NFS vs SMB: Engenharia de performance, tuning de kernel e a verdade sobre latência

Esqueça a guerra de fans. Uma análise profunda de engenharia sobre filas, interrupções, ksmbd, nconnect e como saturar 10GbE+ sem desperdício de CPU.
NFS vs SMB: Engenharia de performance, tuning de kernel e a verdade sobre latência
A maioria dos administradores de sistemas olha para o throughput. Eles veem um link de 10GbE saturado e sorriem, ou veem um link ocioso e choram. Se você opera nesse nível, está olhando para a métrica errada. A largura de banda é apenas o tamanho do cano; a latência é a velocidade com que a água viaja. No mundo do armazenamento, especialmente ao lidar com NVMe e SSDs modernos, o gargalo raramente é o fio. O gargalo é a pilha de software, as interrupções de hardware e a ineficiência brutal de mover dados entre o espaço do usuário (userspace) e o espaço do kernel.
Resumo em 30 segundos
- Largura de banda é vaidade, latência é sanidade: Em redes modernas, o custo de processamento de pacotes (CPU overhead) e context switches matam a performance muito antes de saturar o link de 10GbE ou 25GbE.
- O mito do Jumbo Frames: Com NICs modernas fazendo Generic Receive Offload (GRO/LRO), alterar o MTU para 9000 frequentemente causa mais problemas de configuração do que ganhos reais de CPU.
- Kernel vs Userspace: A grande batalha atual é mover o servidor SMB para dentro do kernel (ksmbd) para eliminar a cópia de buffers, enquanto o NFS foca em paralelismo de conexões (nconnect).
O mito da largura de banda infinita em redes de 10GbE
Você comprou placas Mellanox ConnectX, um switch MikroTik ou Ubiquiti com portas SFP+ e instalou um array de SSDs em ZFS. No entanto, suas transferências de arquivos pequenos (4k ou 64k) rastejam a velocidades de disco rígido de 1990. O problema reside na física do processamento de pacotes.
Para cada pacote que chega à sua interface de rede, a CPU precisa ser interrompida. O kernel precisa pegar esse pacote, analisar os cabeçalhos TCP/IP, verificar checksums (se o offload falhar ou não existir), determinar a qual socket ele pertence e copiar os dados para o buffer da aplicação.
 Figura: O caminho tortuoso de um pacote: da interrupção na NIC até o buffer da aplicação
Figura: O caminho tortuoso de um pacote: da interrupção na NIC até o buffer da aplicação
Se você está transferindo um arquivo grande sequencial, o TCP Window Scaling e o tamanho dos pacotes ajudam a amortizar esse custo. Mas em IOPS aleatórios, você está pagando o "imposto de syscall" milhares de vezes por segundo. Uma rede de 10GbE pode transportar milhões de pacotes por segundo, mas seu processador provavelmente não consegue lidar com as interrupções geradas por eles em um único núcleo.
A anatomia da latência: Context switches e a serialização do TCP
A latência de armazenamento em rede é composta por três vetores principais:
Latência de Mídia: O tempo que o NVMe leva para ler o bloco (microssegundos).
Latência de Rede: O tempo de voo no fio e nos switches (geralmente irrelevante em LANs, <100us).
Latência de Host (Kernel/Protocolo): O verdadeiro assassino.
Quando o Samba (smbd) roda em userspace, cada requisição de leitura ou escrita exige uma transição de contexto. O kernel recebe o pacote, acorda o processo smbd, o smbd processa o cabeçalho SMB, faz uma syscall para ler o disco, o kernel lê o disco, devolve ao smbd, que então faz outra syscall para enviar a resposta pela rede.
💡 Dica Pro: Monitore o Context Switch voluntário e involuntário com
pidstat -w 1. Se você vir números na casa dos milhares por segundo atrelados aos processos de storage, sua CPU está gastando mais tempo trocando de tarefa do que movendo dados.
