NVMe-oF e IA Generativa: O Fim da Ociosidade das GPUs

Descubra como a arquitetura de armazenamento desagregado com NVMe-oF e GPUDirect elimina gargalos de I/O em clusters de IA, maximizando o ROI de GPUs H100.
Quando você aprova um orçamento milionário para um cluster de NVIDIA H100 ou as novas Blackwell, a última coisa que você quer ver no painel de monitoramento é a utilização da GPU (GPU Utilization) oscilando em 60% ou 70%. Se a GPU não está computando, ela está esperando. E no mundo da IA Generativa, tempo de espera é dinheiro incinerado.
O gargalo, historicamente situado na CPU ou na memória RAM, migrou agressivamente para o subsistema de I/O. Alimentar modelos de linguagem massivos (LLMs) com trilhões de parâmetros exige um throughput que arquiteturas de armazenamento tradicionais simplesmente não conseguem entregar de forma consistente. Não estamos falando apenas de largura de banda sequencial; estamos falando de latência determinística e acesso paralelo massivo.
Resumo em 30 segundos
- O Problema: GPUs modernas processam dados mais rápido do que o armazenamento local (DAS) ou NAS tradicional conseguem entregar, criando ociosidade (idle time).
- A Causa Raiz: O "Bounce Buffer" da CPU. Em arquiteturas legadas, os dados passam da rede para a CPU/RAM antes de chegar à GPU, criando latência e engarrafamento no barramento PCIe.
- A Solução: NVMe-oF (NVMe over Fabrics) combinado com GPUDirect Storage (GDS) permite que o storage converse diretamente com a memória da GPU, eliminando a CPU do caminho de dados.
O custo oculto da ociosidade em treinos de LLM
Diferente de um banco de dados transacional (OLTP) onde buscamos IOPS aleatórios de 4K, o padrão de acesso em treinamento de IA é uma besta diferente. Temos dois momentos críticos: o carregamento do dataset (leitura massiva, muitas vezes aleatória se houver shuffling) e o checkpointing (escrita sequencial explosiva).
