Desvendando a latência de cauda em storage com eBPF

Aprenda a diagnosticar gargalos de I/O invisíveis ao iostat. Um guia de SRE para usar eBPF, biosnoop e biolatency na análise profunda do kernel Linux.
Desvendando a latência de cauda em storage com eBPF
O pager toca às 3 da manhã. O dashboard da aplicação mostra timeouts de banco de dados e latência de transação disparando para 500ms. Você abre o terminal, digita iostat -x 1 e vê a utilização do disco em 40% e uma latência média (await) de 2ms. Para o sistema operacional, o storage está saudável. Para o cliente, o serviço está indisponível.
Essa dissonância cognitiva é o pesadelo de qualquer Engenheiro de Confiabilidade (SRE). O problema reside na incapacidade das ferramentas tradicionais de capturar a "latência de cauda" (tail latency). Em sistemas de armazenamento modernos, especialmente com a velocidade dos SSDs NVMe, médias são mentiras estatísticas que escondem a realidade da experiência do usuário.
Resumo em 30 segundos
- Médias mentem: Ferramentas como
iostatmostram médias agregadas que diluem picos de latência críticos (outliers) responsáveis por timeouts na aplicação.- Visibilidade granular: O eBPF permite rastrear cada operação de I/O individualmente no kernel, sem o overhead proibitivo de ferramentas de debug antigas.
- Histogramas salvam vidas: Visualizar a distribuição da latência (p99, p99.9) revela gargalos que métricas lineares ignoram, permitindo diagnósticos precisos em segundos.
A falácia das médias na observabilidade de discos
A métrica await do iostat é, historicamente, o padrão ouro para medir a saúde de resposta do disco. Ela calcula o tempo médio que as operações de I/O ficaram na fila e foram atendidas. No entanto, em um ecossistema de microsserviços ou bancos de dados de alta performance, a média é irrelevante.
Imagine um SSD NVMe processando 10.000 IOPS. Se 9.990 operações levam 0,1ms (rápido) e 10 operações levam 200ms (lento, devido a uma coleta de lixo interna do SSD ou contenção de bloqueio), a média aritmética será de aproximadamente 0,3ms. O dashboard fica verde. Mas para as 10 requisições que caíram nesses 200ms, o banco de dados travou, a conexão expirou e o usuário recebeu um erro 500.
Esses eventos de alta latência e baixa frequência compõem a "cauda longa" da distribuição. Monitorar apenas a média é como tentar prever o clima olhando apenas para a temperatura média anual; você não saberá quando um furacão está passando.
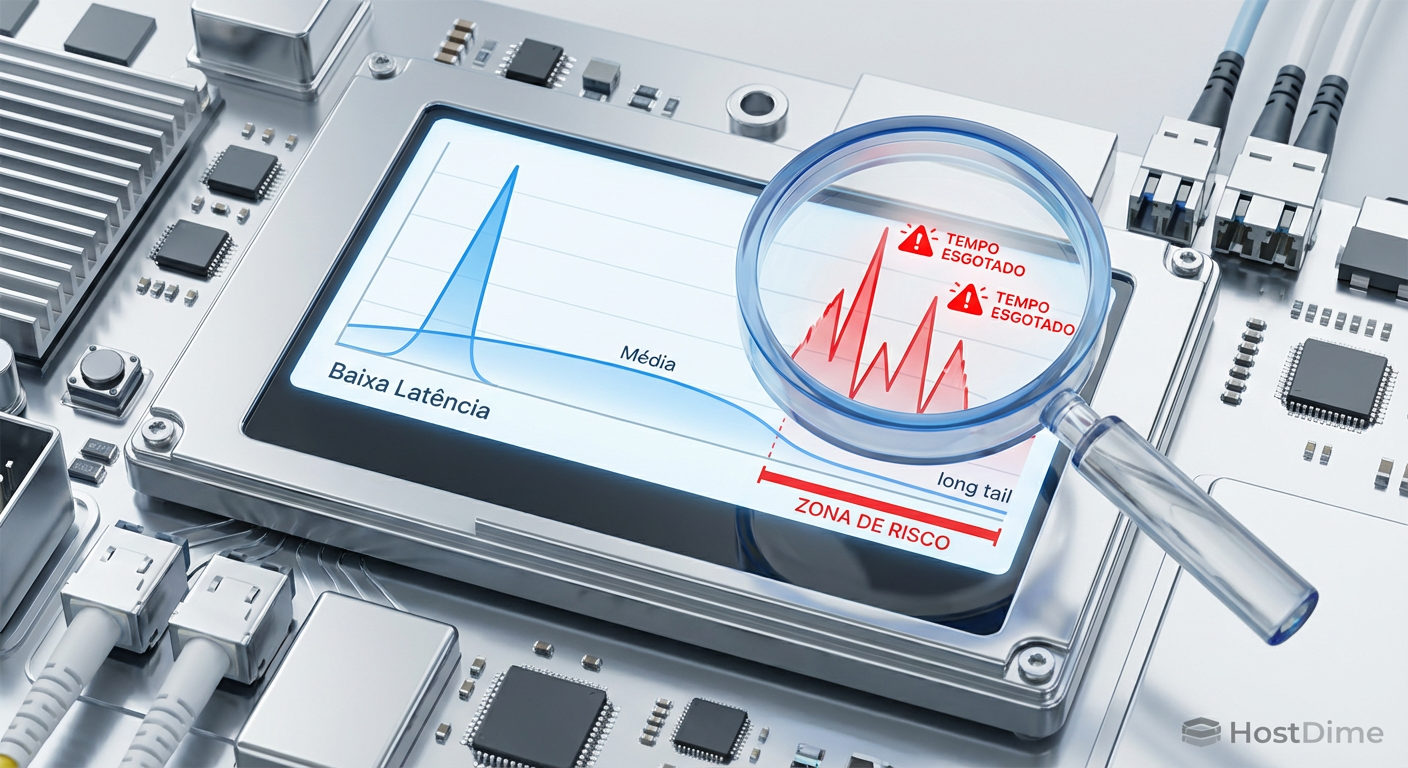 Figura: Visualização gráfica da distribuição de latência destacando a diferença entre a média segura e a cauda longa onde ocorrem os timeouts.
