Domando a Latência de Cauda: Como SSDs ZNS Eliminam a Amplificação de Escrita

Descubra como a tecnologia NVMe Zoned Namespaces (ZNS) reduz a amplificação de escrita de 4x para 1x e estabiliza a latência p99 em bancos de dados de alta performance.
Você conhece o cenário: o pager toca às 3 da manhã. O dashboard mostra que o p99 da latência do seu banco de dados disparou de 5ms para 200ms. A CPU está ociosa, a memória está estável e a rede está limpa. Você culpa o banco de dados, reinicia o serviço e o problema desaparece, apenas para voltar 48 horas depois.
O culpado não é seu código, nem o kernel do Linux. O problema reside no firmware do seu SSD e em um processo invisível chamado Garbage Collection. Para engenheiros de confiabilidade (SREs) focados em SLOs (Service Level Objectives) rigorosos, entender como o armazenamento gerencia os dados fisicamente deixou de ser opcional.
A introdução dos Zoned Namespaces (ZNS) na especificação NVMe representa a mudança mais significativa na arquitetura de armazenamento da última década, prometendo eliminar a imprevisibilidade dos SSDs convencionais.
Resumo em 30 segundos
- O Problema: SSDs tradicionais sofrem com picos de latência imprevisíveis causados pelo Garbage Collection interno e pela camada de tradução (FTL).
- A Solução: O ZNS (Zoned Namespaces) remove essa camada de abstração, permitindo que o host (SO ou aplicação) escreva dados sequencialmente em zonas isoladas.
- O Resultado: Redução do Fator de Amplificação de Escrita (WAF) de ~4x para ~1x, latência determinística e aumento drástico na vida útil do drive.
O mistério da latência de cauda em SSDs
Em sistemas distribuídos, a média é uma métrica mentirosa. O que mata a experiência do usuário (e viola seu SLA) é a latência de cauda (tail latency) — aquelas requisições que caem no percentil 99 (p99) ou 99.9 (p99.9).
Nos SSDs convencionais, a latência de leitura/escrita é incrivelmente baixa na maior parte do tempo. No entanto, periodicamente, uma operação de escrita simples pode demorar 100 vezes mais do que o normal. Isso ocorre devido à Flash Translation Layer (FTL).
A anatomia do problema: FTL e Garbage Collection
A memória NAND Flash tem uma limitação física: você pode ler e escrever em páginas (geralmente 4KB ou 16KB), mas só pode apagar em blocos (que contêm centenas de páginas). Como não podemos sobrescrever dados no local (in-place update), o SSD grava os novos dados em um novo local e marca o antigo como "inválido".
Com o tempo, o disco fica cheio de "buracos" de dados inválidos. A FTL precisa parar o que está fazendo, copiar os dados válidos restantes para um novo bloco e apagar o bloco antigo para liberar espaço. Esse processo é o Garbage Collection (GC).
⚠️ Perigo: Quando o GC é ativado, ele compete por recursos internos do SSD e largura de banda da NAND. Se uma escrita do seu banco de dados chegar nesse exato momento, ela ficará na fila esperando a "limpeza" terminar. É aí que seu p99 explode.
 Figura: Comparação visual: O caos do Garbage Collection em SSDs tradicionais versus a organização sequencial das Zonas ZNS.
Figura: Comparação visual: O caos do Garbage Collection em SSDs tradicionais versus a organização sequencial das Zonas ZNS.
Zoned Namespaces (ZNS): quebrando a abstração
Para resolver isso, a indústria (liderada por membros da SNIA e NVMe Express) decidiu que o SSD não deveria tentar ser inteligente sozinho. O ZNS é uma extensão do protocolo NVMe que expõe a geometria do armazenamento diretamente para o host.
Em vez de um espaço de endereçamento linear infinito onde você pode escrever em qualquer lugar (LBA 0 a LBA N), o ZNS divide o drive em Zonas.
As regras do jogo ZNS
Escrita Sequencial Obrigatória: Dentro de uma zona, você deve escrever sequencialmente. Se você escreveu no LBA 0, o próximo deve ser o LBA 1.
Reset de Zona: Para sobrescrever dados, você deve "resetar" (apagar) a zona inteira.
Sem FTL Complexa: Como o host garante a sequencialidade, o SSD não precisa de uma tabela de mapeamento gigante nem de GC agressivo em segundo plano.
Ao transferir a responsabilidade da organização dos dados para o software (Host-Managed), eliminamos a "caixa preta" que causa a latência imprevisível.
Amplificação de escrita (WAF) e o custo oculto
O Fator de Amplificação de Escrita (WAF) é a razão entre a quantidade de dados que o drive escreve fisicamente na NAND e a quantidade de dados que o host solicitou.
Em um cenário ideal, WAF = 1. Em SSDs Enterprise com cargas aleatórias (ex: bancos de dados transacionais), o WAF frequentemente varia entre 3 e 4. Isso significa que para cada 1TB que você grava, o SSD gasta 4TB de sua vida útil (devido às movimentações internas do GC).
