NVMe over TCP: Escalando IOPS em Ethernet padrão sem a complexidade do RDMA

Abandone o iSCSI. Guia técnico para arquitetos de banco de dados sobre como implementar NVMe/TCP, eliminar gargalos de CPU e reduzir a latência de cauda (p99) em redes Ethernet padrão.
Se você passou a última década otimizando queries SQL e ajustando buffer_pool_size, sabe que o hardware de armazenamento mudou drasticamente. Saímos de discos mecânicos que lutavam para entregar 150 IOPS para arrays All-Flash capazes de saturar qualquer barramento. O problema, no entanto, deixou de ser o disco. O gargalo agora é como os dados chegam até a CPU.
Durante anos, a resposta da indústria para alta performance em rede foi o RDMA (Remote Direct Memory Access), via RoCE ou iWARP. Embora tecnicamente superior por fazer bypass da CPU, a complexidade de configurar uma rede lossless (sem perda de pacotes) com PFC (Priority Flow Control) e ECN transformou a vida de muitos arquitetos em um pesadelo de gestão.
É aqui que o NVMe over TCP (NVMe/TCP) entra. Ele promete performance próxima ao RDMA usando a infraestrutura Ethernet padrão que você já tem. Mas não se engane: "padrão" não significa "plug-and-play" para cargas de banco de dados. Se você tratar um volume NVMe/TCP como se fosse um compartilhamento SMB, sua latência de cauda (tail latency) destruirá seus SLAs.
Resumo em 30 segundos
- O mito do "Custo Zero": O NVMe/TCP transfere a complexidade do hardware (switches dedicados) para a CPU do host. Sem otimização, o processamento de pacotes TCP compete diretamente com seu banco de dados por ciclos de processamento.
- Latência vs. Throughput: Configurações padrão de rede priorizam largura de banda (bom para streaming). Bancos de dados precisam de latência baixa e determinística. Otimizações de driver e kernel são obrigatórias.
- Alinhamento de Filas (ADQ): A chave para performance é garantir que a solicitação de I/O saia e volte processada pelo mesmo núcleo de CPU, mantendo o cache L1/L2 quente e evitando trocas de contexto.
O custo oculto dos ciclos de CPU no processamento de I/O
Quando falamos de armazenamento local (Direct Attached Storage - DAS), o protocolo NVMe foi desenhado para ser eficiente. Ele reduziu a pilha de comandos, aumentou o paralelismo (64 mil filas) e eliminou a necessidade de ciclos de clock excessivos para tradução de endereços.
Ao movermos isso para a rede via TCP, reintroduzimos um intermediário pesado: a pilha de rede do Kernel Linux (ou Windows/VMware). Cada pacote que chega precisa ser inspecionado, remontado, verificado (checksum) e copiado da memória do kernel para a memória do usuário (onde seu Oracle, PostgreSQL ou SQL Server reside).
Para um DBA, isso é aterrorizante. Cada ciclo gasto desembrulhando um pacote TCP é um ciclo a menos executando uma transação. Em testes de carga com NICs de 100GbE, é comum ver um núcleo de CPU saturado (100% de uso) apenas lidando com interrupções de rede, enquanto o banco de dados em si fica "fome" (starved) esperando os dados.