O checkpointing é o assassino silencioso de performance. A cada X iterações, o estado do modelo precisa ser salvo para evitar a perda de dias de treinamento em caso de falha. Em modelos com bilhões de parâmetros, isso significa despejar terabytes de dados na camada de persistência em segundos. Se o seu storage engasga aqui, todas as GPUs do cluster param e esperam o I/O terminar.
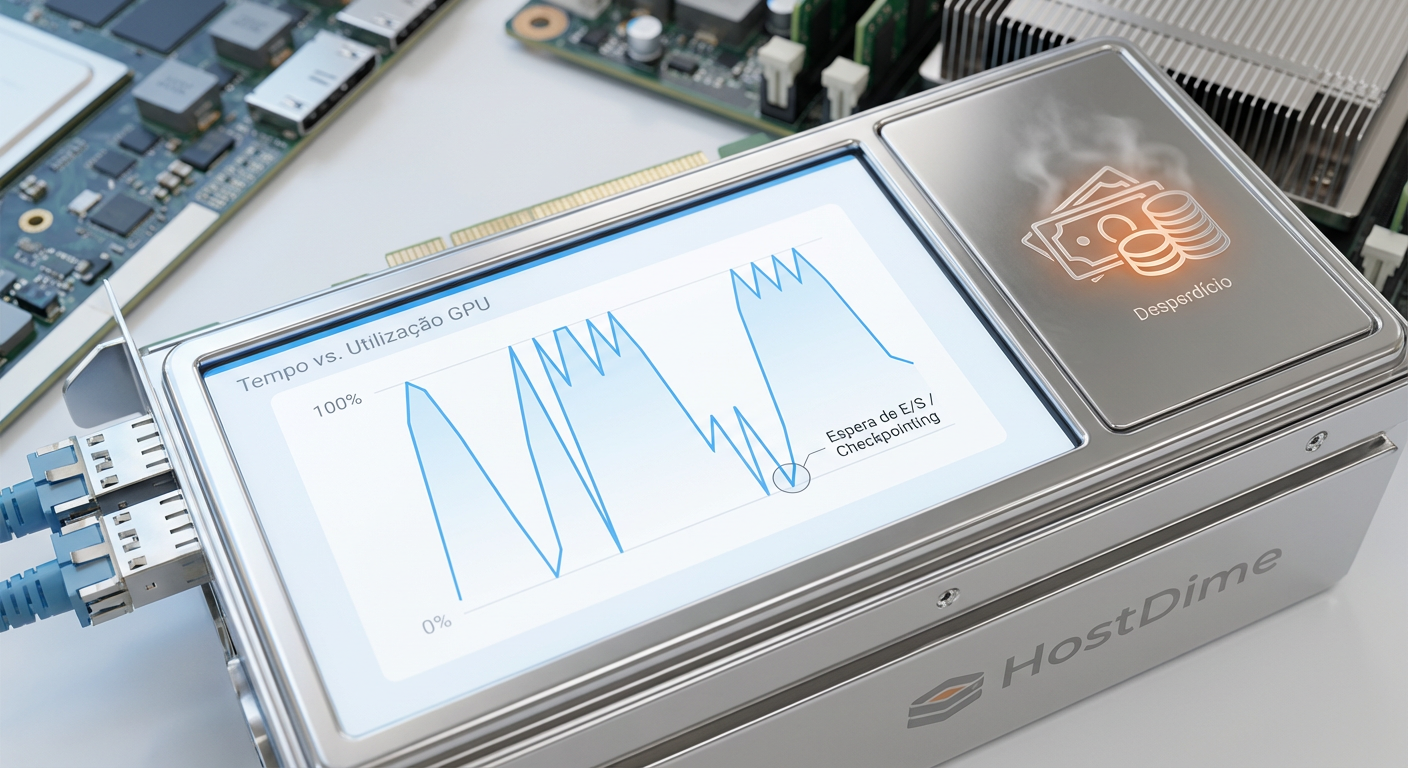 Figura: O ciclo de desperdício: Vales de utilização da GPU causados por latência de armazenamento representam prejuízo financeiro direto.
Figura: O ciclo de desperdício: Vales de utilização da GPU causados por latência de armazenamento representam prejuízo financeiro direto.
Se o seu sistema de arquivos distribuído não suportar escritas paralelas de alta largura de banda via RDMA (Remote Direct Memory Access), você transformou seu supercomputador de IA em um servidor de arquivos glorificado.
A física do gargalo: quando a CPU atrapalha
Na arquitetura clássica de servidores x86, quando uma aplicação precisa ler um dado do disco para a GPU, ocorre uma dança ineficiente chamada "Bounce Buffer":
O controlador de disco (NVMe) envia os dados para a memória do sistema (DRAM) via PCIe.
A CPU gerencia essa interrupção e aloca os dados.
A CPU copia os dados da DRAM para a memória da GPU (HBM), novamente via PCIe.
⚠️ Perigo: Esse processo consome ciclos preciosos da CPU e, pior, duplica o tráfego no barramento PCIe. Em um servidor com 8 GPUs famintas, a CPU se torna o gargalo, incapaz de copiar dados rápido o suficiente, mesmo que os discos SSD NVMe subjacentes estejam sobrando em performance.
Por que o DAS (Direct Attached Storage) falha em escala
Muitos arquitetos tentam resolver isso enchendo os nós de computação com NVMe locais (DAS). Funciona bem para um único servidor. Falha catastroficamente em um cluster.
Treinamento de IA é um esporte de equipe distribuído. O dataset de treinamento (ex: Common Crawl, ImageNet) precisa ser acessível por todos os nós simultaneamente. Se você usa DAS, precisa replicar o dataset em cada nó (ineficiente e caro) ou criar um mecanismo complexo de sharding e cópia via rede, que reintroduz a latência que você tentou evitar.
