Latência de storage invisível: diagnóstico avançado com eBPF

Vá além do iostat. Aprenda a usar eBPF (bcc/bpftrace) para rastrear I/O no kernel Linux, identificar latência de cauda e definir SLOs de armazenamento precisos.
Você já esteve naquela sala de guerra às 3 da manhã. O banco de dados está engasgando, a aplicação está lenta e o cliente está furioso. Você abre o painel de monitoramento e o gráfico de latência média de disco mostra confortáveis 2ms. O uso de CPU está baixo. A rede está limpa. No entanto, o sistema se comporta como se estivesse atolado em areia movediça.
O problema não é o que você está vendo; é o que suas ferramentas tradicionais estão escondendo. Em sistemas de armazenamento modernos, especialmente com a velocidade dos dispositivos NVMe, a média é uma mentira estatística que mascara a verdadeira experiência do usuário.
Resumo em 30 segundos
- Médias mentem: Ferramentas baseadas em amostragem (como
iostat) suavizam picos de latência crítica, escondendo o "long tail" (p99) que afeta a percepção do usuário.- Visibilidade granular: O eBPF permite rastrear cada operação de I/O individualmente, distinguindo tempo de fila (software) de tempo de serviço (hardware) sem travar o sistema.
- Diagnóstico seguro: Diferente do
strace, que causa overhead massivo, o eBPF compila e executa código seguro diretamente no kernel, sendo ideal para ambientes de produção sensíveis.
Quando o p99 grita mas a média sussurra
A métrica de "latência média" é um artefato de uma era onde os discos giravam fisicamente e as latências eram medidas em dezenas de milissegundos. Hoje, em um ecossistema de Flash Storage e NVMe, onde as operações ocorrem em microssegundos, a média é insuficiente.
Imagine que seu storage processa 10.000 IOPS. Se 9.900 operações levam 100 microssegundos, mas 100 operações (apenas 1%) levam 500 milissegundos devido a uma compactação de fundo ou garbage collection do SSD, a média aritmética ainda parecerá saudável. No entanto, para os 100 usuários (ou threads de banco de dados) que caíram nesses 500ms, o sistema travou.
Isso é a latência de cauda (tail latency). Em arquiteturas de microsserviços ou bancos de dados distribuídos, uma única leitura de disco lenta pode causar um efeito cascata, bloqueando worker threads e esgotando pools de conexão. O iostat padrão, que exibe médias agregadas por segundo, achata esses picos. Ele diz que o clima está "parcialmente nublado" enquanto um tornado está destruindo uma casa específica no bairro.
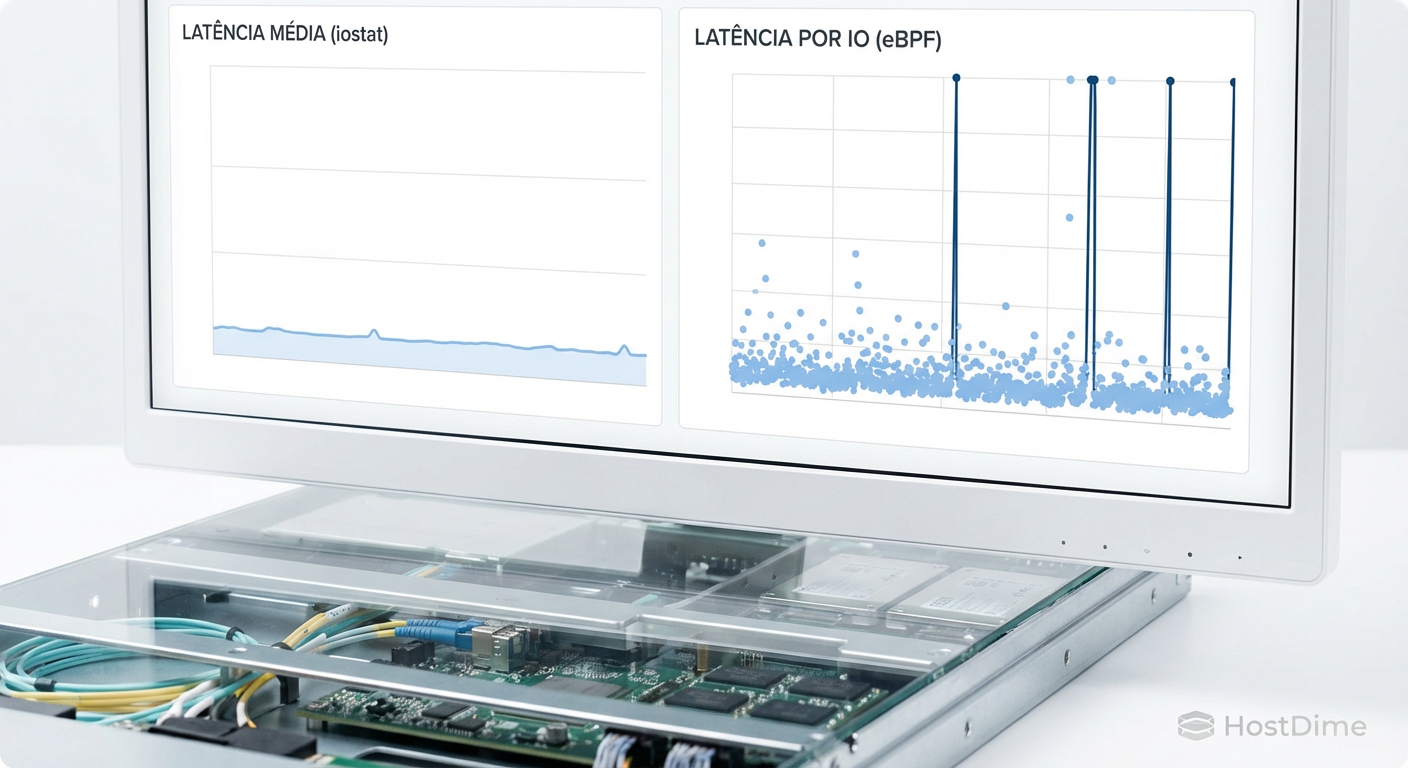 Figura: Comparação visual: A ilusão da estabilidade na média versus a realidade caótica revelada pela análise granular de cada I/O.