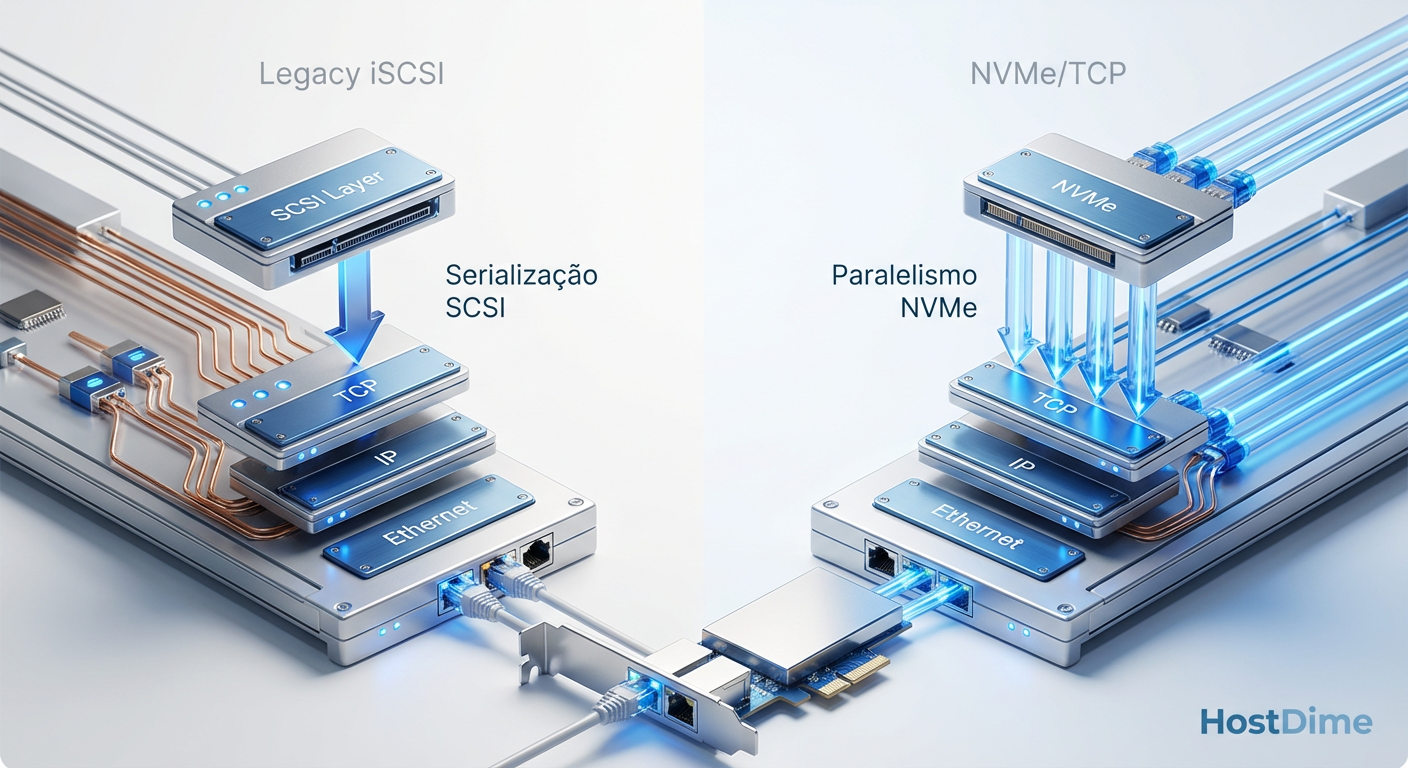 Fig. 1: A eliminação da camada de tradução SCSI reduz ciclos de CPU e latência.
Fig. 1: A eliminação da camada de tradução SCSI reduz ciclos de CPU e latência.
Isso cria um cenário onde o armazenamento é rápido (latência de mídia < 100µs), a rede é rápida, mas a latência percebida pela aplicação sobe para 1ms ou mais devido ao congestionamento na CPU do host.
A anatomia da pilha TCP e o gargalo de interrupções (SoftIRQ)
Para entender por que isso acontece, precisamos olhar para o mecanismo de SoftIRQ (Software Interrupts). Quando um pacote de dados chega na placa de rede (NIC), ela dispara uma interrupção de hardware. A CPU para o que está fazendo para atender essa interrupção.
Em sistemas modernos, para evitar parar a CPU a cada microsegundo, usamos o NAPI (New API) e interrupt coalescing (agrupamento de interrupções). O hardware acumula alguns pacotes e avisa a CPU uma vez. O kernel então processa esses pacotes em lote via SoftIRQ.
O problema surge na distribuição dessas interrupções. Se o processamento do SoftIRQ ocorrer no "Core 0" e seu banco de dados estiver rodando no "Core 1", temos um desastre de performance:
Os dados são gravados no cache L1/L2 do Core 0.
