NVMe-oF/TCP vs iSCSI: Análise crítica de latência e overhead para DBAs

Descubra por que o iSCSI é o gargalo dos seus SSDs modernos. Comparativo técnico de NVMe-oF/TCP vs iSCSI focado em latência, CPU e filas de comando.
Você já passou por isso. O orçamento foi aprovado, o All-Flash Array (AFA) chegou e a rede foi atualizada para 25GbE ou até 100GbE. A expectativa era ver os eventos de espera do banco de dados desaparecerem. Mas, na segunda-feira de manhã, o dashboard de monitoramento mostra uma história diferente. O throughput aumentou, mas a latência de commit — aquele log file sync no Oracle ou WRITELOG no SQL Server — continua teimosa, oscilando perigosamente nos picos de carga.
O problema não é a velocidade da luz na fibra, nem a capacidade dos seus SSDs NVMe backend. O problema é o protocolo que você está usando para falar com eles. Tratar um array NVMe moderno com o protocolo iSCSI é como tentar beber um oceano através de um canudo de papel: funciona por um tempo, mas a física do fluxo eventualmente colapsa sob pressão.
Neste artigo, vamos dissecar a arquitetura de armazenamento para entender por que a pilha SCSI se tornou o maior gargalo em ambientes transacionais e como o NVMe over Fabrics (NVMe-oF) via TCP resolve a equação de latência sem exigir uma reformulação completa da sua infraestrutura de rede.
Resumo em 30 segundos
- Largura de Banda ≠ Latência: Upgrades de rede (10GbE para 25GbE) resolvem problemas de throughput, mas fazem pouco pela latência transacional se o protocolo de transporte for ineficiente.
- O Gargalo SCSI: O iSCSI força comandos serializados e traduções pesadas de protocolo, anulando o paralelismo nativo dos SSDs NVMe modernos.
- NVMe/TCP é a Evolução: Permite filas profundas e paralelas (até 64k filas) sobre Ethernet padrão, reduzindo drasticamente o overhead de CPU por I/O e eliminando a latência de cauda.
O impacto silencioso do 'log file sync' em redes de 25GbE
Para um DBA, o disco não é apenas um lugar onde os dados repousam; é o componente que dita a velocidade do commit. Em bancos de dados relacionais (RDBMS) que garantem propriedades ACID, nenhuma transação é considerada concluída até que o log de redo/transação seja persistido em mídia estável.
Aqui reside a armadilha da largura de banda. Muitos arquitetos de infraestrutura confundem "tubo maior" com "viagem mais rápida". Mover de 10GbE para 25GbE aumenta a quantidade de dados que você pode empurrar por segundo (throughput), o que é ótimo para backups ou Full Table Scans em Data Warehouses. No entanto, para um workload OLTP (Online Transaction Processing), o padrão de acesso é dominado por escritas pequenas, aleatórias e síncronas.
Quando seu banco de dados solicita uma gravação de 4KB ou 8KB no log de transação, ele para e espera. O tempo que essa operação leva para ir ao storage e voltar é latência pura. Em redes iSCSI tradicionais, mesmo com links rápidos, o tempo de processamento do protocolo (overhead de software) frequentemente excede o tempo que o dado leva para trafegar no fio.
💡 Dica Pro: Se o seu Average Log Write Time está acima de 1ms em um All-Flash Array, pare de olhar para os discos e comece a olhar para a pilha de protocolo e as filas do HBA/NIC. O flash é rápido; o caminho até ele é que está congestionado.
A pilha SCSI e o custo oculto da serialização
O iSCSI (Internet Small Computer Systems Interface) foi um cavalo de batalha heroico. Ele permitiu a democratização das SANs (Storage Area Networks) usando Ethernet barato. Mas ele carrega um legado dos anos 80: o conjunto de comandos SCSI.
O SCSI foi projetado em uma era de discos rotativos mecânicos (HDDs) e fitas. Discos mecânicos têm uma cabeça de leitura física. Eles só podem fazer uma coisa de cada vez. Portanto, o protocolo SCSI foi desenhado para ser serial. O sistema operacional envia um comando, o disco processa, a cabeça se move, o dado é gravado, e o próximo comando entra.
O ciclo da ineficiência
Quando você usa SSDs NVMe dentro de um storage array, mas os acessa via iSCSI, ocorre um processo brutal de tradução:
O Banco de Dados emite um I/O.
O OS encapsula isso em um comando SCSI.
