Eliminando o FTL: Latência Determinística com NVMe ZNS e io_uring Passthrough

Descubra como combinar Zoned Namespaces (ZNS) e io_uring passthrough para eliminar a latência de cauda e maximizar IOPS no Linux 6.x.
Se você acredita que seu SSD NVMe é rápido apenas porque ele entrega 1 milhão de IOPS em um benchmark sintético de leitura aleatória, você está olhando para a métrica da vaidade. A realidade operacional, aquela que acorda engenheiros às 3 da manhã, vive na latência de cauda (tail latency).
O problema fundamental do armazenamento moderno não é a falta de largura de banda no barramento PCIe Gen5. O problema é a imprevisibilidade introduzida pelas camadas de abstração que empilhamos entre a aplicação e a célula NAND. Nós mentimos para o sistema operacional, dizendo que o SSD é um dispositivo de bloco linear, quando na verdade ele é uma máquina complexa de gerenciamento de log, lutando desesperadamente para esconder a física da memória flash.
Resumo em 30 segundos
- O problema: A camada de tradução (FTL) nos SSDs convencionais causa picos de latência imprevisíveis devido ao Garbage Collection interno, destruindo a performance em p99.
- A solução: NVMe Zoned Namespaces (ZNS) remove a FTL do caminho, entregando o controle físico dos blocos ao host para uma latência determinística.
- A implementação: Utilizar
io_uringcom passthrough (viaio_uring_cmd) permite enviar comandos NVMe brutos direto do userspace, ignorando toda a sobrecarga da camada de bloco do kernel Linux.
O custo oculto da latência de cauda em SSDs convencionais
Em um cenário de datacenter ou storage server de alta performance, a média de latência é irrelevante. Se você tem um cluster de banco de dados distribuído (como ScyllaDB ou RocksDB), a requisição mais lenta dita a performance global.
Nos SSDs convencionais, a Flash Translation Layer (FTL) é a responsável por mapear endereços lógicos (LBAs) para endereços físicos (PPAs). A memória NAND não permite sobrescrita direta; você deve apagar um bloco inteiro antes de escrever novamente. A FTL gerencia isso mantendo um mapa de indireção gigantesco na DRAM do dispositivo.
Quando o disco está novo, tudo é rápido. Mas conforme o disco enche e o estado de fragmentação aumenta, a FTL precisa realizar o Garbage Collection (GC) em segundo plano: copiar páginas válidas de blocos antigos para novos e apagar os blocos sujos.
⚠️ Perigo: Durante um ciclo agressivo de GC interno, uma operação de escrita que deveria levar 20 microssegundos pode travar por 500 milissegundos ou mais. Para o kernel, isso é um "stall" de I/O inexplicável.
Esse comportamento destrói o determinismo. Você não tem como prever quando o firmware do SSD decidirá que é hora de limpar a casa. Em cargas de trabalho sensíveis à latência, esses soluços resultam em timeouts de aplicação e retransmissões de rede, criando uma cascata de falhas.
 Fig. 1: A remoção da camada de tradução (FTL) transfere a responsabilidade do posicionamento de dados para o host.
Fig. 1: A remoção da camada de tradução (FTL) transfere a responsabilidade do posicionamento de dados para o host.
A colisão entre o garbage collection do firmware e o sistema de arquivos
O cenário piora quando analisamos a interação entre o sistema de arquivos (FS) e a FTL. Sistemas de arquivos modernos como ZFS ou Btrfs utilizam Copy-on-Write (CoW). Eles tentam sequencializar as escritas para otimizar o disco.
No entanto, a FTL não sabe disso. Ela vê um fluxo de LBAs e tenta, por conta própria, otimizar o posicionamento na NAND para wear leveling (nivelamento de desgaste). Temos aqui o problema clássico do "Log-on-Log". O FS está fazendo GC (limpando segmentos) e o SSD está fazendo GC (limpando blocos).