Figura: Comparação visual: A ilusão da estabilidade na média versus a realidade caótica revelada pela análise granular de cada I/O.
A jornada do bloco: do VFS ao controlador NVMe
Para diagnosticar onde a latência ocorre, precisamos dissecar o caminho do I/O. Quando uma aplicação solicita um dado, a requisição não vai magicamente para o disco. Ela atravessa um labirinto no kernel Linux:
VFS (Virtual File System): A camada lógica (ex:
read()).File System (Ext4, XFS, ZFS): Tradução de arquivos para blocos lógicos.
Block Layer: Aqui reside o perigo. O I/O entra em filas de escalonamento (schedulers como
mq-deadlineoukyber).Driver (NVMe/SCSI): A entrega para o protocolo de hardware.
Dispositivo Físico: O tempo que o controlador do SSD leva para buscar o dado na NAND Flash e retornar.
💡 Dica Pro: Uma latência alta reportada pelo sistema operacional nem sempre é culpa do disco. Frequentemente, o I/O fica preso na camada de bloco (software) esperando para ser despachado. Isso é "latência de fila", não "latência de disco". Ferramentas tradicionais misturam os dois.
O microscópio do kernel: eBPF
O eBPF (Extended Berkeley Packet Filter) mudou o jogo da observabilidade. Originalmente desenhado para filtragem de pacotes de rede, ele evoluiu para uma máquina virtual segura dentro do kernel Linux.
Pense no eBPF como a capacidade de anexar "sondas" ou "ganchos" em qualquer função do kernel (kprobes) ou tracepoints estáticos. Quando o evento ocorre (ex: um disco começa ou termina uma gravação), o código eBPF é executado.
A grande vantagem sobre ferramentas antigas como strace é a arquitetura. O strace para a execução do processo a cada syscall para ler o estado, causando um overhead brutal que pode derrubar uma produção. O eBPF executa bytecode compilado (JIT) dentro do próprio kernel e envia para o espaço do usuário apenas o resumo dos dados (um histograma ou mapa), com impacto de performance quase imperceptível.
Rastreamento granular com biosnoop e biolatency
Para o engenheiro de confiabilidade focado em storage, o pacote bcc-tools (BPF Compiler Collection) é o canivete suíço essencial. Vamos focar em duas ferramentas que resolvem o mistério da latência invisível.
1. biolatency: A verdade estatística
Em vez de uma média, o biolatency captura o tempo de cada I/O de bloco e constrói um histograma em potência de 2.
$ sudo biolatency -D 10
Tracing block device I/O... Hit Ctrl-C to end.
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 152 |******** |
8 -> 15 : 4210 |****************************************|
16 -> 31 : 1204 |*********** |
...
4096 -> 8191 : 2 | |
8192 -> 16383 : 0 | |
16384 -> 32767 : 5 | |
Observe o final da cauda. Temos 5 operações que levaram entre 16ms e 32ms. Em um iostat com milhares de operações rápidas, esses 5 eventos desapareceriam. Aqui, eles são evidentes. Se esses 5 I/Os forem gravações no journal do seu banco de dados, você encontrou a causa da lentidão da transação.
2. biosnoop: O detetive detalhista
Enquanto o biolatency dá o panorama, o biosnoop imprime cada operação de I/O individualmente conforme ela é completada, com detalhes cruciais.
$ sudo biosnoop
TIME(s) COMM PID DISK T SECTOR BYTES LAT(ms)
0.000000 kworker/u16:1 189 nvme0n1 W 2341234 4096 0.12
0.004123 mysqld 2140 nvme0n1 R 9928112 16384 0.15
0.015122 mysqld 2140 nvme0n1 R 1231231 8192 25.40
Na terceira linha, vemos o culpado: o processo mysqld sofreu uma latência de 25.40ms em uma leitura. Com essa informação, podemos correlacionar o timestamp exato com os logs da aplicação.
