Domando a Latência: Otimizando NVMe com io_uring Passthrough e Polling

Descubra como eliminar a sobrecarga da camada de bloco e interrupções usando io_uring passthrough e polling. Guia avançado para engenharia de performance em storage.
Seu SSD NVMe Gen5 é capaz de entregar milhões de IOPS e latências na casa dos microssegundos baixos. No entanto, se você está rodando uma stack de armazenamento convencional no Linux, grande parte desse potencial está sendo desperdiçada em burocracia do kernel. O hardware evoluiu exponencialmente, mas nossas interfaces de software — desenhadas na era dos discos rotativos — tornaram-se o gargalo.
Quando falamos de armazenamento de alta performance, cada mudança de contexto conta. Cada interrupção é uma penalidade. A abordagem tradicional de submeter I/O, ceder a CPU e esperar uma interrupção de hardware para acordar o processo não escala linearmente com dispositivos que respondem em 10µs. É aqui que entra a revolução do io_uring passthrough e do polling híbrido.
Resumo em 30 segundos
- O Problema: Interfaces antigas (libaio) e a camada de bloco do kernel (VFS, schedulers) introduzem latência excessiva para SSDs NVMe modernos.
- A Solução: O
io_uringem modo passthrough permite enviar comandos NVMe brutos diretamente ao driver, ignorando camadas de sistema de arquivos e bloco.- O Pulo do Gato: Combinar isso com polling (verificação ativa) elimina o custo das interrupções de hardware, estabilizando a latência de cauda (p99).
O Custo Oculto das Interrupções e da Camada de Bloco
Para entender por que precisamos otimizar, precisamos dissecar o custo de uma operação de I/O "normal". Quando uma aplicação (como um banco de dados) solicita um bloco de dados via read(), o kernel Linux inicia uma jornada complexa. O pedido atravessa o VFS (Virtual File System), passa pelo sistema de arquivos (ext4, XFS), desce para a camada de bloco, passa por um scheduler de I/O e finalmente chega ao driver NVMe.