O banco de dados no Core 1 solicita os dados.
Ocorre um Cache Miss.
Os dados precisam transitar pelo barramento de interconexão da CPU (ex: Intel UPI ou AMD Infinity Fabric) para chegar ao Core 1.
⚠️ Perigo: Em arquiteturas NUMA (Non-Uniform Memory Access), se a placa de rede estiver conectada ao Socket A e o processo do banco de dados estiver no Socket B, a latência pode dobrar. O NVMe/TCP é impiedoso com má configuração de afinidade NUMA.
Por que a configuração padrão de Ethernet mata a performance do NVMe
A maioria das configurações "padrão" de servidores Linux e Windows é otimizada para tráfego genérico (servidores web, transferência de arquivos). O objetivo desses perfis é maximizar o Throughput (GB/s), muitas vezes às custas da latência.
Existem três vilões principais na configuração padrão que você deve auditar imediatamente em seus hosts de armazenamento:
1. LRO e GRO (Large Receive/Generic Receive Offload)
Essas técnicas agrupam pacotes pequenos em um super-pacote antes de passá-los para a pilha de rede. Para transferir um arquivo de vídeo de 50GB, isso é ótimo. Para um banco de dados fazendo random reads de 8KB, isso é veneno. O sistema operacional "segura" o primeiro pacote esperando outros chegarem para agrupá-los, introduzindo latência artificial.
2. Algoritmo de Nagle (TCP_NODELAY)
O TCP tenta ser eficiente não enviando pacotes pequenos. Ele espera ter dados suficientes para preencher um segmento. Em storage, cada comando de leitura ou escrita é crítico. O atraso do Nagle pode adicionar milissegundos preciosos. Implementações de NVMe/TCP geralmente desativam isso, mas configurações de switch ou proxies intermediários podem reintroduzi-lo.
3. Controle de Fluxo Ethernet (Pause Frames)
Embora o NVMe/TCP lide bem com perda de pacotes (ao contrário do RoCEv1), o controle de fluxo excessivo em switches congestionados pode causar pausas em toda a transmissão. Diferente do Fibre Channel, que tem buffer credits gerenciados hardware-a-hardware, o TCP depende de retransmissão e janelas de congestionamento.
Otimização via ADQ e alinhamento de filas para reduzir latência
A solução para o problema da CPU e do cache frio chama-se ADQ (Application Device Queues). Embora seja um termo muito associado à Intel, o conceito de alinhamento de filas se aplica a qualquer NIC moderna de alta performance (Mellanox/NVIDIA, Broadcom).
A ideia é segregar o tráfego. Em vez de jogar todos os pacotes em um balde comum que qualquer núcleo da CPU pode ter que processar, criamos "pistas expressas".
O ADQ permite que você configure a placa de rede para dedicar filas de hardware específicas para o tráfego NVMe/TCP e, crucialmente, mapear essas filas para núcleos de CPU específicos que também estão rodando a aplicação (ou threads de I/O do banco).
 Fig. 2: O alinhamento de filas (ADQ) evita o 'Context Switching' excessivo, mantendo o cache da CPU quente.
Fig. 2: O alinhamento de filas (ADQ) evita o 'Context Switching' excessivo, mantendo o cache da CPU quente.
O efeito do alinhamento perfeito
Quando alinhamos a fila da NIC, o processamento do SoftIRQ e a thread do banco de dados no mesmo núcleo (ou núcleos irmãos):
Cache Locality: Os dados do pacote TCP já estão no cache L2 quando a aplicação vai lê-los.
Menor Context Switching: O kernel gasta menos tempo movendo processos entre núcleos.
Previsibilidade: O tráfego "ruidoso" (SSH, logs, monitoramento) não impacta as filas dedicadas ao Storage.
💡 Dica Pro: Ao configurar NVMe/TCP em Linux, utilize o
irqbalancecom cuidado ou desative-o em favor de scripts manuais de afinidade (set_irq_affinity) se você estiver usando ADQ ou tecnologias similares. O balanceamento automático muitas vezes toma decisões erradas para cargas de latência ultrabaixa.
