
Bit Rot E Silent Data Corruption Como Detectar E Corrigir
A corrupção silenciosa de dados ocorre quando informações são alteradas sem que o sistema ou o usuário percebam. Diferente de uma falha de disco completa, onde ...

Arquiteto de Workloads
Projeto infraestrutura onde o perfil de I/O dita as regras. Sei que a latência do acesso aleatório de um banco difere da vazão sequencial de vídeos. Mapeio o hardware exato para cada aplicação.
A corrupção silenciosa de dados ocorre quando informações são alteradas sem que o sistema ou o usuário percebam. Diferente de uma falha de disco completa, onde ...

A latência média mente. Se você está gerenciando sistemas distribuídos, confiando apenas na latência média, está construindo sobre areia movediça. A latência mé...

Não confie apenas no LED verde. Aprenda a monitorar atributos SMART críticos através de controladoras RAID, interpretar valores RAW e antecipar falhas de disco antes da perda de dados.
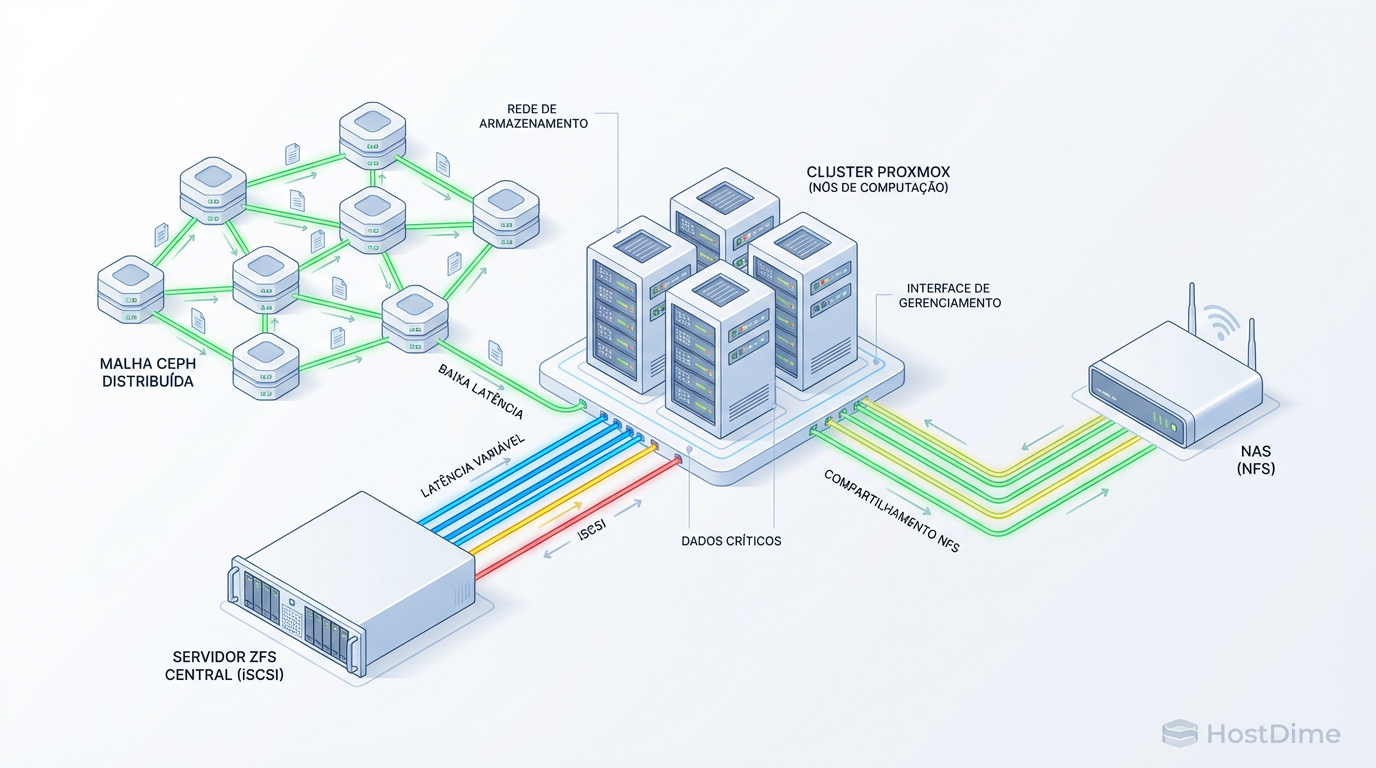
Não escolha seu storage no cara ou coroa. Compare arquitetura, latência e complexidade entre Ceph, ZFS over iSCSI e NFS para clusters Proxmox HA de alta performance.

Fuja do lock-in sem perder dados. Guia técnico para migrar VMs do ESXi para Proxmox VE, focando na conversão correta de vmdk, drivers VirtIO e escolha entre qcow2 ou ZFS raw.