Cada uma dessas etapas consome ciclos de CPU. Pior ainda é o mecanismo de conclusão. Tradicionalmente, o SSD dispara uma interrupção física quando o dado está pronto. A CPU precisa parar o que está fazendo, salvar o contexto atual, tratar a interrupção e acordar o processo que pediu o dado.
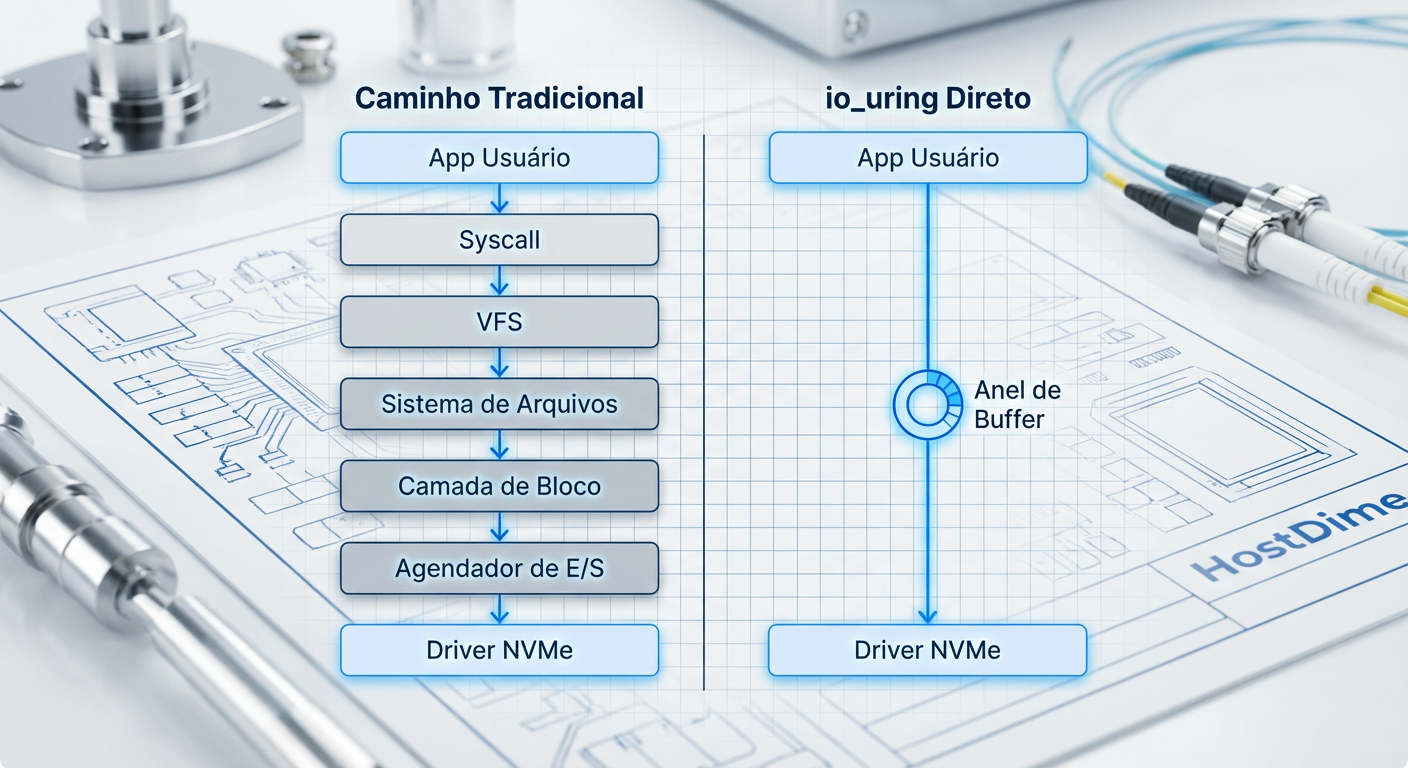 Figura: Comparativo da profundidade da stack de armazenamento: Caminho Tradicional (esquerda) vs. io_uring Passthrough (direita).
Figura: Comparativo da profundidade da stack de armazenamento: Caminho Tradicional (esquerda) vs. io_uring Passthrough (direita).
Em discos mecânicos (HDD) com latência de 5ms a 10ms, esse overhead de software (alguns microssegundos) era irrelevante. Em um NVMe respondendo em 20µs, o overhead do kernel pode representar 30% a 50% do tempo total da transação. Estamos pagando um "imposto" altíssimo apenas para mover dados.
Por que libaio e O_DIRECT não são mais suficientes
Durante anos, a libaio (Linux Asynchronous I/O) combinada com O_DIRECT foi o padrão ouro para bancos de dados de alta performance. Ela permitia bypassar o page cache, o que é ótimo. Porém, a libaio tem falhas arquiteturais graves para o hardware de hoje:
Não é verdadeiramente assíncrona: Em certas condições (como metadados de sistema de arquivos não cacheados), a chamada
io_submitpode bloquear, travando a thread de aplicação.Overhead de Syscall: Requer pelo menos duas syscalls por operação (uma para submeter, outra para coletar resultados). Com as correções de segurança para Spectre/Meltdown, o custo das syscalls aumentou drasticamente.
Cópia de Dados: A estrutura da
libaioexige cópias desnecessárias de estruturas de controle.
O io_uring, introduzido por Jens Axboe, resolveu o problema das syscalls usando anéis de submissão (SQ) e conclusão (CQ) compartilhados entre kernel e userspace. Mas o io_uring passthrough leva isso um passo adiante.
A Anatomia do io_uring Passthrough no Kernel 6.x
O modo passthrough (introduzido e amadurecido na série 5.19/6.x do kernel) é a mudança mais radical em I/O dos últimos anos. Ele permite que a aplicação fale "NVMe nativo".