Além disso, o TCP é inerentemente serializado por fluxo. Um único fluxo TCP (uma conexão de socket) é geralmente processado por um único núcleo de CPU devido ao RSS (Receive Side Scaling) tentar manter a afinidade de cache. Se você tem um Threadripper de 64 núcleos, mas sua transferência SMB ou NFS usa apenas uma conexão TCP, você está limitado à velocidade de um único núcleo.
Por que Jumbo Frames e caches gigantes são frequentemente placebos
Existe uma obsessão quase religiosa em habilitar Jumbo Frames (MTU 9000) em home labs e pequenos datacenters. A teoria é sólida: menos pacotes para a mesma quantidade de dados significa menos interrupções de CPU.
Na prática, em 2025, isso é frequentemente irrelevante. Placas de rede modernas e drivers de kernel Linux utilizam Generic Receive Offload (GRO) e Large Receive Offload (LRO). A NIC agrupa múltiplos pacotes MTU 1500 em um único "super-pacote" de até 64KB antes de passá-lo ao kernel. O processador já vê um bloco grande de dados.
Habilitar Jumbo Frames manualmente introduz fragilidade. Se um único dispositivo no caminho (um switch não gerenciado, uma VM bridge, um cliente Wi-Fi) não suportar MTU 9000, a fragmentação de pacotes ou o "black hole" de PMTUD (Path MTU Discovery) destruirá sua latência e throughput.
O mesmo vale para caches como L2ARC no ZFS. Adicionar 1TB de NVMe como cache de leitura não resolve latência de escrita síncrona (sync writes). Para NFS e iSCSI, o que importa é o SLOG (ZIL separado), e ele precisa ser de baixíssima latência (Optane ou NVMe de classe enterprise), não apenas "rápido".
NFS: Quebrando o limite de fluxo único com nconnect
O NFS (Network File System) é o padrão de facto para Linux, mas historicamente sofreu com o problema de fluxo único mencionado acima. Até kernels recentes, montar um share NFS significava abrir uma única conexão TCP.
A introdução da opção de montagem nconnect mudou o jogo. Ela permite que o cliente NFS abra múltiplas conexões TCP para o mesmo servidor, distribuindo a carga de tráfego entre elas (round-robin). Isso permite que o RSS da placa de rede distribua as interrupções por múltiplos núcleos da CPU.
 Figura: Escalabilidade do NFS: Impacto do nconnect no throughput agregado
Figura: Escalabilidade do NFS: Impacto do nconnect no throughput agregado
Para configurar isso corretamente, não basta apenas adicionar a flag. Você precisa alinhar o tamanho dos blocos de leitura/escrita (rsize/wsize) com o tamanho da página do sistema (geralmente 4KB) e o tamanho do bloco do sistema de arquivos subjacente.
⚠️ Perigo: Valores de
rsizeewsizeexcessivamente grandes (ex: 1MB) podem aumentar a latência em redes congestionadas devido à retransmissão TCP. Se um único pacote de 1500 bytes for perdido em um bloco de 1MB, todo o bloco pode sofrer atraso na entrega à aplicação, dependendo da implementação da pilha TCP (SACK ajuda, mas não faz milagres). O padrão de 1MB (1048576) é bom para throughput, mas teste 64KB ou 256KB se a latência for crítica.
Comando de montagem otimizado (Exemplo):
mount -t nfs -o nconnect=8,rsize=1048576,wsize=1048576,noatime,nodiratime server:/share /mnt/nfs
SMB: A ascensão do ksmbd e a eliminação do gargalo de userspace
O protocolo SMB (Server Message Block) é complexo, verborrágico e, historicamente, implementado no Linux através do Samba, que roda inteiramente em userspace. Isso significa cópias de memória constantes.
A Samsung e a comunidade Linux introduziram o ksmbd (Kernel SMB Server), que foi mergeado no kernel 5.15. O ksmbd não visa substituir o Samba para controladores de domínio ou gerenciamento complexo de identidade, mas sim para a função de servidor de arquivos de alta performance.