Com ZNS, como as escritas são sempre sequenciais dentro da zona e o alinhamento é feito pelo host, o WAF cai para valores próximos de 1.1.
💡 Dica Pro: Reduzir o WAF de 3 para 1 triplica a vida útil do seu SSD. Isso permite comprar drives com menor Endurance (DWPD - Drive Writes Per Day) para a mesma carga de trabalho, gerando economia direta de CAPEX.
Tabela Comparativa: SSD Convencional vs. ZNS
| Característica | SSD Convencional (Block Interface) | SSD ZNS (Zoned Namespaces) |
|---|---|---|
| Gerenciamento de Dados | Drive-Managed (FTL complexa) | Host-Managed (Software define) |
| Padrão de Escrita | Aleatório permitido em qualquer LBA | Sequencial obrigatório por zona |
| Garbage Collection | Interno, imprevisível, causa latência | Gerenciado pelo Host, previsível |
| Uso de DRAM no SSD | Alto (1GB DRAM por 1TB Storage) | Muito Baixo (Tabela de mapeamento mínima) |
| Over-provisioning (OP) | Necessário (~7% a 28%) | Quase nulo (~0%) |
| WAF Típico (Random I/O) | 3.0x - 4.0x | ~1.1x |
| Latência de Cauda (p99) | Alta e variável | Baixa e determinística |
O fim do over-provisioning excessivo
Para mitigar o impacto do GC, engenheiros de storage costumam deixar uma grande parte do disco não formatada ou reservada, técnica chamada de Over-provisioning (OP). Em SSDs de alta performance, é comum sacrificar 28% da capacidade apenas para dar "espaço de manobra" ao controlador.
Com ZNS, a necessidade de OP desaparece quase completamente. Como não há movimentação de dados oculta, você pode utilizar a capacidade total da NAND Flash instalada. Em um datacenter com petabytes de dados, recuperar 28% de capacidade sem comprar hardware novo é uma vitória massiva de eficiência.
Implementação no mundo real: RocksDB e ZenFS
A teoria é linda, mas como isso roda em produção? O caso de uso mais famoso é o RocksDB, um banco de dados chave-valor baseado em LSM-Tree (Log-Structured Merge-tree), usado como backend por gigantes como Facebook e LinkedIn.
O RocksDB naturalmente gera dados de forma sequencial (SSTables). No entanto, ao rodar sobre um sistema de arquivos tradicional (ext4/xfs) em um SSD convencional, ocorre o fenômeno "Log-on-Log":
O RocksDB tenta ser sequencial.
O Filesystem fragmenta os dados.
O SSD tenta reorganizar os blocos.
Isso gera uma redundância de esforços. Para resolver isso, foi criado o ZenFS, um backend de sistema de arquivos que permite ao RocksDB falar diretamente com as zonas do ZNS.
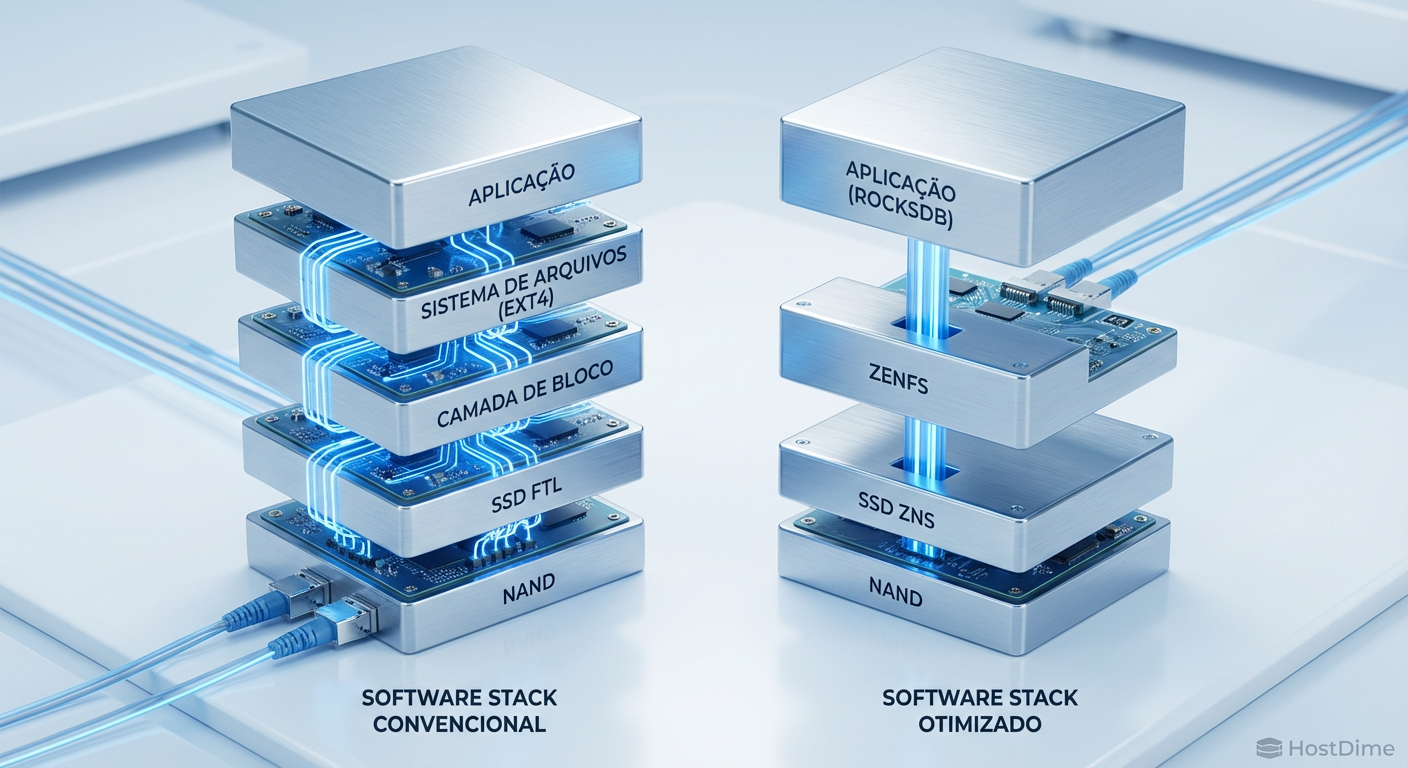 Figura: A pilha de software simplificada: ZenFS conecta a aplicação diretamente à geometria física do armazenamento.
