Ceph Scrubbing: Otimizando Integridade de Dados sem Matar a Latência
O Scrubbing do Ceph previne bit rot, mas pode derrubar a performance. Aprenda a ajustar janelas de manutenção, prioridades e deep-scrub para evitar instabilidade no cluster.
Como arquiteto de soluções, frequentemente encontro administradores de storage que tratam o Ceph como uma caixa preta mágica: você joga dados dentro e eles ficam seguros para sempre. A realidade é mais dura. O Ceph, como qualquer sistema distribuído resiliente, luta contra a entropia física dos discos — o temido bit rot. A arma do Ceph contra isso é o Scrubbing.
No entanto, há um paradoxo aqui. O processo desenhado para garantir a integridade dos seus dados é, muitas vezes, o mesmo processo que mata a performance da sua aplicação crítica às 14h de uma terça-feira. Se você não controlar o scrubbing, ele controlará o seu SLA.
A resposta não é "desligar a verificação" (isso é negligência) nem "deixar no padrão" (isso é ingenuidade). A resposta, como sempre em arquitetura, depende de entender os trade-offs e ajustar os botões certos.
O que é Ceph Scrubbing? Ceph Scrubbing é o mecanismo de manutenção automatizada que verifica a consistência dos dados em um cluster. Ele compara as réplicas dos Placement Groups (PGs) entre os OSDs para detectar inconsistências. O Scrub (leve) verifica apenas os metadados e mapas de objetos, enquanto o Deep Scrub (pesado) lê o conteúdo bit a bit de todos os dados armazenados, competindo diretamente por IOPS com a carga de trabalho de produção.
O Paradoxo do Scrubbing e a Mecânica Interna
Para operar o Ceph corretamente, você precisa abandonar a ideia de que o disco está "parado" quando nenhum usuário está gravando. Em sistemas distribuídos, o estado de repouso é uma ilusão.
O Ceph possui dois tipos de verificação, e confundir o impacto de um com o outro é um erro comum de diagnóstico:
Scrub (Normal/Light): Pense nisso como uma chamada de lista. O Ceph verifica se os metadados dos objetos nos Placement Groups (PGs) batem entre as réplicas. É rápido, leve e geralmente imperceptível.
Deep Scrub: Aqui mora o perigo. O Ceph lê o payload (o dado real) de cada objeto em todas as réplicas e calcula um checksum (CRC) para compará-los.
Se você tem discos de 10TB ou 16TB, o Deep Scrub obriga o OSD a ler todo esse volume periodicamente. Em um HDD mecânico (spinning rust), isso satura a capacidade de IOPS aleatórios e sequenciais.
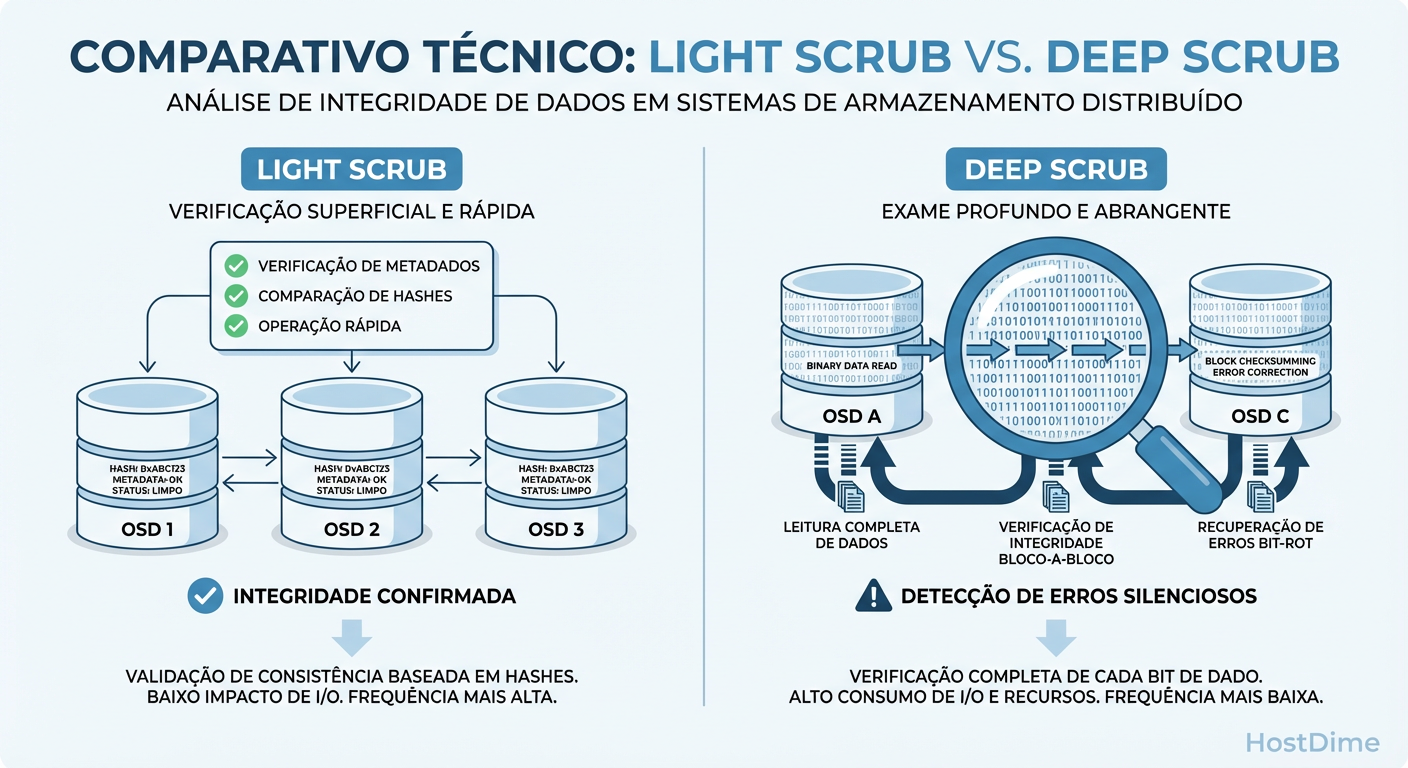 Figura: Diferença de impacto: O Scrub valida metadados (rápido), o Deep Scrub valida o conteúdo (caro).
Figura: Diferença de impacto: O Scrub valida metadados (rápido), o Deep Scrub valida o conteúdo (caro).
A imagem acima ilustra a diferença fundamental. Enquanto o Scrub superficial apenas "bate na porta" para ver se alguém responde, o Deep Scrub "entra na casa e verifica a mobília". O custo computacional e de I/O do segundo é ordens de magnitude maior.
O Impacto do Scrubbing na Latência de Cauda (p99)
A maioria dos dashboards de monitoramento mente para você porque foca na média. "A latência média está em 5ms, está tudo ótimo". Não, não está.
Quando o Deep Scrub está ativo em um OSD, as requisições de leitura/escrita da sua aplicação (o I/O do cliente) entram na mesma fila de prioridade do I/O de verificação. Embora o Ceph tente priorizar o cliente, a física do disco rígido é implacável: a cabeça de leitura não pode estar em dois lugares ao mesmo tempo.
O resultado é o aumento da latência de cauda (p99 ou p99.9). A média continua baixa, mas 1% ou 0.1% das requisições — aquelas que caem justamente no disco que está sendo verificado — demoram 500ms, 1 segundo, ou até geram timeouts na aplicação.
