NVMe ZNS na prática: como o bypass da FTL elimina a amplificação de escrita no kernel Linux

Descubra como o padrão NVMe Zoned Namespaces (ZNS) transfere o controle da FTL para o host, zerando a amplificação de escrita e estabilizando a latência de cauda.
Você ajusta o governador da CPU, otimiza a afinidade de interrupções no kernel Linux, implementa io_uring para zerar o overhead de syscalls e, ainda assim, seu banco de dados sofre com picos inexplicáveis de latência no percentil 99.9 (p99.9). O monitoramento mostra a CPU ociosa esperando I/O. O culpado não está no seu código. O culpado é um micro-sistema operacional rodando escondido dentro do seu SSD NVMe, tomando decisões de alocação de blocos sem o seu consentimento.
A arquitetura tradicional de armazenamento em estado sólido trata o disco como um array linear de blocos lógicos, uma abstração herdada dos discos magnéticos (HDDs). Para manter essa ilusão, os SSDs utilizam uma camada de software interna pesada que consome recursos preciosos e gera imprevisibilidade. É aqui que a especificação ZNS (Zoned Namespaces) entra para devolver o controle da física do disco ao sistema operacional.
Resumo em 30 segundos
- SSDs tradicionais usam a FTL (Flash Translation Layer) para mascarar a complexidade da memória NAND, gerando Garbage Collection imprevisível e alta latência de cauda.
- O padrão NVMe ZNS elimina a FTL de mapeamento, dividindo o disco em zonas de gravação sequencial gerenciadas diretamente pelo host (kernel Linux).
- Ao transferir a inteligência de alocação para o sistema de arquivos ou banco de dados, o ZNS reduz o Write Amplification Factor (WAF) para 1.0, maximizando a vida útil do hardware e estabilizando a latência.
A caixa preta da FTL e o colapso da latência de cauda
A memória flash NAND tem uma limitação física fundamental: você não pode sobrescrever um dado diretamente. Para alterar um bit, é necessário apagar um bloco inteiro de células antes de gravar a nova informação. Para esconder essa limitação do sistema operacional, os SSDs implementam a FTL (Flash Translation Layer).
A FTL mapeia os Logical Block Addresses (LBAs) enviados pelo kernel para os Physical Block Addresses (PBAs) reais nos chips NAND. Quando você atualiza um arquivo, a FTL grava o novo dado em uma página limpa e marca a página antiga como inválida. Eventualmente, o disco fica cheio de "buracos" de dados inválidos.
Para liberar espaço, o controlador do SSD aciona o Garbage Collection (GC). Ele lê blocos parcialmente válidos, move os dados bons para novos blocos e apaga os blocos antigos. Se uma operação de leitura crítica do seu banco de dados chegar exatamente no momento em que o controlador está ocupado movendo gigabytes de dados internamente, sua latência de leitura salta de 80 microssegundos para 5 milissegundos. Esse é o colapso da latência de cauda.
 Figura: Comparativo arquitetural entre o gargalo da FTL tradicional e o fluxo direto do NVMe ZNS.
Figura: Comparativo arquitetural entre o gargalo da FTL tradicional e o fluxo direto do NVMe ZNS.
⚠️ Perigo: O Garbage Collection interno gera o Write Amplification Factor (WAF). Se o kernel envia 1 GB de dados, mas a FTL precisa mover outros 2 GB internamente para acomodar a gravação, seu WAF é 3.0. Isso destrói a vida útil (TBW) do seu SSD corporativo três vezes mais rápido do que o necessário.
O custo computacional do over-provisioning e do TRIM
Para mitigar o impacto do Garbage Collection, a indústria adotou soluções de contorno que custam caro. A principal delas é o over-provisioning. Fabricantes reservam fisicamente de 7% a 28% da capacidade total do NAND apenas para dar espaço de manobra à FTL. Você paga por um SSD de 3.2 TB, mas fisicamente ele possui 4 TB. É um desperdício massivo de silício em escala de data center.
Além disso, o kernel Linux precisa enviar comandos TRIM (ou Deallocate, no protocolo NVMe) constantemente para avisar a FTL quais LBAs não contêm mais dados úteis. O envio massivo de comandos TRIM consome largura de banda do barramento PCIe, gera interrupções de hardware e gasta ciclos de CPU apenas para manter a FTL informada sobre o estado do sistema de arquivos.
