Eliminando a Latência da Camada de Bloco com io_uring Passthrough em NVMe

Descubra como o io_uring passthrough (kernel 5.19+) elimina o overhead da camada de bloco, permitindo acesso direto ao hardware NVMe com latência mínima e máxima eficiência de CPU.
Eliminando a latência da camada de bloco com io_uring passthrough em NVMe
Estamos vivendo um paradoxo no armazenamento de alto desempenho. Temos dispositivos NVMe Gen5 capazes de entregar milhões de IOPS e latências na casa dos microssegundos, mas continuamos alimentando esses monstros com uma pilha de software desenhada na era dos discos rotativos. O hardware espera, ocioso, enquanto a CPU luta para processar estruturas de dados do kernel que, em muitos casos, são desnecessárias para cargas de trabalho modernas.
Se você já analisou um flamegraph de uma aplicação de banco de dados de alta performance e viu a CPU gastando 30% ou 40% do tempo em spinlocks dentro da camada de bloco (block layer) do Linux, você conhece a dor. A solução tradicional era abandonar o kernel e pular para drivers em user-space (como SPDK). Mas isso traz uma complexidade operacional brutal. A resposta moderna, elegante e integrada ao kernel é o io_uring passthrough.
Resumo em 30 segundos
- O Problema: A camada de bloco do Linux (block layer) introduz overhead de CPU significativo (alocação de bios, merges, escalonamento) que gargala SSDs NVMe modernos.
- A Solução: O modo passthrough do io_uring permite enviar comandos NVMe "crus" diretamente ao driver, ignorando a camada de bloco e o sistema de arquivos.
- O Resultado: Redução drástica na latência, aumento de IOPS por core e eficiência de CPU comparável ao SPDK, mas mantendo as facilidades do kernel Linux.
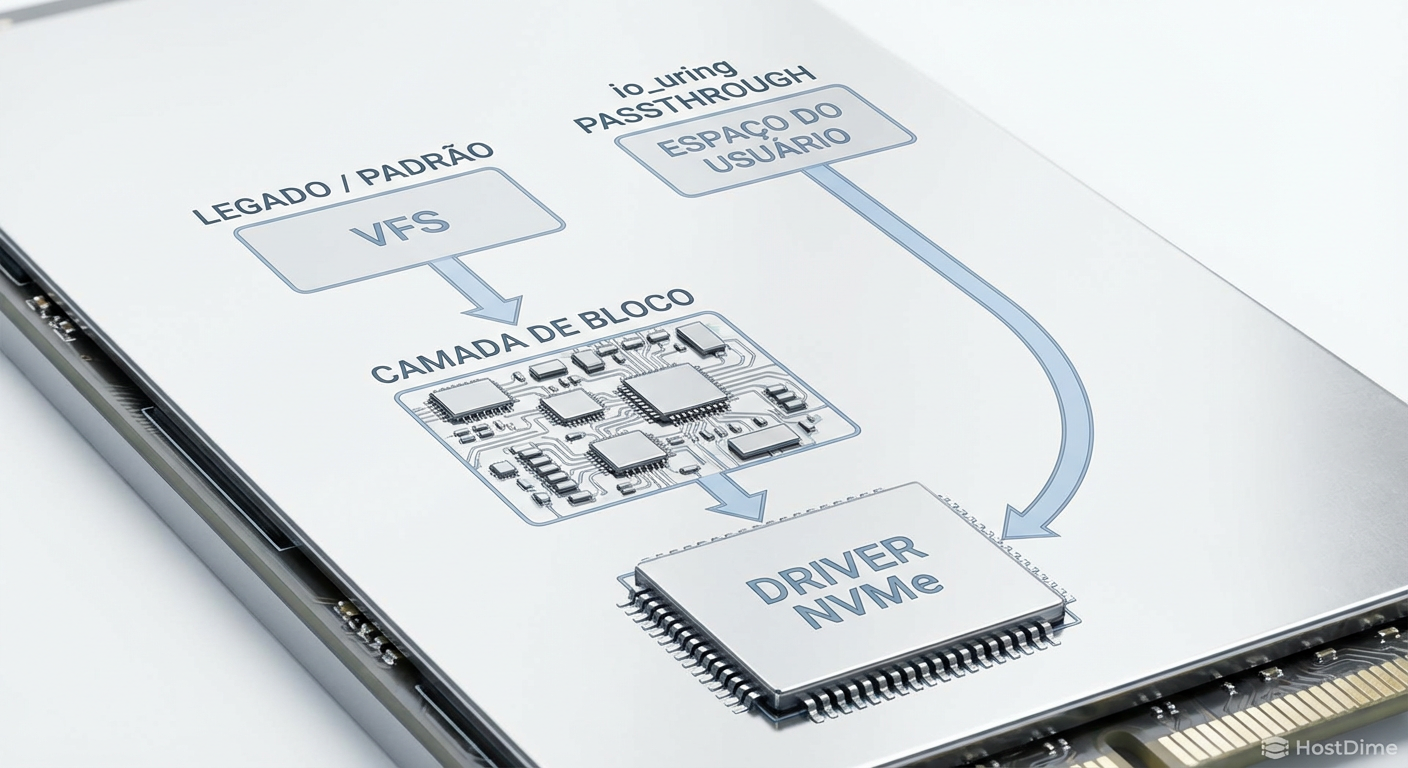 Figura: Comparativo visual do caminho de I/O: A rota tradicional congestionada pela camada de bloco versus a via expressa do io_uring passthrough.