Ao rodar no kernel:
Zero-Copy: O
ksmbdpode pegar dados do cache de página do kernel e enviá-los diretamente para o socket de rede (viasendfileou mecanismos similares de splice), ignorando buffers de userspace.RDMA (SMB Direct): O suporte a RDMA (Remote Direct Memory Access) é muito mais eficiente no kernel, permitindo que a NIC coloque dados diretamente na memória do servidor sem acordar a CPU.
Menor Latência: Elimina-se o overhead de escalonamento de processos e IPC (Inter-Process Communication).
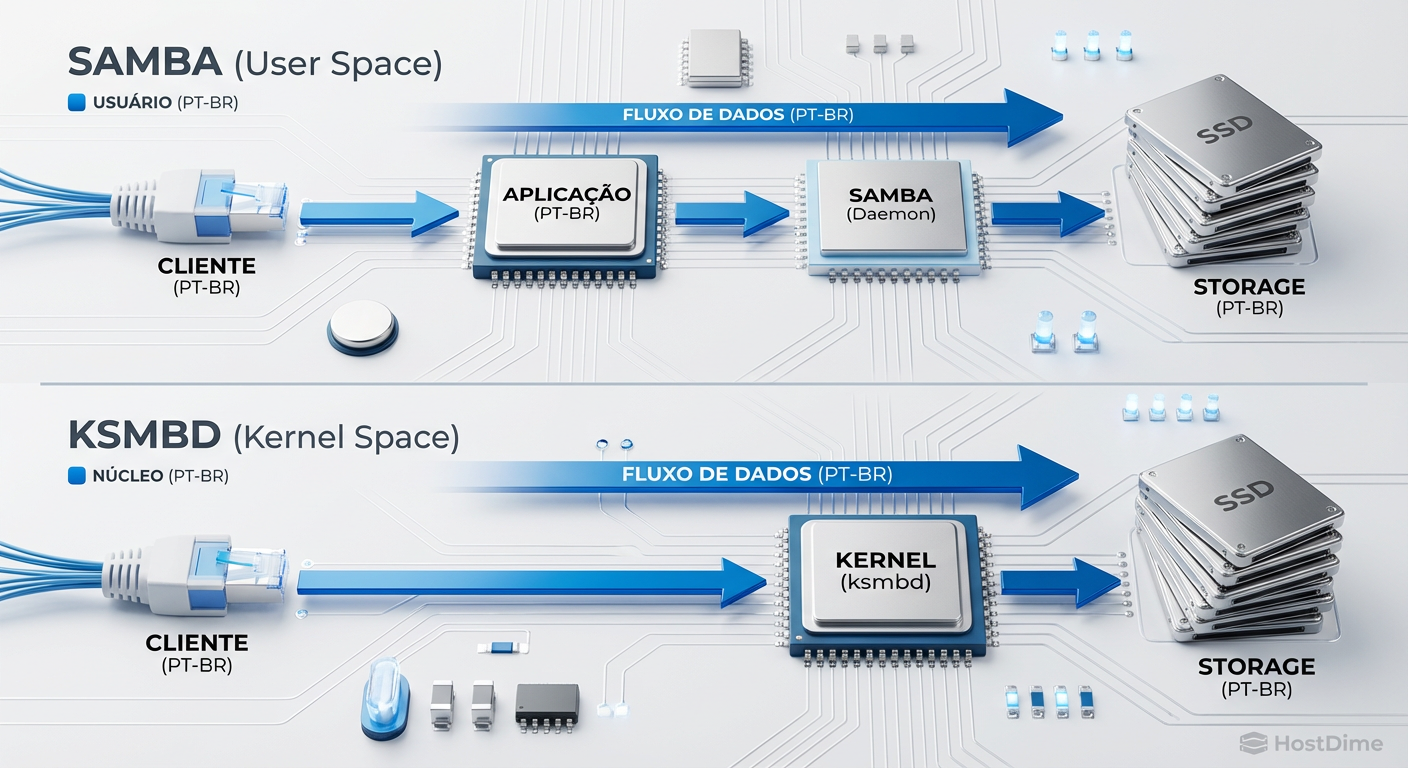 Figura: Samba vs ksmbd: A eliminação da barreira User/Kernel
Figura: Samba vs ksmbd: A eliminação da barreira User/Kernel
Para ambientes de Home Lab avançados ou Enterprise usando TrueNAS Scale (que começa a flertar com essas tecnologias) ou servidores Linux puros, o ksmbd é o futuro para saturar links de 25GbE+ com latência de NVMe local.