O driver iSCSI encapsula o SCSI em TCP/IP.
O pacote viaja pela rede.
O Storage Array recebe o pacote, desencapsula o TCP, desencapsula o SCSI.
O ponto crítico: O controlador do storage precisa traduzir esse comando SCSI antigo para um comando NVMe moderno para falar com o SSD backend.
Essa tradução consome ciclos de CPU preciosos (tanto no host quanto no storage) e adiciona latência. Pior ainda, o iSCSI tradicionalmente opera com uma única fila de comandos (ou muito poucas), criando um efeito de funil. Você tem um backend capaz de milhões de IOPS, mas está alimentando-o com uma colher de chá.
 Figura: Comparação da Pilha de Protocolos: A complexidade da tradução SCSI vs a eficiência direta do NVMe.
Figura: Comparação da Pilha de Protocolos: A complexidade da tradução SCSI vs a eficiência direta do NVMe.
A arquitetura do NVMe/TCP e o paralelismo de filas profundas
O NVMe (Non-Volatile Memory Express) não é apenas "SSD mais rápido". É um protocolo desenhado do zero para mídias não voláteis de baixa latência. A grande revolução não é a velocidade, é o paralelismo.
Enquanto o SAS/SATA (e por extensão o SCSI) lidava com uma fila com profundidade de 32 ou 256 comandos, o NVMe suporta 64.000 filas, cada uma com 64.000 comandos de profundidade.
O NVMe over Fabrics (NVMe-oF) estende essa arquitetura através da rede. Existem vários transportes (Fibre Channel, RoCE, InfiniBand), mas o NVMe/TCP é o que muda o jogo para a maioria dos datacenters. Por quê? Porque ele roda na sua infraestrutura Ethernet existente.
Como o NVMe/TCP elimina o gargalo
Diferente do iSCSI, o NVMe/TCP não precisa traduzir comandos. O comando NVMe é encapsulado diretamente em frames TCP. O paralelismo é mantido do host até o disco:
Mapeamento de Filas: O driver NVMe no host cria múltiplos pares de filas (Queue Pairs) que mapeiam diretamente para os núcleos da CPU.
Sem Bloqueio (Lockless): Cada núcleo de CPU pode enviar I/O para o storage independentemente, sem precisar brigar por um lock global de uma única fila SCSI.
Binding: As conexões TCP são persistentes e vinculadas a filas específicas, garantindo que a resposta do I/O volte para o mesmo núcleo que a solicitou, maximizando a eficiência do cache L1/L2 do processador.
 Figura: Visualização do Paralelismo: O gargalo da fila única do SCSI versus as múltiplas filas de I/O do NVMe.
Figura: Visualização do Paralelismo: O gargalo da fila única do SCSI versus as múltiplas filas de I/O do NVMe.
Comparativo de overhead de CPU e IOPS
Um mito comum que circula entre administradores de sistemas é que "NVMe/TCP consome muita CPU". Isso é uma meia-verdade que precisa ser contextualizada para DBAs.
Sim, se você empurrar 1 milhão de IOPS via NVMe/TCP, você verá um uso de CPU maior do que se empurrasse 100.000 IOPS via iSCSI. Mas o custo por I/O é drasticamente menor.
No iSCSI, o processamento de interrupções e a tradução de protocolo geram um overhead fixo alto. O sistema gasta muitos ciclos apenas gerenciando a "burocracia" do transporte. No NVMe/TCP, especialmente com implementações modernas que usam técnicas de Zero-Copy (evitando cópias desnecessárias de dados na memória RAM) e Polling (o driver verifica ativamente a conclusão do I/O em vez de esperar uma interrupção), a eficiência é superior.
Tabela Comparativa: iSCSI vs NVMe/TCP
| Característica | iSCSI (SCSI sobre TCP) | NVMe-oF / TCP | Impacto para o DBA |
|---|---|---|---|
| Modelo de Filas | Serial (Fila única ou poucas) | Massivamente Paralelo (até 64k filas) | NVMe elimina contenção em cargas concorrentes altas. |
| Profundidade de Fila | Limitada (Tipicamente 32-256) | Extrema (64k comandos por fila) | Suporta picos de I/O sem enfileiramento no host. |
| Overhead de Protocolo | Alto (Tradução SCSI <-> Block) | Baixo (Pass-through de comandos NVMe) | Menor latência de CPU = commits mais rápidos. |
| Requisito de Rede | Ethernet Padrão (TCP/IP) | Ethernet Padrão (TCP/IP) | Sem necessidade de switches caros ou proprietários. |
| Latência Típica | 200µs - 1ms+ (adicional à mídia) | 10µs - 50µs (adicional à mídia) | Redução direta no tempo de espera do usuário final. |
| Mecanismo de Entrega | Baseado em Interrupções | Híbrido (Interrupções ou Polling) | Polling reduz latência em cargas ultra-intensivas. |
⚠️ Perigo: Cuidado com configurações de MTU (Maximum Transmission Unit). Tanto para iSCSI quanto para NVMe/TCP, o uso de Jumbo Frames (MTU 9000) é praticamente obrigatório para reduzir a taxa de pacotes por segundo e aliviar a CPU. Rodar NVMe/TCP com MTU 1500 é pedir para ter problemas de performance.
