
Ceph Arquitetura Basica E Quando Usar
Vamos ser honestos sobre o porquê de estarmos aqui. Ninguém acorda de manhã querendo gerenciar um cluster Ceph porque é "divertido". Nós fazemos isso porque a a...

Engenheiro de Confiabilidade (SRE)
Transformo caos em estabilidade via observabilidade. Defensor da cultura blameless e focado em SLIs e SLOs. Se algo falhou, revisamos o sistema, nunca a pessoa.
Vamos ser honestos sobre o porquê de estarmos aqui. Ninguém acorda de manhã querendo gerenciar um cluster Ceph porque é "divertido". Nós fazemos isso porque a a...

SSDs NVMe são vendidos como a oitava maravilha da velocidade, e, *na maioria das vezes*, entregam o prometido. Mas quando a performance despenca, a dor de cabeç...

A lentidão em compartilhamentos NFS (Network File System) é um problema recorrente que assombra administradores de sistemas e usuários finais. A experiência, ou...

A performance de I/O é frequentemente o gargalo em sistemas de computação. Discos mecânicos (HDDs) são inerentemente lentos em comparação com a memória RAM e a ...

Você recebe o alerta às 03:00 da manhã. O banco de dados principal parou de responder. O dashboard de monitoramento está vermelho, mas estranhamente, o servidor...

A escolha do `recordsize` no ZFS não é trivial; é um equilíbrio delicado entre desempenho, utilização de espaço e a natureza dos dados armazenados. Optar por u...

Descubra se o RAID 5 ainda vale a pena. Análise técnica de paridade, performance e riscos de reconstrução para Sysadmins veteranos.