O resultado é uma Amplificação de Escrita (Write Amplification - WA) brutal. Se sua aplicação escreve 4KB, o sistema de arquivos pode transformar isso em 16KB de metadados + dados, e a FTL do SSD, devido à fragmentação interna e GC, pode acabar escrevendo 64KB ou mais na NAND física. Isso não apenas queima a vida útil do SSD (TBW), mas satura a banda interna do controlador.
Por que apenas trocar libaio por io_uring não elimina a amplificação
Muitos engenheiros acreditam que migrar de libaio para io_uring resolve todos os problemas de I/O. Embora o io_uring seja uma obra-prima de design de interface de syscalls (agradecimentos a Jens Axboe), ele resolve o problema da submissão e completude, não o problema da física do dispositivo.
O io_uring tradicional, operando em modo de bloco bufferizado ou O_DIRECT, ainda passa pela camada de bloco do Linux (Block Layer). O caminho é:
Aplicação submete SQE (Submission Queue Entry).
Sistema de Arquivos (VFS).
Camada de Bloco (Bio split, merge, scheduler).
Driver NVMe.
Hardware.
Mesmo com io_uring em modo polled (gastando 100% de uma CPU para verificar a fila de completude e evitar interrupções), você ainda está sujeito à FTL do SSD. Você submete o comando mais rápido, mas o comando ainda espera o SSD terminar sua "limpeza interna". O software é rápido, mas o hardware é imprevisível.
Implementando NVMe Zoned Namespaces via io_uring passthrough
A verdadeira revolução acontece quando combinamos duas tecnologias: ZNS e io_uring Passthrough.
Zoned Namespaces (ZNS) remove a FTL convencional. O SSD expõe sua geometria física na forma de "Zonas".
As zonas devem ser escritas sequencialmente.
Para sobrescrever, a zona inteira deve ser resetada.
Não há GC oculto no drive. O host é responsável por gerenciar onde os dados são colocados.
Isso elimina a necessidade de overprovisioning massivo (geralmente 7% a 28% da capacidade do disco) e reduz a DRAM necessária no controlador do SSD, tornando-os mais baratos e densos.
io_uring Passthrough (introduzido no kernel 5.19+) permite que o io_uring envie comandos NVMe raw (brutos) diretamente para o driver, ignorando completamente a camada de bloco, o scheduler de I/O e o VFS.
 Fig. 2: O caminho crítico do io_uring passthrough (io_uring_cmd) ignorando a camada de bloco do Linux.
Fig. 2: O caminho crítico do io_uring passthrough (io_uring_cmd) ignorando a camada de bloco do Linux.
O Caminho do Passthrough
Ao usar a flag IORING_OP_URING_CMD, nós construímos um comando NVMe de 64 bytes no userspace e o colocamos no Submission Queue do io_uring. O kernel pega esse pacote e o entrega diretamente à fila de hardware do dispositivo NVMe.
Isso reduz a sobrecarga de CPU por I/O drasticamente. Não há alocação de estruturas bio ou request no kernel. É o caminho mais curto possível entre a memória da sua aplicação e o controlador NVMe.
💡 Dica Pro: Para utilizar passthrough com eficiência, você deve fixar a thread de submissão na mesma CPU NUMA onde o dispositivo PCIe está conectado. Cruzar o barramento QPI/UPI para falar com um NVMe é um desperdício de ciclos imperdoável.
Mecânica de Escrita: Zone Append vs. Write
Em um ambiente ZNS, a escrita sequencial estrita cria um desafio de concorrência. Se múltiplos produtores tentarem escrever na mesma zona usando o comando Write padrão, eles precisam de um lock para garantir que o Write Pointer (WP) seja atualizado atomicamente. Locks matam a performance.
A especificação NVMe introduziu o comando Zone Append.
Diferente do Write onde você especifica o LBA exato, no Zone Append você especifica apenas o Zone Start LBA (ZSL). O drive coloca os dados na próxima posição disponível e retorna o LBA onde os dados foram efetivamente escritos na resposta de completude (CQE).
Isso permite que múltiplas threads bombardeiem a mesma zona com escritas sem locks no host. O controlador do SSD serializa a chegada e informa onde cada pedaço de dado pousou.