Validação forense: Rastreando syscalls com eBPF e fio
Não confie no "copiar e colar" do Windows Explorer. Para engenharia de performance, precisamos de ferramentas determinísticas.
1. Fio (Flexible I/O Tester)
A maioria dos benchmarks de disco são inúteis porque testam apenas o cache. Para testar a latência real da rede+disco, você deve forçar escritas síncronas e ignorar o cache do cliente.
fio --name=random_write_latency --ioengine=libaio --rw=randwrite --bs=4k --direct=1 --sync=1 --numjobs=1 --iodepth=1 --size=1G --runtime=60 --time_based --filename=/mnt/nfs_share/testfile
direct=1: Ignora cache de página (O_DIRECT).sync=1: Garante que o dado foi commitado no disco estável (O_SYNC).iodepth=1: Mede a latência pura, sem paralelismo para esconder atrasos.
2. eBPF e BCC Tools
Para ver onde o tempo está sendo gasto dentro do kernel, usamos eBPF. Ferramentas como biolatency (para disco) e tcptop são essenciais. Mas para storage de rede, o nfsslower e fileslower (do pacote bcc-tools) são reveladores.
Eles mostram quais operações de leitura/escrita estão demorando mais que um limite (ex: 10ms) e, crucialmente, mostram o tamanho e o offset. Isso permite identificar se a latência é causada por fragmentação ou contenção de bloqueio (locking).
 Figura: Flame Graph: Onde a CPU gasta tempo durante I/O intenso
Figura: Flame Graph: Onde a CPU gasta tempo durante I/O intenso
O Veredito Técnico
Não existe "melhor protocolo", existe a ferramenta certa para a carga de trabalho.
Use NFSv4.2 com
nconnectse você controla ambos os lados (cliente e servidor Linux) e precisa de throughput bruto para grandes arquivos ou virtualização. A simplicidade do protocolo e a maturidade do cliente no kernel são imbatíveis.Use SMB (preferencialmente ksmbd ou SMB Direct) se você tem clientes Windows ou precisa de compatibilidade mista. O SMB Multichannel (o equivalente ao nconnect do SMB) é excelente e ativado por padrão na maioria das implementações modernas.
A era de tunar buffers TCP (net.ipv4.tcp_rmem) manualmente acabou para 99% dos casos. O kernel moderno faz autotuning melhor que você. O foco agora deve ser: paralelismo de conexões (nconnect/multichannel), offloading de hardware real (RDMA/RoCE) e eliminação de camadas de software (ksmbd).
Se sua latência de armazenamento em rede é maior que 1ms em uma LAN local em 2025, você tem um problema de configuração, não de hardware. Pare de comprar discos mais rápidos e comece a traçar suas syscalls.
Referências & Leitura Complementar
RFC 7530: NFS Version 4 Protocol. IETF.
RFC 8881: NFS Version 4.1 Protocol (inclusão de pNFS e sessões).
MS-SMB2: Server Message Block (SMB) Protocol Versions 2 and 3. Microsoft Open Specifications.
Kernel Documentation:
Documentation/filesystems/nfs/nfsroot.txteDocumentation/networking/scaling.txt(RSS/RPS).Namjae Jeon (2021): "ksmbd: a new in-kernel SMB server". Linux Kernel Mailing List.

André Linhares
Engenheiro de Performance (Kernel/IO)
"Vivo no kernel space caçando latência com eBPF. Para mim, context switches excessivos são inimigos pessoais e cada ciclo de CPU desperdiçado é uma ofensa técnica."