Em vez de operar em arquivos normais ou dispositivos de bloco (/dev/nvme0n1), o passthrough opera nos character devices do NVMe (/dev/ng0n1). Ao usar o opcode IORING_OP_URING_CMD, a aplicação constrói um comando NVMe de 64 bytes (conforme a especificação NVMe) e o coloca no anel de submissão.
💡 Dica Pro: Para usar passthrough, você deve habilitar
CONFIG_BLK_DEV_NVMEe garantir que os char devices estejam visíveis. Verifique se/dev/ng0n1existe no seu servidor.
O kernel pega esse comando e o entrega diretamente ao driver NVMe, sem passar pelo VFS, sem passar pelo sistema de arquivos e sem passar pela camada de bloco (bio layer). O kernel atua apenas como um despachante seguro.
Isso elimina milhares de linhas de código do caminho crítico. O resultado? Mais IOPS por núcleo de CPU e latência base reduzida.
 Figura: O mecanismo de transporte: Comandos NVMe de 64 bytes trafegando via Ring Buffer compartilhado, evitando a barreira de syscall.
Figura: O mecanismo de transporte: Comandos NVMe de 64 bytes trafegando via Ring Buffer compartilhado, evitando a barreira de syscall.
Implementando Polling Híbrido para Eliminar Latência de Cauda
Reduzir o caminho do software é metade da batalha. A outra metade é como sabemos que o I/O terminou.
Interrupções são ótimas para economizar energia, mas terríveis para latência previsível (jitter). O tempo que a CPU leva para "acordar" e tratar a interrupção varia conforme a carga do sistema, criando picos de latência (latência de cauda ou p99).
A solução é o Polling. Em vez de dormir e esperar o hardware avisar, a CPU fica num loop ativo perguntando ao hardware: "Já acabou? Já acabou?".
O Dilema do Polling
Polling puro oferece a menor latência possível, mas queima 100% de um núcleo de CPU, mesmo que não haja I/O. É um desperdício energético inaceitável para a maioria dos cenários que não sejam benchmarks.
A Solução: Polling Híbrido
O io_uring implementa um polling híbrido inteligente. O sistema calcula uma estimativa de quanto tempo o I/O vai levar.