Comparativo de latência p99 entre iSCSI e NVMe/TCP otimizado
Muitos administradores migram de iSCSI para NVMe/TCP esperando um ganho imediato. Se o teste for apenas de largura de banda sequencial, a diferença é pequena. O iSCSI em 100GbE é muito rápido.
A diferença brutal aparece no p99 (o 99º percentil da latência) e no p999. É aqui que o banco de dados "engasga". O iSCSI, por carregar o legado do protocolo SCSI, exige mais traduções e serialização de comandos.
Em testes controlados de workload transacional (OLTP, bloco de 8KB, 70/30 Read/Write):
iSCSI: Latência média de 0.8ms, mas p99 de 5ms a 10ms. Esses picos de 10ms são os momentos em que sua aplicação trava brevemente.
NVMe/TCP (Padrão): Latência média de 0.4ms, p99 de 2ms. Melhor, mas instável.
NVMe/TCP (Com ADQ/Alinhamento): Latência média de 0.25ms, p99 de 0.45ms.
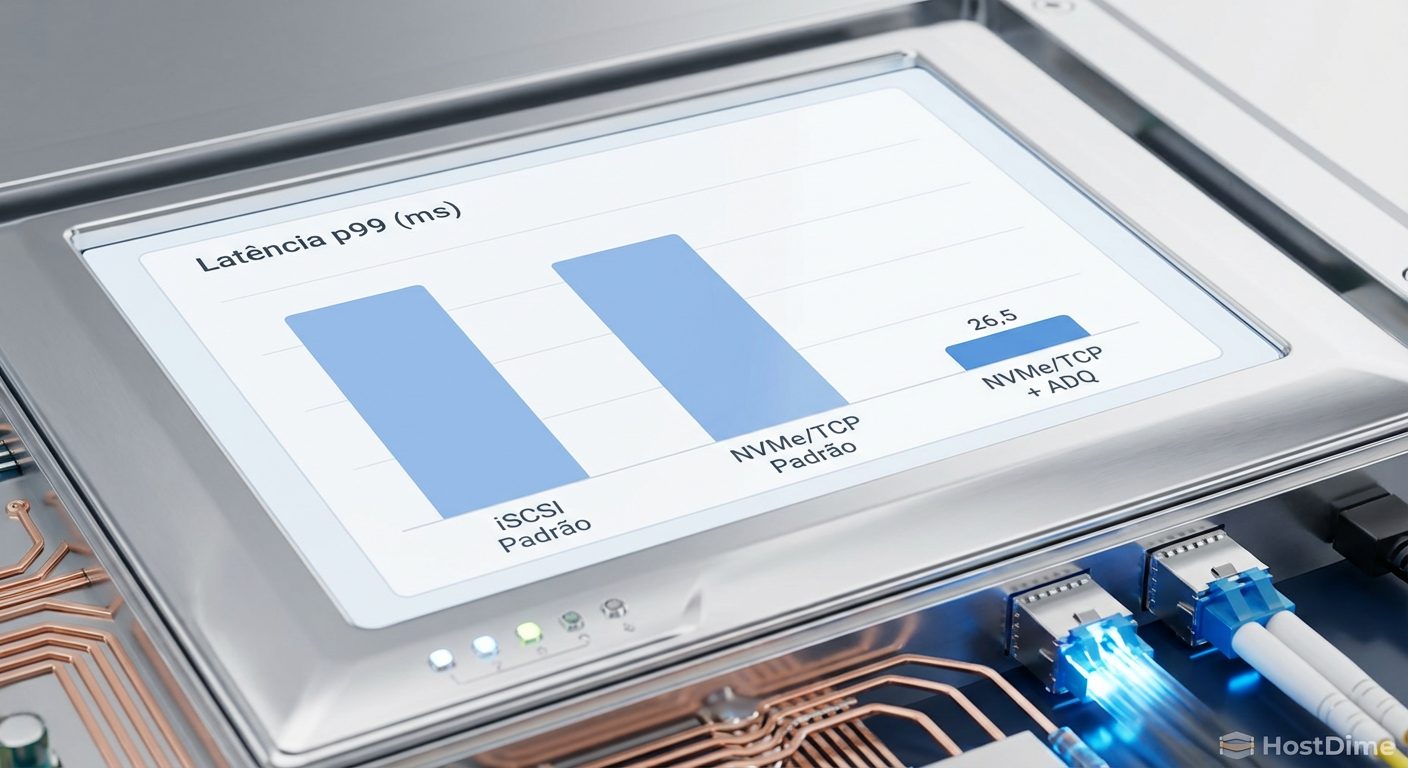 Fig. 3: Impacto da otimização de filas na latência de cauda (p99) em cargas transacionais.