 Fig. 4: Mecanismo de Zone Append permitindo escritas paralelas sem lock no Write Pointer.
Fig. 4: Mecanismo de Zone Append permitindo escritas paralelas sem lock no Write Pointer.
Análise de latência determinística e throughput com fio e io_uring_cmd
Para validar essa arquitetura, não podemos usar ferramentas de disco padrão. Precisamos de um gerador de carga capaz de falar "NVMe Passthrough". O fio (Flexible I/O Tester) possui a engine io_uring_cmd especificamente para isso.
Um teste comparativo típico envolve saturar um SSD convencional e um ZNS com escritas aleatórias (no caso do ZNS, aleatórias entre zonas, mas sequenciais dentro delas) e medir a latência p99.
Configuração do Teste (Exemplo):
Engine:
io_uring_cmdTarget:
/dev/ng0n1(Character device do NVMe, necessário para passthrough)Depth: 128
Batch: 32
O resultado visual é chocante. Enquanto o SSD convencional apresenta "spikes" de latência que chegam a dezenas de milissegundos a cada poucos segundos (ciclos de GC), o SSD ZNS mantém uma linha quase plana.
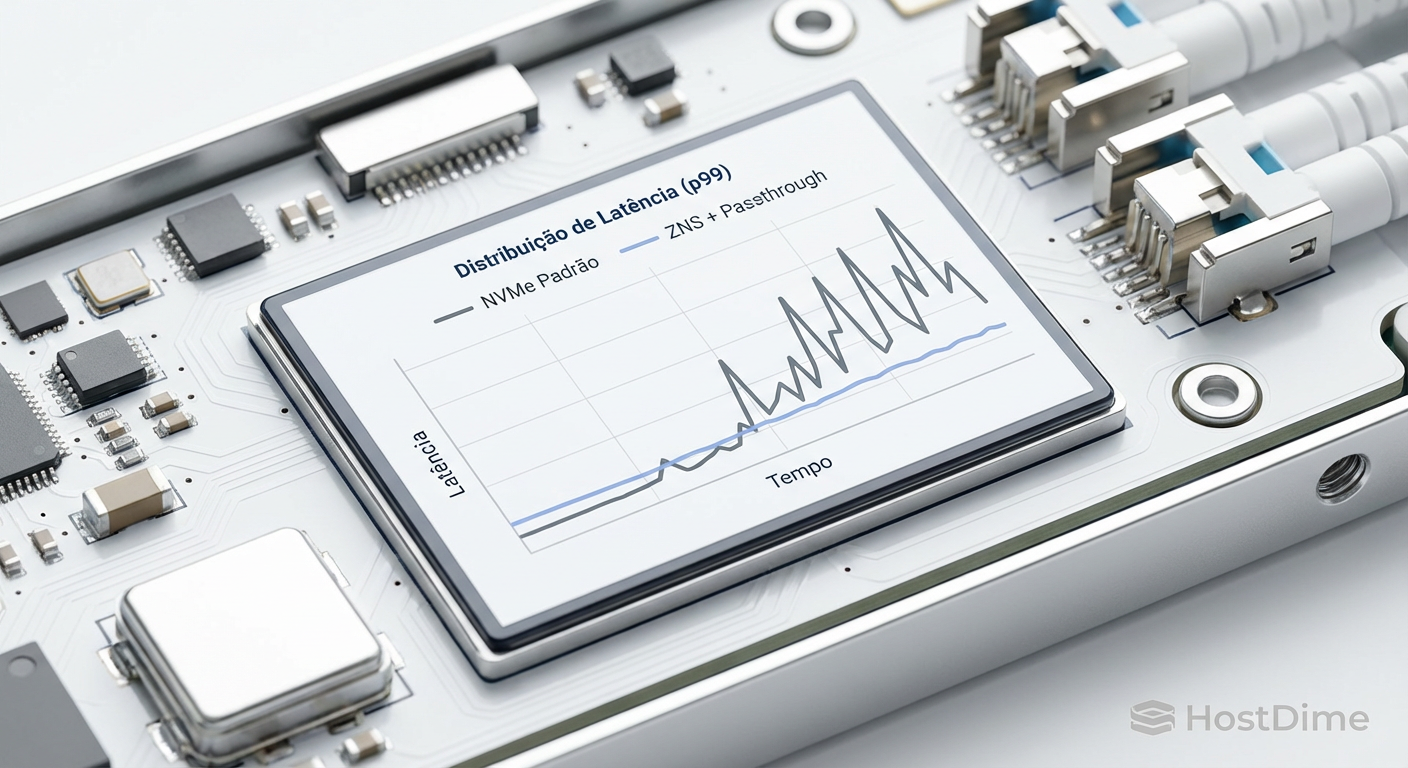 Fig. 3: Comparativo de latência de cauda (p99) sob carga de escrita aleatória sustentada.