A solução é desagregar: separar computação de armazenamento, mas manter a performance de local. É aqui que entra o NVMe-oF.
Arquitetura desagregada via NVMe-oF
NVMe over Fabrics (NVMe-oF) não é apenas "usar discos rápidos na rede". É uma extensão do protocolo NVMe que permite encapsular comandos NVMe dentro de pacotes de rede (Ethernet, InfiniBand ou Fibre Channel), mantendo a eficiência da fila de comandos e o paralelismo do protocolo original.
Ao contrário do iSCSI ou NFS tradicionais, que dependem pesadamente da pilha TCP/IP do kernel do sistema operacional (e portanto, da CPU), o NVMe-oF moderno, especialmente quando pareado com RDMA (RoCE v2), permite Zero-Copy.
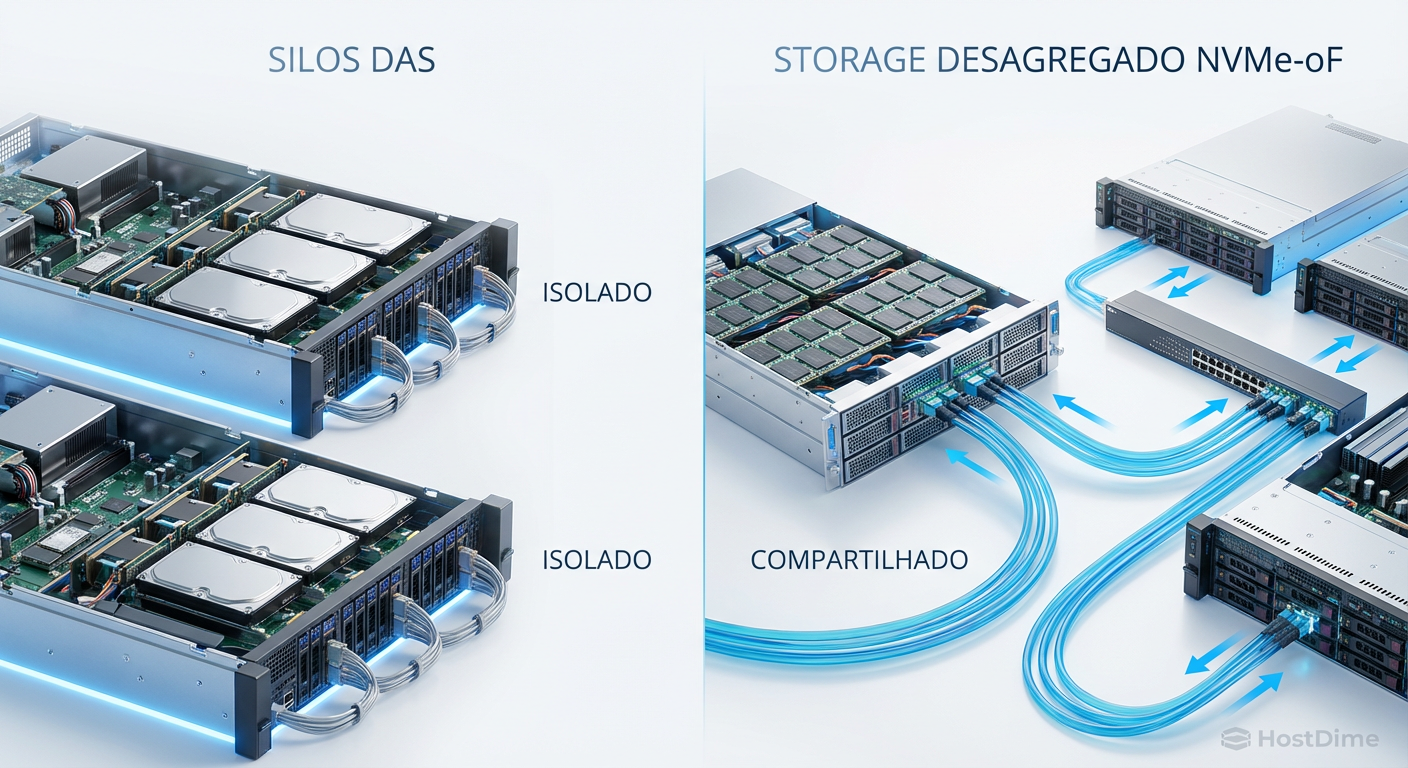 Figura: Comparativo arquitetural: A rigidez dos silos DAS versus a flexibilidade e escalabilidade do armazenamento desagregado via NVMe-oF.