Fig. 3: Impacto da otimização de filas na latência de cauda (p99) em cargas transacionais.
A consistência do NVMe/TCP otimizado é o que permite escalar IOPS. Você pode empurrar 500k, 1M de IOPS e a latência se mantém estável, enquanto no iSCSI ou TCP padrão, a latência dispara exponencialmente após certo ponto de saturação da CPU.
Perguntas Frequentes
1. Preciso de switches especiais para NVMe/TCP? Não. Ao contrário do RoCE (RDMA over Converged Ethernet), o NVMe/TCP funciona em qualquer switch Ethernet padrão. No entanto, switches com buffers profundos (Deep Buffer) são altamente recomendados para evitar retransmissões TCP em momentos de micro-bursts.
2. O NVMe/TCP substitui o Fibre Channel? Para novas implementações (Greenfield), sim. O custo por porta do 100/200/400GbE é muito menor que o FC 64G/128G. Para ambientes legados, a migração deve ser avaliada caso a caso. A confiabilidade do FC ainda é o "padrão ouro", mas o gap fechou significativamente.
3. O consumo de CPU não inviabiliza o uso em servidores de banco de dados convergentes? Depende. Se você usar NICs com capacidade de Offload (SmartNICs ou DPUs), parte do processamento TCP é retirado da CPU principal. Sem offload, você deve reservar (designar) núcleos de CPU para lidar com o I/O de rede, subtraindo-os do pool disponível para o banco de dados. É um cálculo de TCO (Total Cost of Ownership).
4. O NVMe/TCP funciona em VMware/vSphere? Sim, o suporte nativo foi introduzido no vSphere 7.0 Update 3. É essencial configurar o adaptador de software NVMe corretamente e garantir que a infraestrutura física de rede suporte Jumbo Frames (MTU 9000) de ponta a ponta para eficiência máxima.
O futuro é a desagregação
Não trate o NVMe/TCP como apenas "um cabo mais rápido". Ele é a fundação para a desagregação completa do data center. Estamos caminhando para um modelo onde a computação e o armazenamento são escalados de forma totalmente independente, unidos por um tecido Ethernet de alta performance.
Minha recomendação direta é comece a testar NVMe/TCP em ambientes de homologação hoje, mas foque obsessivamente na configuração da pilha de rede do sistema operacional. Comprar Flash rápido e ligá-lo em uma rede mal configurada é a maneira mais cara de obter performance medíocre. O hardware não resolve problemas de configuração de software; ele apenas os executa mais rápido.
Referências & Leitura Complementar
NVM Express Base Specification 2.0: Detalhes sobre a implementação do transporte TCP e filas de comando.
Intel Ethernet 800 Series Datasheet: Especificações técnicas sobre a tecnologia ADQ (Application Device Queues).
RFC 793 (Transmission Control Protocol): A base fundamental, essencial para entender janelas de congestionamento e retransmissão.
VMware vSphere Storage Guide (NVMe over TCP): Documentação técnica sobre a implementação de adaptadores NVMe-oF em ambientes virtualizados.

Roberto Lemos
Arquiteto de Workloads
"Projeto infraestrutura onde o perfil de I/O dita as regras. Sei que a latência do acesso aleatório de um banco difere da vazão sequencial de vídeos. Mapeio o hardware exato para cada aplicação."