Antes de rodar 'zfs set dedup=on', leia isto. Entenda a Tabela de Deduplicação (DDT), o custo brutal de RAM e por que compressão ZSTD é quase sempre a melhor escolha.
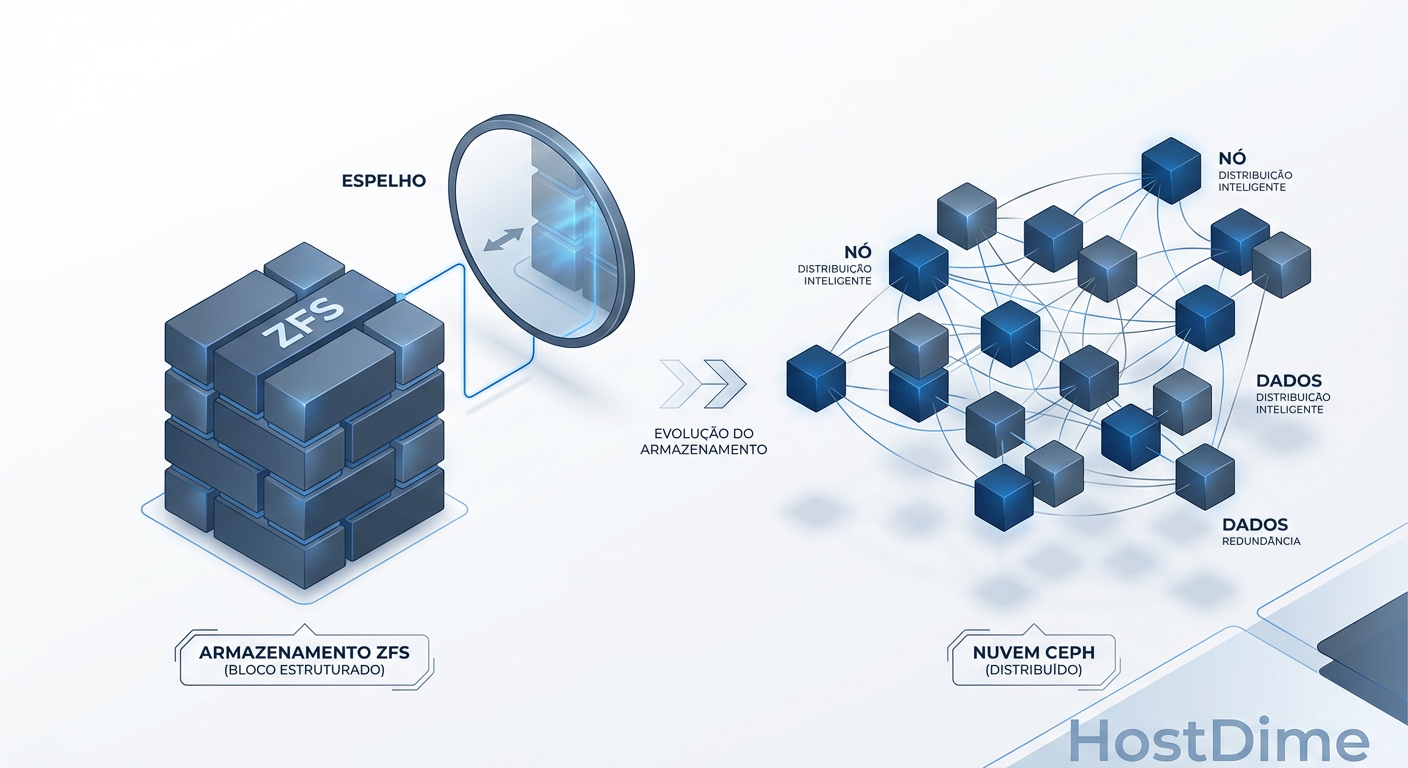
ZFS é rápido mas assíncrono. Ceph é robusto mas exige hardware. Uma análise profunda sobre latência, consistência e custos para decidir seu storage HA.
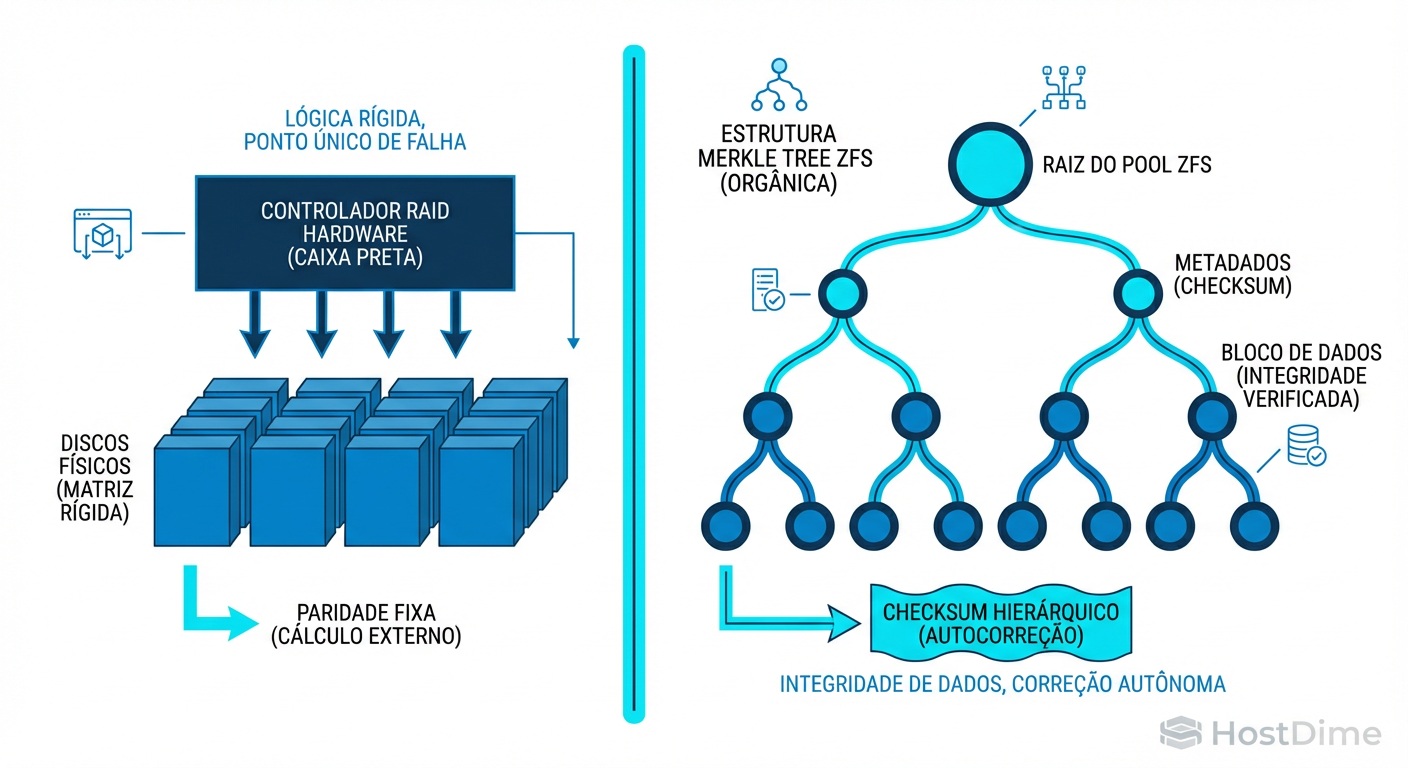
Hardware RAID protege o disco, ZFS protege o dado. Entenda o 'Write Hole', a árvore de Merkle e por que o RAID-Z elimina a corrupção silenciosa onde controladores tradicionais falham.