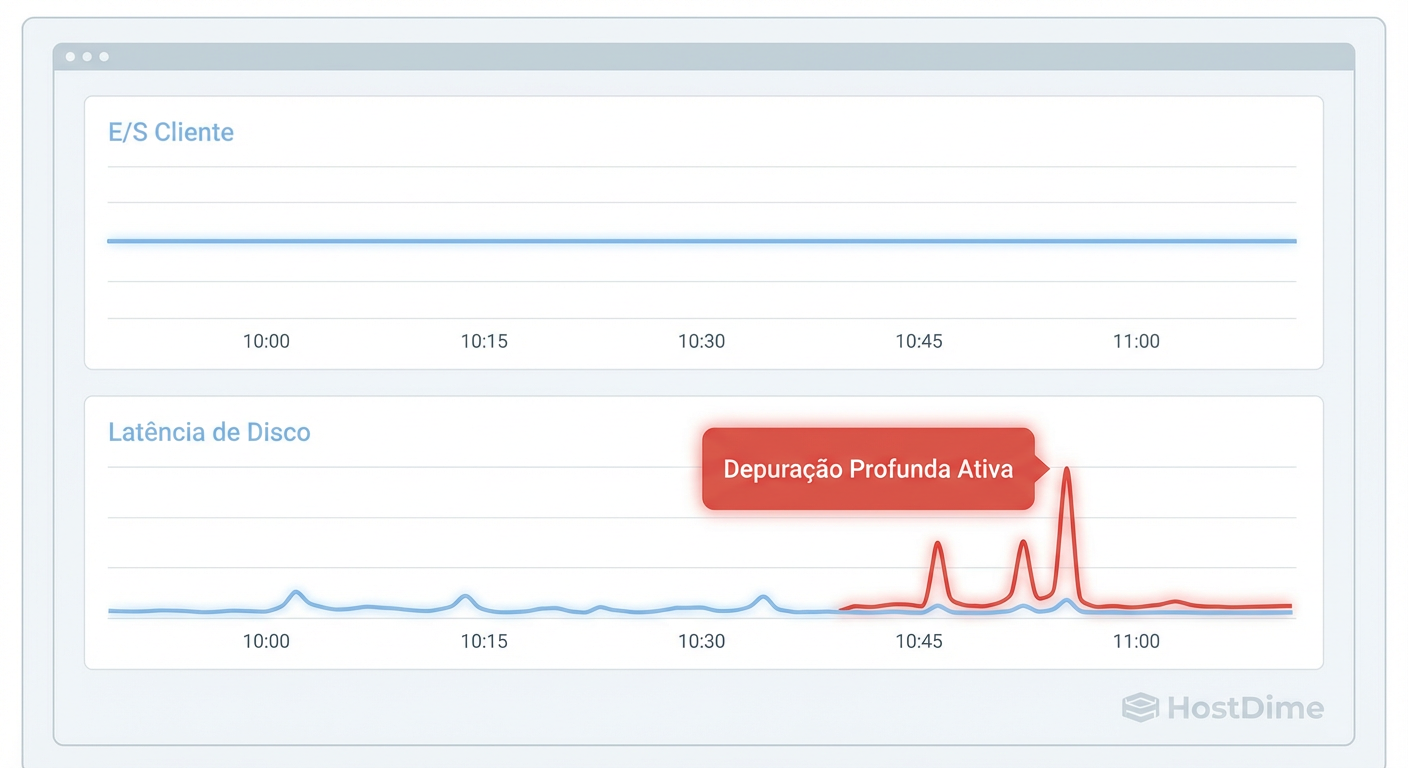 Figura: O custo oculto: Correlação entre atividade de Deep Scrub e picos de latência no disco.
Figura: O custo oculto: Correlação entre atividade de Deep Scrub e picos de latência no disco.
Como mostrado na correlação acima, os picos de latência "fantasmas" (sem aumento de tráfego de usuários) geralmente se alinham perfeitamente com os horários de agendamento do Deep Scrub. Se você vê lentidão esporádica que não correlaciona com uso de CPU ou Rede, verifique se seus discos não estão "se curando" até a morte.
Estratégias de Configuração de Scrubbing para Reduzir Contenção
Não existe "melhor prática" universal, existe ajuste de cenário. Um cluster All-Flash NVMe aguenta um scrubbing agressivo que colocaria um cluster de HDDs SATA de joelhos.
Aqui estão as alavancas que você deve puxar para domar o processo:
1. Janelas de Tempo (Time Windows)
A estratégia mais básica é restringir o scrubbing para horários de baixo movimento. Por padrão, o Ceph pode fazer isso a qualquer momento.
# Define o início e fim da janela de scrub (ex: 22h às 06h)
ceph config set osd osd_scrub_begin_hour 22
ceph config set osd osd_scrub_end_hour 6
O Risco: Se a sua janela for muito curta e seus discos muito grandes, o Ceph nunca conseguirá terminar o ciclo de verificação dentro do prazo estipulado (ex: osd_deep_scrub_interval), deixando dados não verificados por longos períodos.
2. OSD Scrub Sleep (A "Pausa para Respirar")
Esta é a configuração mais subutilizada e eficaz para clusters híbridos ou HDD. O osd_scrub_sleep injeta uma pausa artificial entre as operações de scrub.
Se você definir isso para 0.1 (100ms), o OSD fará um pedaço do trabalho de scrub e dormirá por 100ms, liberando a cabeça do disco para I/O de produção.