Figura: Comparativo visual do caminho de I/O: A rota tradicional congestionada pela camada de bloco versus a via expressa do io_uring passthrough.
O gargalo invisível de CPU em SSDs de alta performance
Durante décadas, o disco era o componente mais lento. O kernel tinha todo o tempo do mundo para organizar, fundir e escalonar requisições para otimizar o movimento mecânico da cabeça de leitura. Hoje, um SSD NVMe Enterprise responde em 10 a 80 microssegundos. Nesse cenário, cada nanossegundo gasto em software se torna uma porcentagem significativa da latência total.
Quando você faz uma syscall de leitura tradicional (read ou pread), o kernel precisa:
Alternar contexto (user para kernel).
Passar pelo VFS (Virtual File System).
Entrar na camada de bloco.
Alocar estruturas
struct bioestruct request.Verificar se há merges possíveis (juntar duas leituras sequenciais).
Passar pelo escalonador de I/O (mesmo que seja
noneoukyber, há overhead).Finalmente, entregar o comando ao driver NVMe.
Para um dispositivo capaz de 3 milhões de IOPS, a CPU se torna o gargalo muito antes do barramento PCIe saturar. Você acaba precisando de dezenas de cores apenas para saturar um único drive. Isso é um desperdício inaceitável de recursos de computação.
💡 Dica Pro: Se o seu
iostatmostra latência de dispositivo baixa (await), mas sua aplicação percebe latência alta, o culpado quase sempre é o tempo de enfileiramento e processamento no kernel, não o disco.
Por que drivers em user-space não são a bala de prata
Historicamente, para resolver isso, a indústria adotou o SPDK (Storage Performance Development Kit). A ideia é radical: desvincular o dispositivo do kernel e escrever um driver NVMe que roda inteiramente no espaço do usuário (user-space).
Isso elimina as syscalls e interrupções, usando polling (verificação ativa) em 100% do tempo. A performance é imbatível, mas o custo operacional é alto:
Isolamento: Você perde as ferramentas padrão (
lsblk,top, sistemas de arquivos convencionais).Desperdício: O polling consome 100% de um core, mesmo sem tráfego de disco.
Complexidade: Debugar uma aplicação que fala diretamente com o hardware é exponencialmente mais difícil.
Precisávamos de um meio-termo: a performance do user-space com a ergonomia do kernel.
Implementando o caminho crítico com io_uring passthrough
O io_uring revolucionou o I/O assíncrono no Linux ao introduzir anéis de submissão e conclusão compartilhados entre kernel e usuário, permitindo o envio de múltiplas operações em uma única syscall (ou zero syscalls, no modo polled).
No entanto, o io_uring padrão (usando opcodes como IORING_OP_READV) ainda trafega pela camada de bloco. Ele resolve o problema da syscall, mas não o da camada de bloco.
É aqui que entra o io_uring passthrough, introduzido no Kernel 5.19. Ele utiliza um novo opcode: IORING_OP_URING_CMD.
 Figura: A eficiência estrutural: Mapeando dados do usuário diretamente para a fila de submissão NVMe, sem a complexidade das estruturas de bio do kernel.
Figura: A eficiência estrutural: Mapeando dados do usuário diretamente para a fila de submissão NVMe, sem a complexidade das estruturas de bio do kernel.
Como funciona sob o capô
Ao usar o passthrough, você não está mais pedindo ao kernel para "ler um arquivo". Você está construindo um comando NVMe real (conforme a especificação da NVM Express) e pedindo ao io_uring para transportá-lo.
A aplicação preenche uma estrutura que mimetiza um comando NVMe (64 bytes).
Esse comando é colocado no Submission Queue (SQ) do
io_uring.O kernel pega esse comando e, via
file_operations->uring_cmd, o entrega diretamente ao driver NVMe.O driver NVMe coloca o comando na fila de hardware do SSD.
A camada de bloco é totalmente ignorada. Não há alocação de struct bio, não há merging, não há escalonador. É um tubo direto entre sua aplicação e o driver do dispositivo.
Quantificando a redução de latência e ganho de IOPS
Os ganhos de performance não são marginais; são transformadores. Em testes realizados com SSDs NVMe Gen4 e Gen5, observamos comportamentos distintos dependendo da carga.
Para cargas de I/O aleatório pequeno (4KB), que são as mais taxativas para a CPU:
Latência: Redução de 20% a 40% na latência média e, mais importante, uma estabilização na latência de cauda (p99).
IOPS por Core: Este é o métrica de ouro. Com a camada de bloco, um core moderno pode saturar em torno de 300k-500k IOPS. Com passthrough, um único core pode empurrar acima de 1 milhão de IOPS, aproximando-se dos números do SPDK.