Figura: Comparativo arquitetural: A rigidez dos silos DAS versus a flexibilidade e escalabilidade do armazenamento desagregado via NVMe-oF.
Tabela Comparativa: Protocolos de Transporte para IA
Para cargas de trabalho de IA, a escolha do transporte é crítica. Veja como eles se comportam no mundo real:
| Característica | NVMe Local (DAS) | NVMe-oF (RoCE v2) | NVMe/TCP | NFS (Padrão) |
|---|---|---|---|---|
| Latência Adicional | N/A (Base) | < 5 µs (Microssegundos) | 10-30 µs | > 100 µs |
| Uso de CPU (Host) | Alto (Cópia de Memória) | Baixo (Offload na NIC) | Médio/Alto | Muito Alto |
| Escalabilidade | Limitada ao chassi | Escala Petabytes | Escala Petabytes | Escala Petabytes |
| Complexidade de Rede | Nenhuma | Alta (Exige DCB/PFC - Lossless) | Média (Ethernet Padrão) | Baixa |
| Adequação para IA | Baixa (Silos de dados) | Ideal (Alta Performance) | Boa (Custo-Benefício) | Inadequada |
O papel do GPUDirect Storage (GDS)
Aqui acontece a mágica. O GPUDirect Storage, uma tecnologia promovida pela NVIDIA (mas com conceitos aplicáveis a outros aceleradores), quebra o paradigma do "Bounce Buffer".
Com GDS e NVMe-oF, a placa de rede (NIC ou HCA) do servidor de armazenamento envia os dados diretamente para a placa de rede do servidor de computação, que por sua vez deposita os dados diretamente na memória HBM da GPU, via DMA (Direct Memory Access).
A CPU do servidor de computação mal sabe que a transferência ocorreu. Ela fica livre para gerenciar o agendamento de kernels, pré-processamento leve ou outras tarefas de orquestração, enquanto o pipeline de dados flui como uma mangueira de incêndio direto para a GPU.
💡 Dica Pro: Para habilitar o GDS, não basta ter o hardware. O sistema de arquivos (ex: Weka, VAST Data, Lustre, IBM Storage Scale) precisa suportar explicitamente as APIs do NVIDIA Magnum IO. Sem isso, o GDS não ativa e você volta para o caminho lento da CPU.
 Figura: O caminho crítico: GPUDirect Storage cria uma via expressa entre o armazenamento e a GPU, ignorando completamente a CPU e a memória do sistema.
Figura: O caminho crítico: GPUDirect Storage cria uma via expressa entre o armazenamento e a GPU, ignorando completamente a CPU e a memória do sistema.
Considerações de Rede: RoCE v2 vs. TCP
Como DBA ou Arquiteto de Storage, você sabe que a rede é culpada até que se prove o contrário. No NVMe-oF, isso é duplamente verdade.
RoCE v2 (RDMA over Converged Ethernet)
É o padrão ouro para performance. Ele exige uma rede "Lossless" (sem perda de pacotes). Isso significa configurar Priority Flow Control (PFC) e Explicit Congestion Notification (ECN) nos seus switches. Se um pacote é dropado, a retransmissão no RoCE é custosa e mata a latência de cauda. Configurar uma rede RoCE v2 robusta é complexo e exige switches de classe Data Center (Mellanox/NVIDIA Spectrum, Arista, Cisco Nexus).