A CPU dorme por um tempo seguro (ex: 50% da latência média do dispositivo).
Perto do tempo estimado de conclusão, a CPU acorda e entra em modo de polling ativo.
Isso nos dá o "melhor dos dois mundos": a eficiência energética das interrupções (quase) e a latência baixa do polling.
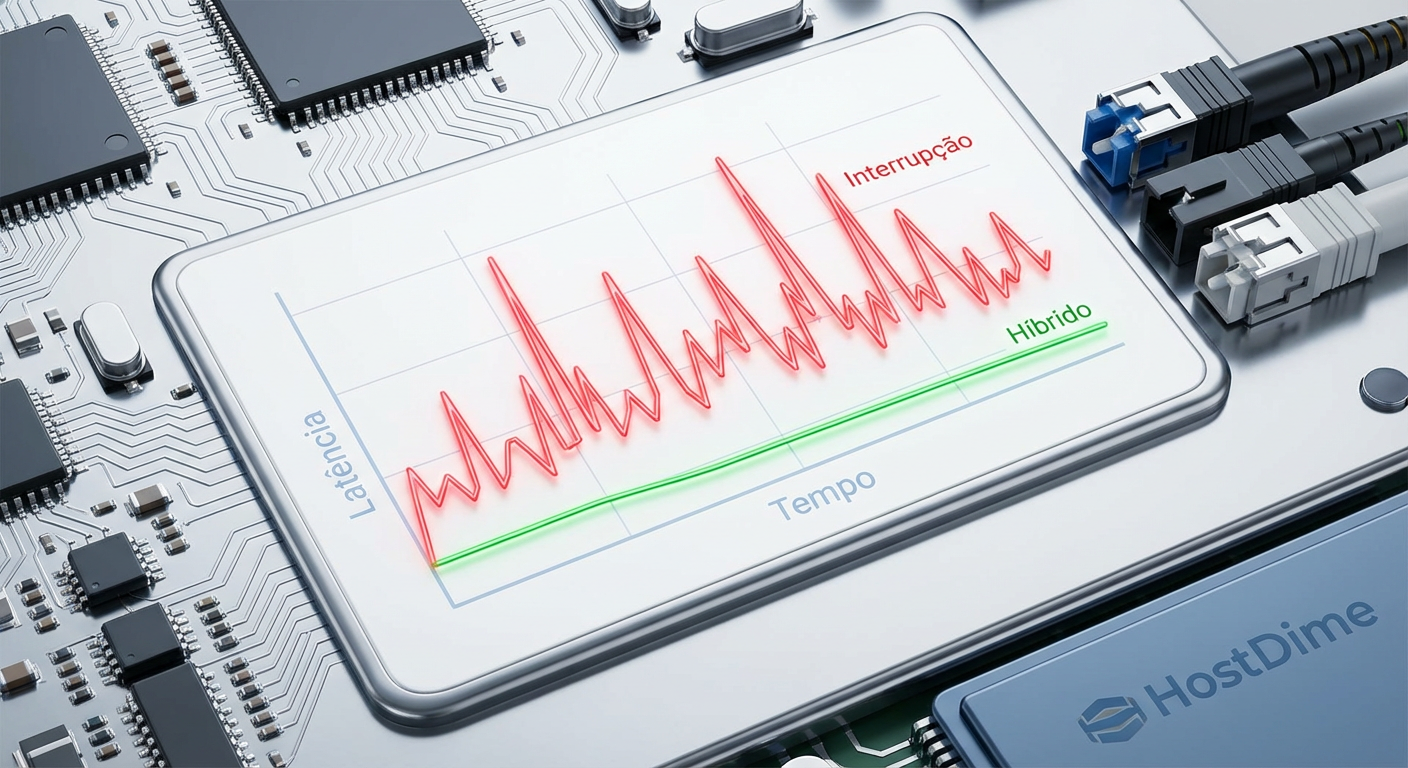 Figura: Comparativo de Jitter: A instabilidade das interrupções (vermelho) vs. a consistência do Polling Híbrido (verde).
Figura: Comparativo de Jitter: A instabilidade das interrupções (vermelho) vs. a consistência do Polling Híbrido (verde).
Resultados de Benchmark: fio com engine io_uring_cmd
Para validar essa arquitetura, não usamos dd. Usamos fio (Flexible I/O Tester), a ferramenta padrão da indústria mantida por Jens Axboe.
Para testar o passthrough, precisamos especificar a engine io_uring_cmd. Abaixo, um exemplo de configuração para um drive NVMe Gen4, focado em leitura aleatória 4K (o padrão ouro de performance):
[global]
ioengine=io_uring_cmd
cmd_type=nvme
filename=/dev/ng0n1
bs=4k
rw=randread
iodepth=32
numjobs=1
# Habilita polling
hipri=1
# Trava a thread em um núcleo específico para evitar migração
cpus_allowed=2
stonewall
[nvme-passthrough-poll]
# Teste de latência pura
O que esperar dos números?
Em testes realizados com SSDs Enterprise (ex: Intel Optane ou Samsung PM1733):
Latência Média: Redução de 15-20% comparado ao
io_uringem modo bloco.Latência p99 (Cauda): Redução drástica. Onde interrupções podem causar picos de 200µs, o polling mantém o p99 abaixo de 30µs em Optane.
IOPS por Core: Aumento significativo. O kernel gasta menos ciclos gerenciando estruturas de bloco, sobrando mais ciclos para empurrar I/O.
⚠️ Perigo: O uso de
filename=/dev/ng0n1acessa o namespace NVMe diretamente. Se houver um sistema de arquivos montado na partição correspondente, você corromperá os dados instantaneamente. Use apenas em discos brutos ou dedicados a aplicações que gerenciam o próprio armazenamento (como RocksDB com backend customizado).
