.
A recomendação para arquitetos de software e engenheiros de infraestrutura é clara. Se você está projetando sistemas I/O-bound para a próxima década, ignorar as capacidades do io_uring é um erro estratégico. A transição exige reescrever camadas fundamentais de acesso a dados, mas a recompensa é a extração de cada gota de performance que o silício moderno tem a oferecer. O kernel Linux continuará sendo um excelente gerenciador de recursos gerais, mas para o caminho crítico dos dados, a via expressa do passthrough é o único caminho viável.
Referências & Leitura Complementar
Axboe, Jens. "Efficient IO with io_uring". PDF original detalhando a arquitetura dos ring buffers. Disponível nos arquivos do kernel Linux.
NVM Express Base Specification. Documentação oficial da NVM Express, Inc., detalhando os comandos de submissão e conclusão (SQ/CQ) no nível do hardware.
Gregg, Brendan. "BPF Performance Tools". Leitura essencial para entender como rastrear latência de I/O em microssegundos usando eBPF.
Documentação do kernel Linux.
Documentation/block/io_uring.rste os commits relacionados à implementação doIORING_OP_URING_CMD.
O que é NVMe passthrough no contexto do io_uring?
É a capacidade de enviar comandos NVMe puros diretamente da aplicação para o driver do dispositivo (usando a operação IORING_OP_URING_CMD), ignorando o subsistema de blocos (block layer) do kernel Linux. Isso elimina camadas de abstração e reduz drasticamente a latência computacional.Por que o Linux AIO tradicional é inferior ao io_uring para discos NVMe?
O AIO clássico suporta apenas I/O não-bufferizado (O_DIRECT), frequentemente bloqueia de forma imprevisível e exige múltiplas syscalls para submissão e conclusão. Isso gera desperdício de ciclos de CPU com trocas de contexto, algo fatal para a performance de SSDs NVMe modernos que respondem em microssegundos.É seguro fazer bypass do block layer em servidores de produção?
Sim, mas exige arquitetura de software específica. Ao ignorar o block layer, a aplicação perde recursos nativos do kernel, como escalonamento de I/O e estatísticas padrão (iostat). É uma técnica ideal para bancos de dados de alta performance e aplicações de storage definidas por software (SDS) que já gerenciam sua própria lógica de I/O e telemetria.
André Linhares
Engenheiro de Performance (Kernel/IO)
"Vivo no kernel space caçando latência com eBPF. Para mim, context switches excessivos são inimigos pessoais e cada ciclo de CPU desperdiçado é uma ofensa técnica."