Figura: Visualização gráfica da distribuição de latência destacando a diferença entre a média segura e a cauda longa onde ocorrem os timeouts.
Anatomia da pilha de armazenamento e o papel do eBPF
Para entender onde o tempo é gasto, precisamos olhar para o caminho do I/O no Linux. Quando uma aplicação solicita dados, a requisição passa pelo VFS (Virtual File System), desce para a camada de bloco (Block Layer), entra nas filas do agendador (Scheduler/Elevator), passa pelo driver (ex: nvme) e finalmente chega ao hardware.
Ferramentas legadas observam contadores na camada de bloco. O eBPF (Extended Berkeley Packet Filter) muda o jogo ao permitir a execução de programas seguros e isolados dentro do kernel, acoplados a eventos específicos (kprobes ou tracepoints).
Podemos inserir sondas no início e no fim de uma requisição de bloco (block_rq_issue e block_rq_complete). Ao calcular a diferença de tempo (delta) para cada I/O individualmente, construímos um mapa real do comportamento do storage, não uma aproximação. Isso é feito com overhead insignificante, pois o eBPF roda em código de máquina compilado JIT (Just-In-Time) dentro do kernel, evitando a custosa troca de contexto para o espaço do usuário a cada evento.
Ferramentas essenciais: biolatency e biosnoop
No toolkit BCC (BPF Compiler Collection), duas ferramentas se destacam para análise de storage:
1. Biolatency: A visão macroscópica
Em vez de imprimir cada evento (o que seria ilegível em discos rápidos), o biolatency agrega os tempos de resposta em um histograma em memória no kernel e envia apenas o resumo para o usuário.
Exemplo de saída de um cenário real de degradação:
Tracing block device I/O... Hit Ctrl-C to end.
^C
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 0 | |
16 -> 31 : 12 | |
32 -> 63 : 854 |** |
64 -> 127 : 14201 |****************************************|
128 -> 255 : 6102 |***************** |
256 -> 511 : 124 | |
512 -> 1023 : 8 | |
1024 -> 2047 : 2 | |
2048 -> 4095 : 0 | |
4096 -> 8191 : 0 | |
8192 -> 16383 : 1 | |
16384 -> 32767 : 35 | |
Note a distribuição bimodal. A maioria das requisições está entre 64-255 microsegundos (excelente para SSDs). Mas observe o final: temos 35 requisições entre 16ms e 32ms. Se o seu banco de dados tem um timeout interno rigoroso para commits de log, essas 35 operações são as culpadas pelos erros na aplicação, mesmo que representem menos de 0,1% do tráfego total. O iostat jamais mostraria isso.
💡 Dica Pro: Use a flag
-Dno biolatency para ver a latência por disco individualmente. Em arrays RAID ou ambientes com múltiplos LUNs, um único disco defeituoso pode estar causando a latência de cauda de todo o grupo.