Esqueça o 'Watts por TB'. Descubra como a física dos drives HAMR/MAMR de alta capacidade impacta o cooling, o consumo real em RAID e por que seu rack pode derreter em 2026.
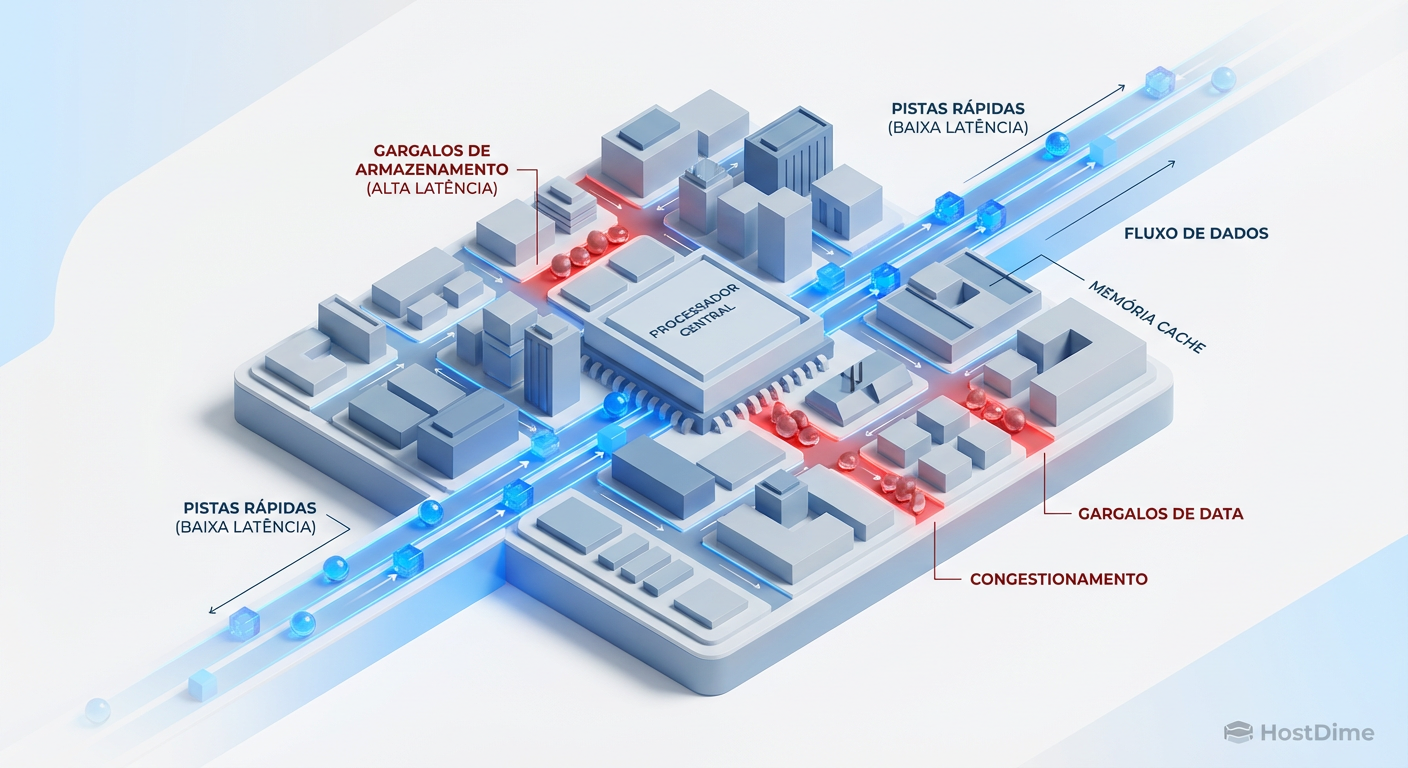
Suas VMs no Ceph estão lentas? Esqueça a largura de banda. Aprenda a tunar latência, cache RBD e Bluestore especificamente para Bancos de Dados, VDI e ERPs monolíticos.