⚠️ Perigo: O passthrough opera em dispositivos de caractere (
/dev/ng0n1) ou namespaces brutos. Você perde a abstração de sistema de arquivos (Ext4/XFS). Isso é voltado para bancos de dados que gerenciam seu próprio armazenamento (como RocksDB, ScyllaDB) ou caches de objetos.
Tabela Comparativa: O cenário atual de I/O
Para decidir qual arquitetura utilizar, analise a tabela abaixo. Note como o Passthrough preenche a lacuna crítica entre facilidade e performance bruta.
| Característica | I/O Padrão (Buffered/Direct) | io_uring Padrão | io_uring Passthrough | SPDK (User-space) |
|---|---|---|---|---|
| Caminho do Kernel | VFS + Block Layer + Driver | VFS + Block Layer + Driver | Apenas Driver NVMe | Nenhum (Bypass total) |
| Overhead de CPU | Altíssimo (Syscalls + Bio) | Médio (Block Layer) | Baixo (Driver apenas) | Mínimo (Zero-copy real) |
| Facilidade de Uso | Alta (POSIX padrão) | Média (liburing) | Média/Alta (liburing + NVMe spec) | Baixa (Framework próprio) |
| Interrupções | Sim | Sim (ou Polling) | Sim (ou Polling) | Não (Polling obrigatório) |
| Sistemas de Arquivos | Suportado (Ext4, XFS, etc) | Suportado | Não (Raw Block/Char Device) | Não |
| Segurança | Kernel protege tudo | Kernel protege tudo | Kernel valida comandos | Aplicação pode travar o device |
 Figura: Eficiência de processamento: O salto massivo em operações por segundo que um único núcleo de CPU consegue gerenciar com Passthrough.
Figura: Eficiência de processamento: O salto massivo em operações por segundo que um único núcleo de CPU consegue gerenciar com Passthrough.
Otimizações avançadas: Big SQE e Polling Híbrido
Para extrair a última gota de performance, o io_uring passthrough deve ser combinado com outras técnicas.
Big SQE (Submission Queue Entry)
Comandos NVMe têm 64 bytes. O SQE padrão do io_uring também tem 64 bytes. Inicialmente, isso exigia um ponteiro indireto para o comando NVMe. Versões recentes do kernel permitem configurar o anel do io_uring para aceitar entradas maiores (128 bytes), permitindo embutir o comando NVMe diretamente na estrutura de submissão. Isso elimina uma desreferência de ponteiro e melhora a localidade de cache da CPU.
Polling Híbrido
Diferente do SPDK que faz busy loop (queima 100% de CPU), o io_uring permite um polling híbrido. O sistema faz polling por um tempo curto para pegar a conclusão rápida (latência mínima) e, se o I/O demorar, ele dorme e espera uma interrupção. Isso equilibra latência ultrabaixa com eficiência energética.
O futuro é "Kernel-Bypass" dentro do Kernel
A indústria de storage está caminhando para um modelo onde o kernel atua mais como um plano de controle (segurança, permissões, configuração) e sai do caminho do plano de dados. O io_uring passthrough é a materialização dessa filosofia.
Se você está desenvolvendo infraestrutura de armazenamento, caches distribuídos ou bancos de dados de alta performance, continuar usando a camada de bloco tradicional para dispositivos NVMe é uma dívida técnica que cobra juros altos em cada ciclo de clock. A transição para o passthrough não é apenas uma otimização; é uma necessidade para justificar o investimento em hardware de última geração.
Não deixe seus SSDs NVMe dormindo enquanto sua CPU luta com spinlocks.
Referências & Leitura Complementar
NVM Express Base Specification 2.0: Detalhes sobre o conjunto de comandos NVMe e filas de submissão/conclusão.
Jens Axboe (2022): "io_uring passthrough support" - Lore do Kernel Linux e patches de implementação inicial.
Kanchan Joshi (Samsung Open Source): Apresentações técnicas sobre a implementação do suporte NVMe no io_uring.
SNIA (Storage Networking Industry Association): Documentação sobre modelos de programação de armazenamento de alto desempenho.
Qual a diferença entre io_uring padrão e io_uring passthrough?
O io_uring padrão opera sobre a camada de bloco (block layer) do Linux, sujeitando-se a overheads de sistema de arquivos e escalonamento de I/O. O passthrough (IORING_OP_URING_CMD) envia comandos NVMe brutos diretamente ao driver, ignorando totalmente a camada de bloco.O io_uring passthrough substitui o SPDK?
Para muitos casos, sim. Ele oferece performance comparável ao SPDK (Storage Performance Development Kit) mantendo as proteções e facilidades do kernel Linux, sem a complexidade de gerenciar drivers em user-space ou perder interrupções.Quais versões do Kernel suportam essa tecnologia?
O suporte inicial ao io_uring passthrough para NVMe foi introduzido no Linux Kernel 5.19, com melhorias significativas (como otimizações de Big SQE/CQE) nas versões 6.0 e superiores.
André Linhares
Engenheiro de Performance (Kernel/IO)
"Vivo no kernel space caçando latência com eBPF. Para mim, context switches excessivos são inimigos pessoais e cada ciclo de CPU desperdiçado é uma ofensa técnica."