Pare de desperdiçar orçamento em placas 100GbE sem motivo. Descubra onde o gargalo real do Ceph se esconde: latência, CPU ou rede, e quando migrar de 10GbE para 25GbE.
O Scrubbing do Ceph previne bit rot, mas pode derrubar a performance. Aprenda a ajustar janelas de manutenção, prioridades e deep-scrub para evitar instabilidade no cluster.

Aprenda a forçar o driver NVMe Padrão da Microsoft no Windows 11 via Registro. Entenda os riscos, ganhos de latência e como evitar o erro INACCESSIBLE_BOOT_DEVICE.

Descubra como os Special VDEVs do OpenZFS eliminam o gargalo de IOPS em pools de HDDs. Guia avançado de arquitetura, dimensionamento (0.3% rule) e riscos de implementação.

Acelerar metadados e blocos pequenos com SSDs parece mágica, mas uma falha aqui significa perda total do pool. Aprenda a arquitetura de sobrevivência com espelhamento triplo e dimensionamento correto.

Chega de teatro de segurança. Aprenda a configurar um Linux Hardened Repository (LHR) com XFS e reflinks para criar backups à prova de ransomware e deleção acidental.

Guia de resposta a incidentes para proteger infraestruturas VMware ESXi e Veeam contra o ransomware Akira. Análise da CVE-2024-37085, táticas de imutabilidade e recuperação.

Abandone o iSCSI. Guia técnico para arquitetos de banco de dados sobre como implementar NVMe/TCP, eliminar gargalos de CPU e reduzir a latência de cauda (p99) em redes Ethernet padrão.

Guia técnico de mitigação para a falha crítica CVE-2024-40711 no Veeam Backup & Replication (CVSS 9.8). Proteja seu storage de ataques RCE e ransomware.

Transforme a performance do seu pool HDD movendo metadados para NVMe. Guia completo sobre Special VDEVs no OpenZFS: configuração, riscos e benchmarking.

Aprenda a eliminar o gargalo de IOPS em pools de HDDs movendo metadados e pequenos blocos para NVMe com a classe de alocação especial do OpenZFS.

Descubra como o CXL 3.1 e a memória desagregada eliminam o 'Memory Wall' em bancos de dados, reduzindo o TCO e permitindo pools de RAM de múltiplos terabytes.

Entenda como o 'efeito liquidificador' destrói a performance do seu storage. Uma análise técnica sobre latência, throughput e isolamento de workloads críticos.

Descubra por que upgrades de largura de banda falham em resolver lentidão de bancos de dados. Um guia técnico para arquitetar storage baseado em IOPS, latência e Queue Depth.

Uma análise técnica para DBAs sobre por que RAID 5 e SSDs QLC destroem a latência de bancos de dados transacionais e como arquitetar a solução correta.

Descubra por que o iSCSI é o gargalo dos seus SSDs modernos. Comparativo técnico de NVMe-oF/TCP vs iSCSI focado em latência, CPU e filas de comando.

Abandone o ls e o cat. Descubra como ferramentas baseadas em Rust (eza, dust, bat) transformam a gestão de discos, logs e performance em servidores Linux.

Análise técnica sobre como o CXL 3.1 elimina o gargalo de memória em clusters de IA, superando as limitações de HBM3e e DDR5 com pools compartilhados de baixa latência.

Análise técnica profunda sobre NVMe-oF: comparamos o custo de processamento (CPU overhead) entre transportes TCP e RDMA (RoCEv2). Entenda como o kernel bypass reduz a latência de cauda em bancos de dados críticos.

Análise técnica sobre como o Compute Express Link (CXL) elimina a latência entre memória e armazenamento, transformando a arquitetura de dados para LLMs e workloads de alta performance.

Descubra como o NVMe over TCP elimina a latência do iSCSI e resolve o dilema da persistência no Kubernetes. Uma análise técnica para arquitetos de workloads críticos.

Análise técnica para arquitetos de workload: como o protocolo CXL elimina o gargalo entre DRAM e NVMe, transformando o barramento PCIe em extensão de memória coerente.

Descubra como a arquitetura de armazenamento desagregado com NVMe-oF e GPUDirect elimina gargalos de I/O em clusters de IA, maximizando o ROI de GPUs H100.

Descubra como o desalinhamento NUMA mata a performance de arrays NVMe em servidores multi-socket e aprenda a configurar a afinidade de CPU e IRQ corretamente.

Entenda como o Flexible Data Placement (FDP) do NVMe isola workloads no nível do NAND, reduz o WAF e estabiliza o QoS sem a complexidade do ZNS.

Aprenda a usar o zdb para dissecar estruturas on-disk do ZFS, simular deduplicação e auditar metadados sem comprometer seus dados. Tutorial avançado para sysadmins.

Entenda a anatomia do gargalo de I/O no treinamento de IA e aprenda a projetar topologias NVMe-oF com GPUDirect Storage para eliminar a ociosidade das GPUs.

Descubra como o ajuste fino das estratégias de compactação no RocksDB reduz o write amplification e previne a exaustão prematura de SSDs QLC em bancos de dados.