 Figura: Anatomia da observabilidade: Onde o eBPF se conecta na pilha de I/O do Linux para diferenciar tempo de fila de tempo de hardware.
Figura: Anatomia da observabilidade: Onde o eBPF se conecta na pilha de I/O do Linux para diferenciar tempo de fila de tempo de hardware.
Comparativo: Ferramentas de Diagnóstico de Storage
Para decidir qual ferramenta usar em um incidente, avalie o equilíbrio entre visibilidade e impacto.
| Característica | iostat | strace | eBPF (biolatency/biosnoop) |
|---|---|---|---|
| Fonte de Dados | Contadores do Kernel (/proc) | Interceptação de Syscall | Tracepoints/Kprobes no Kernel |
| Granularidade | Agregada (Média por intervalo) | Por Syscall (Processo) | Por Evento de I/O (Sistema todo) |
| Overhead | Muito Baixo (Negligenciável) | Muito Alto (Pausa execução) | Baixo (Execução JIT in-kernel) |
| Visibilidade | Dispositivo / Partição | Aplicação Específica | Full Stack (App até Driver) |
| Uso Ideal | Monitoramento contínuo / Dashboards | Debug de falhas lógicas (crash) | Análise de latência e performance |
Transformando histogramas em SLOs de armazenamento
Como SRE, seu objetivo não é apenas encontrar o problema, mas evitar que ele viole o acordo com o cliente. A "latência média" é um SLI (Service Level Indicator) pobre. O eBPF nos permite criar SLIs baseados na realidade do usuário.
Em vez de definir um SLO (Service Level Objective) como: "A latência média de disco deve ser inferior a 5ms."
Utilize os dados de histograma para definir: "99% das operações de leitura (p99) devem ser completadas em menos de 10ms, medido em janelas de 5 minutos."
Isso alinha a infraestrutura com a expectativa de negócio. Se o seu storage array começa a fazer throttling ou se o garbage collection do SSD impacta 2% das requisições, a média pode não disparar o alerta, mas o SLO baseado em percentil (alimentado por dados do eBPF) queimará seu Error Budget, alertando a equipe antes que o cliente abra um chamado.
⚠️ Perigo: Cuidado ao usar
biosnoopem sistemas com carga extrema de I/O (centenas de milhares de IOPS). Imprimir cada linha no terminal consome CPU do userspace. Nesses casos, prefirabiolatencyou ferramentas que exportam métricas diretamente para o Prometheus (comoebpf_exporter), mantendo a agregação no kernel.
O observador observado
A era do diagnóstico baseado em "olhômetro" e médias acabou. Com a complexidade dos SSDs modernos (que são computadores completos internamente) e camadas de virtualização, a latência se esconde nas dobras da infraestrutura.
A adoção de eBPF para análise de storage não é apenas uma melhoria técnica; é uma mudança cultural. Ela move a conversa de "o disco está lento?" para "qual componente da pilha de I/O está introduzindo latência?". Para o SRE moderno, dominar essas ferramentas é a diferença entre culpar o hardware cegamente e resolver o problema cirurgicamente.
Referências & Leitura Complementar
Gregg, Brendan. BPF Performance Tools. Addison-Wesley Professional, 2019. (A "bíblia" do eBPF).
Kernel.org. Linux Block IO Controller Documentation. Disponível na documentação oficial do Kernel Linux.
IO Visor Project. BCC - Tools for BPF-based Linux IO analysis. Repositório oficial no GitHub.
NVMe Express. NVM Express Base Specification. (Para entender os comandos de hardware subjacentes).
Perguntas Frequentes (FAQ)
O uso de eBPF causa impacto na performance do servidor de produção?
Geralmente, o impacto é insignificante. Diferente de ferramentas antigas como `strace` que pausam a execução, o eBPF executa bytecode seguro e compilado (JIT) diretamente no kernel, agregando dados in-kernel e enviando apenas resumos para o user-space.Qual a diferença entre latência de fila e latência de dispositivo?
Latência de fila é o tempo que o I/O espera no scheduler do kernel (software). Latência de dispositivo é o tempo físico que o disco leva para processar o comando. Ferramentas como `iostat` frequentemente misturam ambos, enquanto o eBPF permite medi-los separadamente.Preciso saber programar em C para usar eBPF?
Não para diagnósticos padrão. O pacote `bcc-tools` (BPF Compiler Collection) já traz scripts prontos em Python/Lua (como `biolatency`, `biosnoop`, `ext4slower`) que cobrem a maioria dos cenários de SRE.
Rafael Junqueira
Engenheiro de Confiabilidade (SRE)
"Transformo caos em estabilidade via observabilidade. Defensor da cultura blameless e focado em SLIs e SLOs. Se algo falhou, revisamos o sistema, nunca a pessoa."