2. Biosnoop: A visão microscópica
Quando você identifica que existe latência de cauda com o biolatency, usa o biosnoop para identificar quem e o quê. Ele imprime cada operação de I/O conforme ela é completada.
TIME(s) COMM PID DISK T SECTOR BYTES LAT(ms)
0.000000 mysqld 1422 nvme0n1 W 242342 16384 0.14
0.000421 kworker/u32:2 231 nvme0n1 W 123123 4096 18.52
0.000512 mysqld 1422 nvme0n1 R 555222 8192 0.12
Aqui vemos que um processo kworker (possivelmente um flush de journal do sistema de arquivos ou compactação) causou uma escrita de 18ms, competindo com o mysqld. Isso permite correlacionar picos de latência com tarefas de manutenção do sistema ou backups agendados.
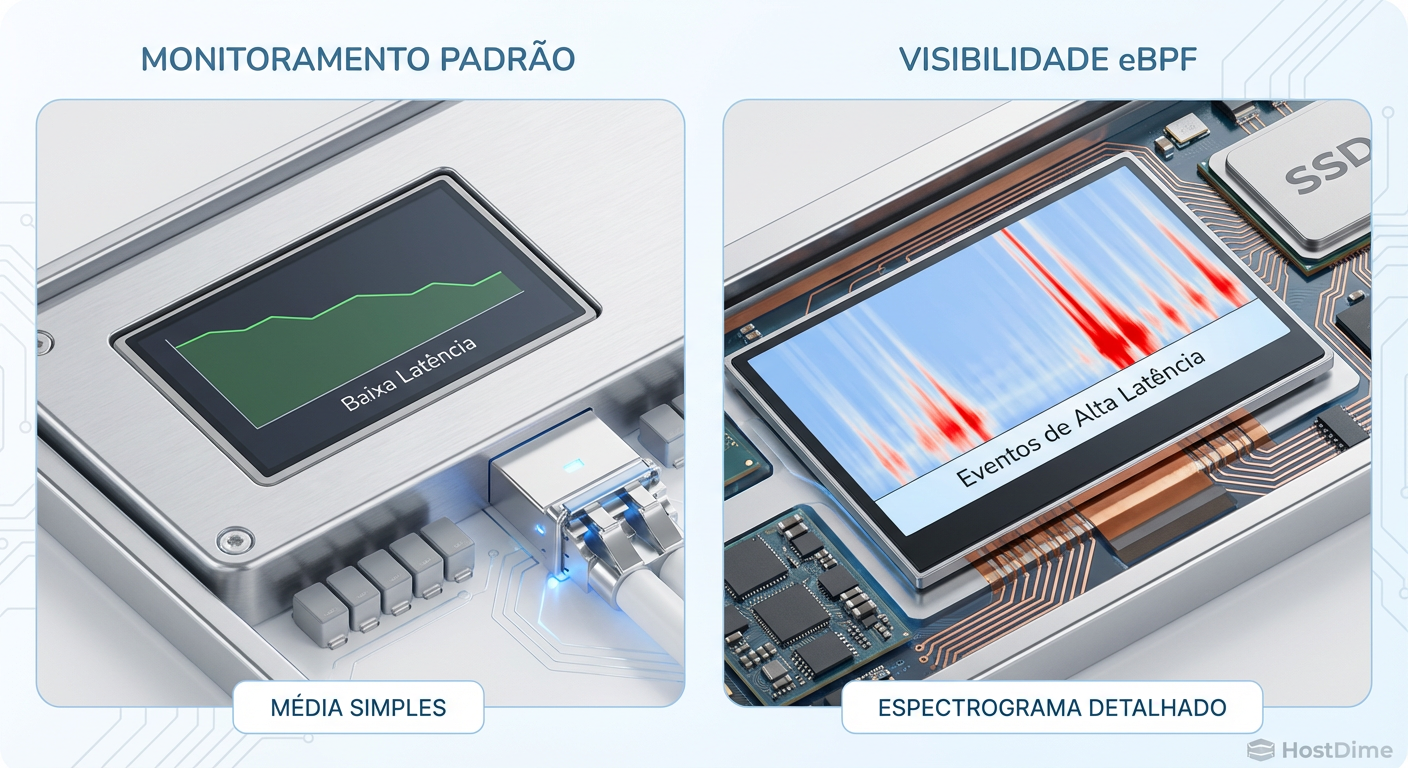 Figura: Comparativo visual entre monitoramento padrão e visibilidade eBPF, mostrando como mapas de calor revelam picos invisíveis em gráficos de linha.
Figura: Comparativo visual entre monitoramento padrão e visibilidade eBPF, mostrando como mapas de calor revelam picos invisíveis em gráficos de linha.