Por que upgrades de largura de banda falham em reduzir a latência de cauda
A "latência de cauda" (tail latency) é o pesadelo do DBA. É aquele 1% das transações (P99 ou P99.9) que demora 10x mais que a média. Em um e-commerce, isso significa carrinhos abandonados.
Em ambientes iSCSI, a latência de cauda ocorre frequentemente devido ao fenômeno de Head-of-Line Blocking. Se um pacote TCP é perdido ou se um comando SCSI grande bloqueia a fila, todos os comandos pequenos e rápidos que vêm atrás precisam esperar. Aumentar a banda de 10GbE para 100GbE não resolve isso, pois a fila lógica continua bloqueada.
O NVMe/TCP mitiga isso através da diversidade de filas. Se uma fila está ocupada ou sofrendo retransmissão TCP, as outras 63.999 filas continuam fluindo. Para bancos de dados transacionais, isso resulta em uma curva de latência muito mais previsível e "apertada".
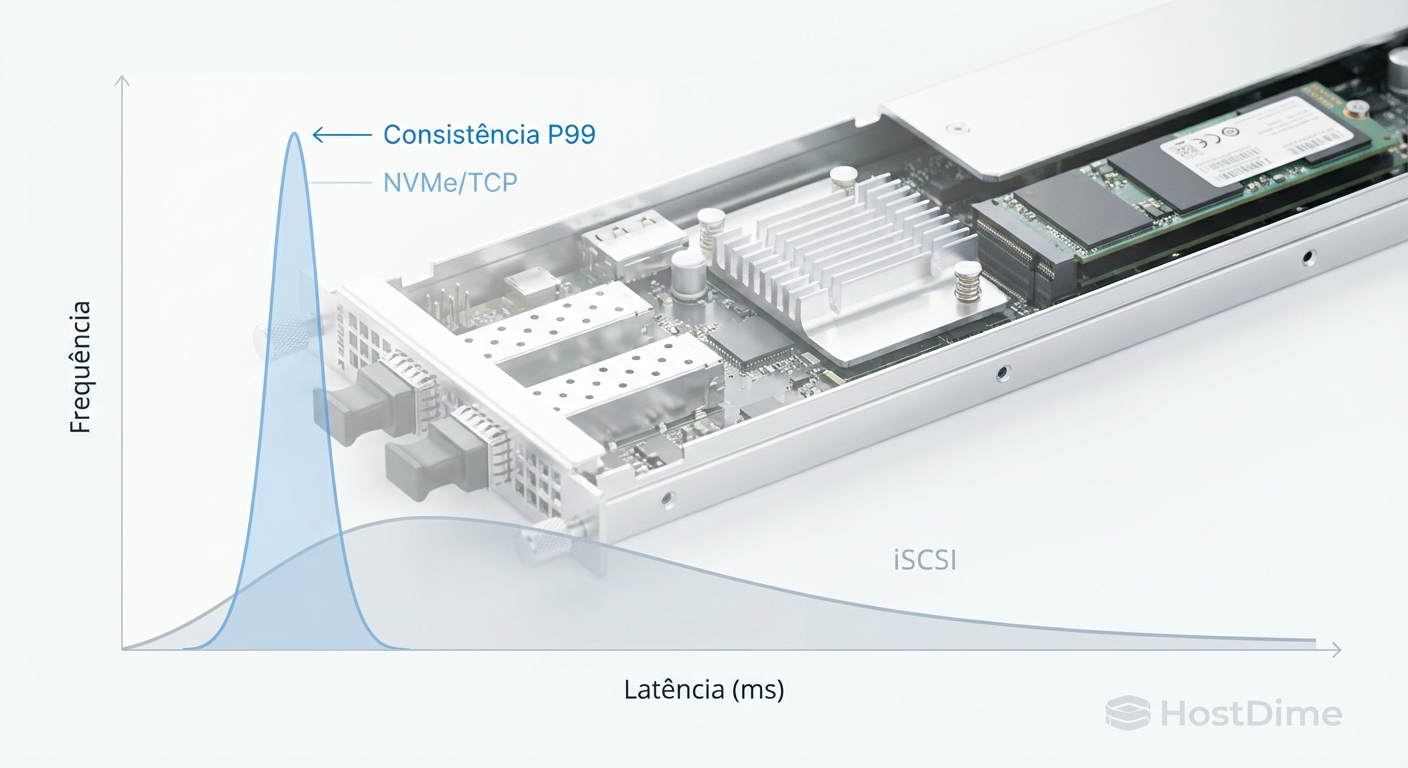 Figura: Histograma de Latência: A consistência do NVMe/TCP (curva estreita) versus a imprevisibilidade do iSCSI (cauda longa).