Figura: A pilha de software simplificada: ZenFS conecta a aplicação diretamente à geometria física do armazenamento.
Ao usar ZenFS + ZNS, o RocksDB aloca uma SSTable inteira para uma Zona ZNS. Quando a SSTable precisa ser deletada, o RocksDB simplesmente envia um comando de "Zone Reset". O WAF do sistema cai drasticamente e a latência se torna uma linha reta.
O futuro é zoneado
A adoção de ZNS não é apenas uma troca de hardware; é uma mudança de paradigma na arquitetura de sistemas. Estamos saindo de uma era onde o hardware era uma caixa preta mágica para uma era onde o software tem controle granular sobre a física do armazenamento.
Para o Engenheiro de Confiabilidade, ZNS oferece a ferramenta definitiva para estabilidade: determinismo. Saber que uma escrita levará X microssegundos, independentemente do estado anterior do disco, permite construir SLOs mais agressivos e confiáveis.
Se sua infraestrutura lida com ingestão massiva de dados, logs de alta frequência ou bancos de dados baseados em LSM-Tree, a migração para ZNS deve estar no seu radar de arquitetura para os próximos ciclos de renovação de hardware.
Referências & Leitura Complementar
NVM Express Base Specification 2.0: Seção sobre Zoned Namespaces Command Set.
NVMe TP 4053: A proposta técnica original que padronizou o ZNS.
SNIA (Storage Networking Industry Association): Whitepapers sobre Zoned Storage e SMR/ZNS.
Western Digital & Dropbox: "ZNS: Avoiding the Block Interface Tax for Flash-based SSDs" (USENIX ATC '21).
Kernel.org: Documentação do Linux sobre suporte a Zoned Block Devices (
dm-zoned,zonefs).
O que é NVMe Zoned Namespaces (ZNS)?
ZNS é uma extensão da especificação NVMe (TP 4053) que divide o espaço de armazenamento do SSD em zonas distintas. Diferente dos SSDs convencionais, onde o drive gerencia a alocação de dados, no ZNS o host (sistema operacional ou aplicação) deve escrever dados sequencialmente em cada zona, eliminando a necessidade de Garbage Collection interno agressivo.Como o ZNS reduz a latência de cauda (Tail Latency)?
Ao remover o processo de Garbage Collection (GC) imprevisível de dentro do firmware do SSD, o ZNS elimina as pausas de I/O que ocorrem quando o drive está reorganizando dados internamente. Isso torna a latência de escrita determinística, estabilizando métricas críticas como o p99 e p99.9.Qual a diferença de WAF entre um SSD convencional e um ZNS?
Em cargas de trabalho aleatórias intensas (como RocksDB), um SSD convencional pode ter um Fator de Amplificação de Escrita (WAF) entre 3x e 4x. Com ZNS, como as escritas são sequenciais e gerenciadas pelo host, o WAF cai para valores próximos de 1.1x, aumentando drasticamente a vida útil do dispositivo.O ZNS funciona com qualquer sistema de arquivos?
Não nativamente com todos. Sistemas de arquivos tradicionais (como ext4) precisam de adaptações ou camadas de emulação (dm-zoned). No entanto, sistemas modernos como F2FS e backends de banco de dados específicos (como ZenFS para RocksDB) já possuem suporte nativo para explorar o máximo desempenho do ZNS.
Rafael Junqueira
Engenheiro de Confiabilidade (SRE)
"Transformo caos em estabilidade via observabilidade. Defensor da cultura blameless e focado em SLIs e SLOs. Se algo falhou, revisamos o sistema, nunca a pessoa."