Comparativo: Ferramentas Tradicionais vs. eBPF
Para o engenheiro de storage, saber quando usar cada ferramenta é vital. A tabela abaixo resume as diferenças operacionais.
| Característica | iostat / sar | iotop | eBPF (biolatency/biosnoop) |
|---|---|---|---|
| Fonte de Dados | /proc/diskstats (contadores) |
/proc/vmstat e taskstats |
Eventos do Kernel (kprobes/tracepoints) |
| Granularidade | Média por intervalo de tempo | Por processo (agregado) | Por operação de I/O individual |
| Custo (Overhead) | Quase zero | Baixo/Médio | Baixo (graças ao JIT/Mapas) |
| Visibilidade de Cauda | Nenhuma (apenas médias) | Nenhuma | Total (Histogramas e P99) |
| Contexto | Apenas dispositivo | Apenas processo | Processo, Dispositivo, Latência, Tipo |
Implementando SLOs baseados em distribuição
A cultura de SRE dita que devemos monitorar o que importa para o usuário. O usuário não se importa com a média. Ele se importa se a requisição dele foi lenta. Portanto, seus SLIs (Service Level Indicators) de storage devem evoluir.
Em vez de:
- "A latência média de disco deve ser < 5ms."
Adote:
"99% das operações de leitura (p99) devem completar em < 10ms."
"99,9% das operações de escrita (p99.9) devem completar em < 50ms."
Ao configurar alertas baseados nesses percentis (extraídos via eBPF exporter para Prometheus, por exemplo), você será notificado sobre a degradação da experiência real muito antes de o disco atingir 100% de utilização ou a média subir significativamente.
⚠️ Perigo: Cuidado ao usar
biosnoopem produção com discos extremamente rápidos (ex: Optane ou NVMe Gen5) sob carga máxima. Imprimir texto no terminal para milhões de IOPS pode causar overhead na CPU (espaço do usuário). Prefira semprebiolatency(histogramas) para monitoramento contínuo e deixe obiosnooppara diagnósticos pontuais de curta duração.
O futuro da observabilidade em storage
A era de olhar apenas para "IOPS" e "Throughput" acabou. Com a chegada de tecnologias como CXL (Compute Express Link) e SSDs ZNS (Zoned Namespaces), a complexidade da pilha de I/O aumentará. A latência não será mais apenas "lento ou rápido", mas dependerá de localidade de dados, congestionamento de barramento PCIe e interação com o garbage collection do dispositivo.
Para o SRE focado em dados, dominar o eBPF não é mais um diferencial, é um requisito de sobrevivência. A capacidade de dissecar a latência de cauda é o que separa quem reinicia o servidor esperando que o problema suma, de quem identifica a causa raiz e blinda a infraestrutura contra a recorrência.
Referências & Leitura Complementar
Gregg, Brendan. BPF Performance Tools. Addison-Wesley Professional, 2019. (A bíblia da observabilidade moderna).
Kernel.org. Linux Block IO Controller Documentation. Disponível na documentação oficial do kernel Linux (cgroup-v2).
NVMe Express. NVM Express Base Specification. (Para entender os mecanismos de filas e latência interna de SSDs).
IOVisor Project. BCC - BPF Compiler Collection. Repositório oficial no GitHub contendo o código fonte do
biolatencyebiosnoop.
Perguntas Frequentes (FAQ)
Por que o iostat não mostra picos de latência?
O iostat exibe médias agregadas (como o 'await'). Um pico de 500ms diluído em milhares de operações rápidas de 0.1ms desaparece na média, mas ainda causa timeouts na aplicação. É a clássica falácia estatística onde a média esconde os extremos.O uso de eBPF causa overhead no servidor de produção?
O overhead é extremamente baixo e seguro para produção. O código eBPF é compilado JIT e verificado pelo kernel para garantir que não entre em loops infinitos ou trave o sistema. Diferente de ferramentas antigas como `strace` ou `tcpdump`, ele não copia dados massivos para o espaço do usuário a menos que solicitado.Qual a diferença entre biosnoop e biolatency?
O biosnoop imprime cada operação de I/O individualmente em tempo real (útil para debug pontual e correlação com PIDs), enquanto o biolatency agrega os dados em um histograma (melhor para análise de tendências, distribuição e monitoramento contínuo sem gerar logs excessivos).
Rafael Junqueira
Engenheiro de Confiabilidade (SRE)
"Transformo caos em estabilidade via observabilidade. Defensor da cultura blameless e focado em SLIs e SLOs. Se algo falhou, revisamos o sistema, nunca a pessoa."