Figura: Histograma de Latência: A consistência do NVMe/TCP (curva estreita) versus a imprevisibilidade do iSCSI (cauda longa).
Veredito Técnico
Se você gerencia bancos de dados críticos em infraestrutura on-premises ou colocation, a era do iSCSI para armazenamento primário All-Flash acabou. A compatibilidade legada não justifica mais o imposto de performance que a pilha SCSI cobra de cada transação.
Não espere que o NVMe/TCP transforme magicamente discos SATA antigos em foguetes. Mas, se você já investiu em Arrays All-Flash NVMe, continuar usando iSCSI é como comprar uma Ferrari e colocar pneus de bicicleta. O hardware está pronto; o gargalo agora é puramente uma escolha de configuração.
Minha recomendação para os próximos 12 a 24 meses: planeje a migração de seus LUNs de alta performance para namespaces NVMe/TCP. A infraestrutura de rede (switches e cabos) provavelmente já suporta isso. O ganho de eficiência na CPU e a estabilidade na latência de cauda justificarão o esforço na primeira Black Friday ou fechamento mensal que você enfrentar.
FAQ: Perguntas Frequentes de DBAs e Arquitetos
O NVMe/TCP exige hardware de rede proprietário como o RoCE?
Não. Diferente do NVMe-oF sobre RoCE (RDMA over Converged Ethernet) ou InfiniBand, que exigem switches com suporte a DCB/PFC (Flow Control) e NICs especiais, o NVMe/TCP funciona na infraestrutura Ethernet padrão. Seus switches e placas de rede atuais, desde que tenham largura de banda suficiente, são compatíveis, pois ele utiliza a pilha TCP/IP existente.Qual o impacto real na CPU ao migrar de iSCSI para NVMe/TCP?
Embora o NVMe/TCP possa apresentar um consumo de CPU total maior em benchmarks sintéticos (simplesmente porque ele consegue entregar muito mais IOPS que o iSCSI), a eficiência é superior. O custo de CPU *por I/O* é significativamente menor devido à eliminação da tradução SCSI e ao uso de mecanismos modernos como Zero-Copy e Polling. Em resumo: você gasta CPU movendo dados, não lutando com o protocolo.O iSCSI ainda faz sentido para algum workload?
Sim. O iSCSI continua sendo uma opção válida e robusta para repositórios de backup, arquivamento, ou volumes que residem em HDDs mecânicos (spinning rust). Nesses cenários, onde a latência de microssegundos não é o fator crítico e a mídia física é o gargalo, a compatibilidade universal e a facilidade de gestão do iSCSI ainda vencem.Referências & Leitura Complementar
NVM Express Base Specification 2.0: Documentação oficial sobre a arquitetura de filas e comandos NVMe.
NVM Express over Fabrics (NVMe-oF) Specification: Detalhes sobre o binding de transporte TCP e encapsulamento.
SNIA (Storage Networking Industry Association): "Performance Analysis of NVMe/TCP vs iSCSI" (Whitepapers técnicos variados da indústria).
Linux Kernel Documentation:
Documentation/block/blk-mq.rst(Para entender o funcionamento do Block Multi-Queue no Linux, essencial para NVMe).

Roberto Lemos
Arquiteto de Workloads
"Projeto infraestrutura onde o perfil de I/O dita as regras. Sei que a latência do acesso aleatório de um banco difere da vazão sequencial de vídeos. Mapeio o hardware exato para cada aplicação."