Fig. 3: Comparativo de latência de cauda (p99) sob carga de escrita aleatória sustentada.
A latência média pode ser similar, mas a latência de cauda no ZNS é ordens de magnitude menor. Em sistemas de Real-Time Bidding ou High-Frequency Trading, essa diferença é dinheiro.
O Desafio da Adoção
Não se engane, a barreira de entrada é alta. Você não pode simplesmente formatar um SSD ZNS com mkfs.ext4. O sistema de arquivos precisa ser Zone Aware (como F2FS ou versões recentes do Btrfs em modo zoned).
Para máxima performance, aplicações como bancos de dados (RocksDB com ZenFS) estão implementando suporte nativo a ZNS, gerenciando as zonas diretamente e ignorando o sistema de arquivos completamente. É o retorno ao controle total, similar ao que fazíamos com raw devices no passado, mas agora com uma interface padronizada e inteligente.
Previsão Técnica
A era do SSD como uma "caixa preta" está chegando ao fim para o segmento Enterprise. A ineficiência da FTL convencional é insustentável com o aumento da densidade das células (QLC, PLC).
A combinação de ZNS + io_uring Passthrough será o padrão de facto para infraestrutura de armazenamento de alta performance até 2027. Se você escreve código de armazenamento ou gerencia infraestrutura crítica, precisa entender como gerenciar zonas e filas de submissão assíncronas hoje. O desperdício de ciclos de CPU e a latência estocástica não são mais aceitáveis.
Perguntas Frequentes
1. Posso usar ZNS em Windows? O suporte a Zoned Storage no Windows é limitado e focado em SMR HDDs. Para NVMe ZNS com performance real via passthrough, o Linux é o único ecossistema viável atualmente, especialmente com kernels 6.x.
2. O que acontece se eu encher uma zona? Você deve explicitamente enviar um comando de "Finish" ou, se quiser reescrever, um comando de "Reset" na zona. O gerenciamento de qual zona está cheia e qual está vazia é responsabilidade da sua aplicação ou do sistema de arquivos zone-aware.
3. io_uring Passthrough funciona com SSDs normais? Sim, funciona. Você pode enviar comandos de leitura/escrita brutos para um SSD convencional. Você ganha a redução de overhead do kernel (sem bio layer), mas ainda sofre com a imprevisibilidade da FTL interna do drive.
4. Qual a diferença entre ZNS e Open Channel SSDs? Open Channel foi o precursor, mas não era padronizado (cada vendor tinha sua implementação). ZNS é parte oficial da especificação NVMe (TP 4053), garantindo compatibilidade entre fabricantes.
Referências & Leitura Complementar
NVM Express Base Specification 2.0c – Seção sobre Zoned Namespaces Command Set.
NVMe Technical Proposal 4053 (ZNS) – Definição original da arquitetura de zonas.
Joshi, K. et al. (2023). "xNVMe: High-performance SSD integration library".
Axboe, J. "Efficient IO with io_uring" – Kernel documentation & LWN articles.
Bjørling, M. "Zoned Namespaces (ZNS) SSDs" – Western Digital / Linux Foundation presentations.

André Linhares
Engenheiro de Performance (Kernel/IO)
"Vivo no kernel space caçando latência com eBPF. Para mim, context switches excessivos são inimigos pessoais e cada ciclo de CPU desperdiçado é uma ofensa técnica."