NVMe/TCP
Utiliza a infraestrutura Ethernet padrão. Com o advento de SmartNICs e DPUs (Data Processing Units), o overhead do TCP foi mitigado, mas não eliminado. É mais fácil de implementar porque o TCP lida nativamente com retransmissões e congestionamento. Para inferência ou fine-tuning leve, pode ser suficiente. Para treinamento pesado de Foundation Models, o RoCE v2 ainda reina supremo.
O Veredito Arquitetural
Não trate o armazenamento de IA como um repositório de arquivos convencional. A ociosidade da GPU é um problema de arquitetura de dados, não de falta de capacidade computacional.
Se você está desenhando a infraestrutura para a próxima geração de modelos de IA, a recomendação é clara:
Desagregue: Use arrays All-Flash NVMe conectados via rede de alta velocidade (400GbE/NDR InfiniBand).
Implemente RDMA: O NVMe-oF RoCE v2 é mandatório para manter as GPUs alimentadas.
Exija GDS: Certifique-se de que seu fornecedor de storage (seja appliance ou SDS) tenha suporte nativo e certificado para GPUDirect Storage.
Ignorar a camada de I/O em um projeto de IA é como colocar um motor de Ferrari em um chassi de fusca: vai fazer muito barulho, gastar muita gasolina, mas não vai sair do lugar na velocidade que você pagou para ter.
Referências & Leitura Complementar
NVIDIA GPUDirect Storage Design Guide: Documentação técnica detalhando a arquitetura de bypass de CPU e integração com Magnum IO.
NVM Express Base Specification 2.0: Especificações oficiais da organização NVM Express detalhando os transportes NVMe over Fabrics.
SNIA (Storage Networking Industry Association): Whitepapers sobre a implementação de RDMA e RoCE v2 em ambientes Enterprise.
RFC 5040: Especificação do protocolo RDMA over Converged Ethernet (RoCE).
Qual a diferença prática entre NVMe-oF RoCE v2 e NVMe/TCP para IA?
O RoCE v2 oferece a menor latência possível e zero-copy via RDMA, sendo a escolha obrigatória para clusters de treinamento de alta performance onde cada microssegundo conta. O NVMe/TCP utiliza a infraestrutura Ethernet padrão e o protocolo TCP; é mais flexível, mais barato e mais fácil de configurar, mas impõe uma ligeira penalidade de latência e consome mais ciclos de CPU (a menos que offloaded por SmartNICs), sendo mais adequado para inferência ou cargas menos críticas.O que é GPUDirect Storage (GDS) e por que ele é crítico?
O GDS é uma tecnologia que permite que a GPU leia e escreva dados diretamente do armazenamento NVMe (via rede ou local), ignorando completamente a CPU e a memória RAM do sistema. Isso elimina o efeito "bounce buffer" (cópia dupla de dados), reduzindo drasticamente a latência, aumentando a largura de banda efetiva e liberando a CPU para tarefas de orquestração e pré-processamento.Armazenamento desagregado não aumenta a latência comparado ao DAS?
Em teoria, a física dita que a rede adiciona latência. Na prática, com NVMe-oF bem arquitetado (especialmente RoCE v2 em 400GbE/InfiniBand), a latência adicional é na casa dos baixos microssegundos, tornando-se negligenciável para a aplicação. Em contrapartida, ganha-se a capacidade de escalar performance e capacidade independentemente, evitando os "silos de dados" do DAS que paralisam pipelines de IA ao exigir cópias manuais de datasets entre nós.
Roberto Lemos
Arquiteto de Workloads
"Projeto infraestrutura onde o perfil de I/O dita as regras. Sei que a latência do acesso aleatório de um banco difere da vazão sequencial de vídeos. Mapeio o hardware exato para cada aplicação."