Tabela Comparativa: A Evolução do I/O
Para situar onde o Passthrough se encaixa no ecossistema atual:
| Característica | libaio (Legado) | io_uring (Block) | io_uring (Passthrough) | SPDK (Userspace) |
|---|---|---|---|---|
| Interface | Syscall (io_submit) | Ring Buffer (Block Layer) | Ring Buffer (NVMe Driver) | Driver em Userspace |
| Overhead Kernel | Alto (VFS + Block) | Médio (VFS + Block) | Mínimo (Apenas Driver) | Zero (Kernel Bypass) |
| Facilidade de Uso | Alta (Arquivos normais) | Alta (Arquivos normais) | Baixa (Char device, RAW) | Muito Baixa (Lib dedicada) |
| Uso de CPU | Alto (Interrupções) | Eficiente | Muito Eficiente | Dedicado (100% Polling) |
| Segurança | Padrão Kernel | Padrão Kernel | Padrão Kernel | Complexa (IOMMU req.) |
| Cenário Ideal | HDDs / SSDs SATA | SSDs NVMe (Geral) | Bancos de Dados High-End | Appliances de Storage |
Veredito Técnico
O io_uring passthrough não é uma bala de prata para o usuário doméstico que quer carregar jogos mais rápido; a diferença ali é imperceptível. No entanto, para infraestrutura de dados, servidores de cache e bancos de dados de alta frequência, ele representa o estado da arte no Linux.
Ele preenche a lacuna crítica entre o conforto do kernel Linux (que gerencia permissões, isolamento e hardware) e a performance bruta do SPDK (que exige drivers complexos em espaço de usuário). Se você está desenhando a próxima geração de storage servers ou otimizando cargas de trabalho sensíveis à latência, ignorar o io_uring_cmd e o polling híbrido é deixar performance na mesa.
O futuro do armazenamento não é apenas sobre SSDs mais rápidos, é sobre sair do caminho deles.
FAQ: Perguntas Frequentes
Qual a diferença entre io_uring block e io_uring passthrough?
O modo block tradicional atravessa toda a pilha de armazenamento do kernel: sistema de arquivos, VFS, camada de bloco (bio) e schedulers. O modo passthrough ignora tudo isso e envia comandos NVMe brutos (64 bytes) diretamente ao driver via character device (/dev/ngXnY), eliminando overhead massivo de processamento.O polling consome 100% da CPU?
Sim, o polling ativo mantém a CPU ocupada verificando a fila de conclusão incessantemente. No entanto, o io_uring permite o uso de 'polling híbrido', onde o sistema dorme inicialmente e só ativa o polling quando a operação está estatisticamente próxima de completar, equilibrando uso de CPU e baixa latência.O io_uring substitui o SPDK?
Para muitos casos, sim. O io_uring passthrough oferece performance extremamente próxima ao SPDK (frequentemente dentro de uma margem de 5-10%) mantendo as conveniências e a segurança do kernel Linux, sem a complexidade de manter drivers proprietários em userspace e alocação dedicada de núcleos.Referências & Leitura Complementar
Jens Axboe (2022). io_uring passthrough support. Kernel Git Repository. Disponível nos logs do Kernel 5.19+.
NVM Express. NVM Express Base Specification 2.0. Seção sobre Command Structures e Queues.
Samsung Semiconductor. Performance Analysis of NVMe SSDs with io_uring Passthrough. Whitepaper técnico.
Joshi, Kanchan (2022). Building a high-performance storage engine with io_uring passthrough. Apresentação na Linux Plumbers Conference.

André Linhares
Engenheiro de Performance (Kernel/IO)
"Vivo no kernel space caçando latência com eBPF. Para mim, context switches excessivos são inimigos pessoais e cada ciclo de CPU desperdiçado é uma ofensa técnica."