"Até" é a palavra mais perigosa da tecnologia. Descubra como fabricantes manipulam baselines, caches e térmicas para inflar números de performance em 2025.

Descubra por que 2026 marca o fim dos HDDs para cargas de trabalho de IA e como montar um servidor doméstico com SSDs U.2 usados e NPUs acessíveis.

Aprenda a investigar gargalos de armazenamento no Linux usando eBPF. Descubra por que ferramentas como iostat falham em detectar latência de cauda e como usar histogramas para garantir seus SLOs.

Guia SRE para triagem de incidentes de latência em storage. Do alerta de SLO à análise de filas de I/O e saturação, eliminando a cultura de culpa.

Descubra como o padrão NVMe ZNS (TP 4053) elimina a amplificação de escrita, reduz a latência de cauda e viabiliza o uso de flash QLC em workloads de alta performance como RocksDB.

Aprenda a diagnosticar gargalos de I/O invisíveis ao iostat. Um guia de SRE para usar eBPF, biosnoop e biolatency na análise profunda do kernel Linux.

Descubra como a tecnologia NVMe Zoned Namespaces (ZNS) reduz a amplificação de escrita de 4x para 1x e estabiliza a latência p99 em bancos de dados de alta performance.

Descubra como mitigar a latência de cauda e a amplificação de escrita (WAF) em SSDs QLC usando Flexible Data Placement (FDP) e estratégias de SRE.

Vá além do iostat. Aprenda a usar eBPF (bcc/bpftrace) para rastrear I/O no kernel Linux, identificar latência de cauda e definir SLOs de armazenamento precisos.