# Adiciona uma pausa de 100ms entre operações de scrub
ceph config set osd osd_scrub_sleep 0.1
Trade-off: Isso torna o processo de scrub muito mais lento. Um deep scrub que levaria 12 horas pode levar 3 dias. Mas a latência do cliente permanecerá estável.
3. Chunk Size (Tamanho do Bloco)
Você pode alterar o tamanho do pedaço de dados verificado por vez (osd_scrub_chunk_min e max). Valores menores causam menos bloqueio momentâneo, mas aumentam o overhead total de metadados. Geralmente, mexer aqui traz retornos decrescentes comparado ao sleep.
Comparativo de Abordagens
Abaixo, comparo três perfis comuns de configuração e seus impactos no TCO (considerando custo de performance e risco).
| Estratégia | Configuração Típica | Impacto na Latência (Cliente) | Risco de Bit Rot | Cenário Ideal |
|---|---|---|---|---|
| Padrão (Default) | Sem janelas, sem sleep. Intervalo de 1 semana. | Alto. Picos imprevisíveis a qualquer hora do dia. | Baixo. Verificação constante. | Clusters All-Flash ou Dev/Test. |
| Janela Noturna | begin_hour 22, end_hour 06. |
Médio/Baixo durante o dia. Alto à noite (pode afetar backups). | Médio. Se a janela for curta, dados ficam sem check. | Clusters de Produção com ciclo diurno claro. |
| Throttled (Sleep) | osd_scrub_sleep 0.1 + Janelas. |
Muito Baixo. O impacto é diluído. | Baixo/Médio. O ciclo completo demora mais para fechar. | Clusters HDD de alta densidade ou Latency-Sensitive. |
Métricas Essenciais no Ceph: Diferenciando Scrubbing de Falhas
Antes de culpar a rede ou o banco de dados, verifique o estado dos PGs.
No CLI, o comando ceph -s ou ceph pg stat mostrará estados como active+clean+scrubbing ou active+clean+deep_scrubbing.
No Grafana (ou Prometheus), você deve monitorar duas métricas em paralelo para provar que a lentidão é culpa do scrubbing:
OSD Latency (Commit/Apply): O tempo de resposta do disco.
Scrubbing State Count: O número de PGs em estado de scrub naquele momento.
Se a curva de latência sobe exatamente quando a curva de Scrubbing sobe, você tem sua evidência (como visto na
Figura: O custo oculto: Correlação entre atividade de Deep Scrub e picos de latência no disco.
). Se a latência sobe sem atividade de scrub, procure por falhas de hardware (Smart stats) ou gargalos de rede.
Trade-offs Reais: Quando Relaxar a Verificação
A decisão arquitetural final resume-se a: Quanto tempo você aceita conviver com um bit corrompido não detectado?
O padrão do Ceph costumava ser fazer Deep Scrub semanalmente. Em discos modernos de 18TB+, isso é insustentável — o disco passaria 30-40% da vida dele apenas se lendo.
Recomendação Pragmática:
Para clusters de alta densidade (HDDs grandes), é aceitável aumentar o osd_deep_scrub_interval para 2 ou até 4 semanas, desde que você tenha redundância suficiente (Réplica 3 ou Erasure Coding 4+2). O risco de perder dados por bit rot em duas réplicas simultaneamente dentro de um mês é estatisticamente menor do que o prejuízo de performance causado por scrubs semanais constantes.
Não existe almoço grátis. Ou você paga com IOPS (latência) ou paga com Risco (tempo de detecção). O segredo é pagar a moeda que sua empresa tem sobrando.
Referências & Leitura Complementar
Ceph Documentation: Scrubbing Configuration Reference. Docs.ceph.com.
Sage Weil (Ceph Creator): RADOS: A Scalable, Reliable Storage Service for Petabyte-scale Storage Clusters (Whitepaper original detalhando a lógica de consistência).
CERN Tech Blog: Ceph scrubbing at scale - Managing 30PB of data. (Estudo de caso sobre impacto de scrubbing em larga escala).
RFC 6455: The WebSocket Protocol (Relevante apenas se estiver monitorando via dashboard live, mas a base teórica de I/O em bloco está nos papers do RADOS).

Roberto Lemos
Arquiteto de Workloads
"Projeto infraestrutura onde o perfil de I/O dita as regras. Sei que a latência do acesso aleatório de um banco difere da vazão sequencial de vídeos. Mapeio o hardware exato para cada aplicação."