Análise SRE sobre o risco de falhas simultâneas em arrays de SSDs idênticos. Entenda a matemática do desgaste da NAND e como evitar a perda catastrófica de dados.
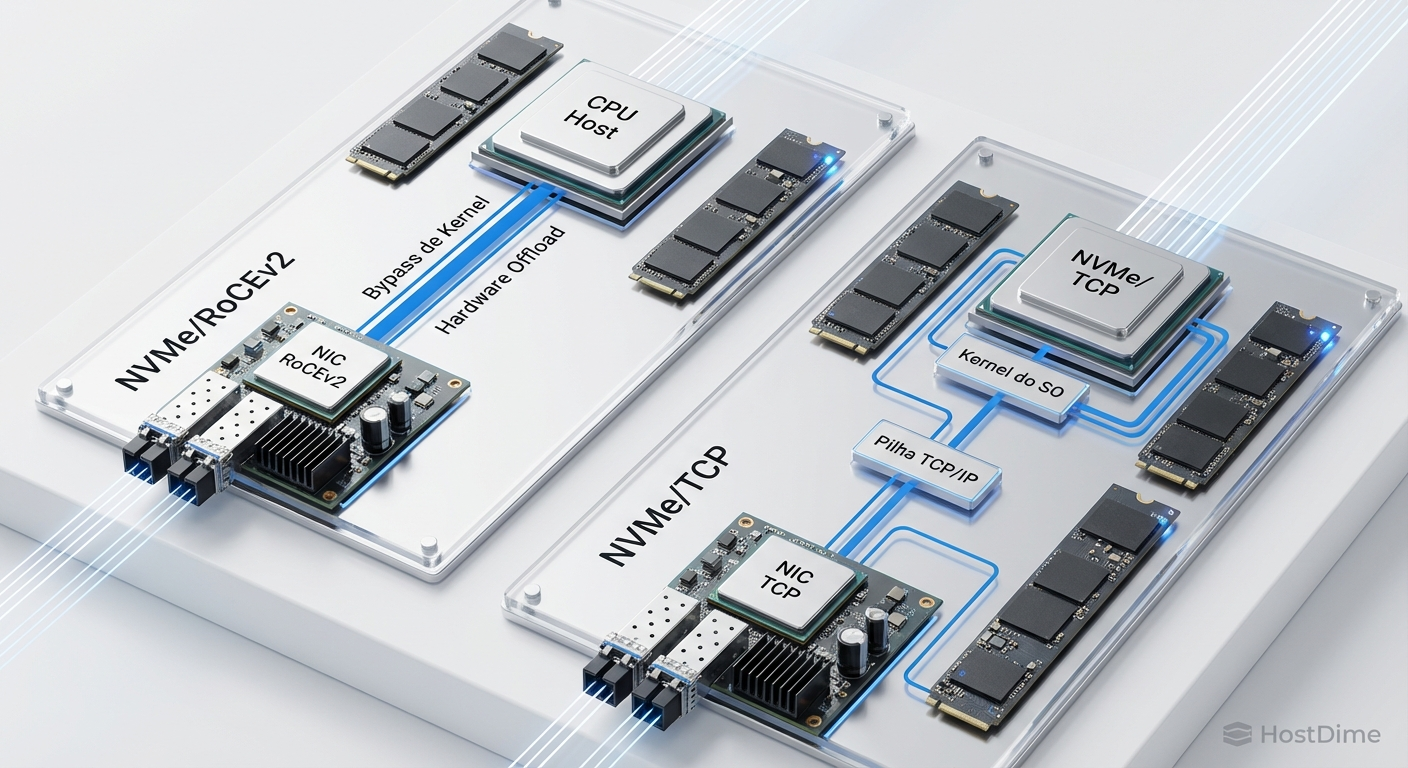
Análise de SRE sobre como o Priority Flow Control pode paralisar infraestruturas de storage NVMe-oF. Aprenda a identificar tempestades de broadcast e configurar watchdogs para garantir a confiabilidade do RoCEv2.

Descubra como aplicar engenharia do caos no armazenamento do etcd. Aprenda a injetar latência de fsync para testar a resiliência do control plane do Kubernetes e evitar quedas em produção.

Aprenda como diagnosticar pods travados no Kubernetes devido a gargalos de storage. Use eBPF para rastrear o estado D (Uninterruptible Sleep) e recupere seus SLOs.