Zoned Namespaces e a transferência do mapeamento para o host
A especificação ZNS, padronizada pelo consórcio NVM Express, resolve o problema na raiz. Em vez de fingir que o SSD é um disco magnético que aceita gravações aleatórias em qualquer setor, o ZNS expõe a verdadeira natureza da memória flash para o host.
O espaço de armazenamento é dividido em Zonas (geralmente de 256 MB a 2 GB). A regra de ouro do ZNS é estrita: dentro de uma zona, as gravações devem ser estritamente sequenciais (append-only). Não há sobrescrita in-place. Quando uma zona enche, ela deve ser explicitamente resetada pelo host antes de ser reutilizada.
Ao impor essa restrição, o SSD não precisa mais de uma FTL complexa para mapeamento de blocos ou Garbage Collection. O disco se torna um dispositivo burro, rápido e previsível. A responsabilidade de gerenciar o ciclo de vida dos dados, agrupar gravações e limpar zonas antigas é transferida para o kernel Linux ou para a aplicação em user-space.
Comparativo de arquiteturas de armazenamento
| Característica | NVMe Block-Based (Tradicional) | NVMe ZNS (Zoned Namespaces) |
|---|---|---|
| Gerenciamento de Mapeamento | Interno (FTL no hardware) | Externo (Host / Kernel Linux) |
| Garbage Collection | Autônomo e imprevisível | Controlado pelo Host (Previsível) |
| Write Amplification (WAF) | Variável (frequentemente > 2.0) | Exatamente 1.0 (Sem amplificação) |
| Over-provisioning Necessário | Alto (10% a 28% da capacidade) | Quase zero (Apenas para bad blocks) |
| Complexidade de Software | Baixa (Plug and play com Ext4/XFS) | Alta (Requer F2FS, Btrfs ou ZenFS) |
 Figura: Estrutura de zonas no ZNS: o Write Pointer garante a gravação estritamente sequencial.
Figura: Estrutura de zonas no ZNS: o Write Pointer garante a gravação estritamente sequencial.
Rastreando a queda do WAF para 1.0 no subsistema de blocos
Como engenheiros de performance, não confiamos em especificações teóricas. Precisamos medir. Quando você espeta um drive ZNS em um servidor Linux moderno e utiliza ferramentas de tracing no subsistema de blocos, a diferença de comportamento é brutal.
Se utilizarmos o fio (Flexible I/O Tester) para gerar uma carga de trabalho mista e monitorarmos a atividade com o blktrace, veremos o impacto real. Em um SSD tradicional, o blktrace mostrará as submissões de I/O do kernel, mas a latência de completamento (completion latency) no anel de resposta do NVMe terá uma variância enorme devido ao GC interno.
No ZNS, como o host escreve sequencialmente nas zonas, o disco apenas recebe os dados e os descarrega diretamente nas páginas NAND. Um byte enviado pelo kernel via syscall pwritev2 ou io_uring resulta em exatamente um byte gravado no silício. O WAF cai para 1.0 matemático. A latência de cauda despenca e se torna uma linha reta no gráfico, pois não há processos em background roubando IOPS do controlador.
💡 Dica Pro: No Linux, você pode inspecionar a topologia de zonas de um disco ZNS utilizando o utilitário
nvme-clie ferramentas de bloco. O comandoblkzone report /dev/nvme0n1listará todas as zonas, seus tamanhos, capacidades e a posição exata do Write Pointer (WP) em tempo real.
Sistemas de arquivos e bancos de dados no mundo ZNS
Você não pode simplesmente formatar um namespace ZNS com Ext4 ou XFS. Esses sistemas de arquivos tradicionais assumem que podem sobrescrever metadados no mesmo setor repetidas vezes, o que viola a regra de gravação sequencial do ZNS.
Para utilizar ZNS no Linux, precisamos de softwares zone-aware. O F2FS (Flash-Friendly File System) e o Btrfs possuem suporte nativo para dispositivos de bloco zonados. Eles estruturam suas gravações em formato de log (Log-structured), o que se alinha perfeitamente com a exigência de append-only das zonas. O próprio sistema de arquivos assume o papel de fazer o Garbage Collection, mas agora ele faz isso de forma inteligente, utilizando ciclos de CPU ociosos e ciente da prioridade dos dados da aplicação.
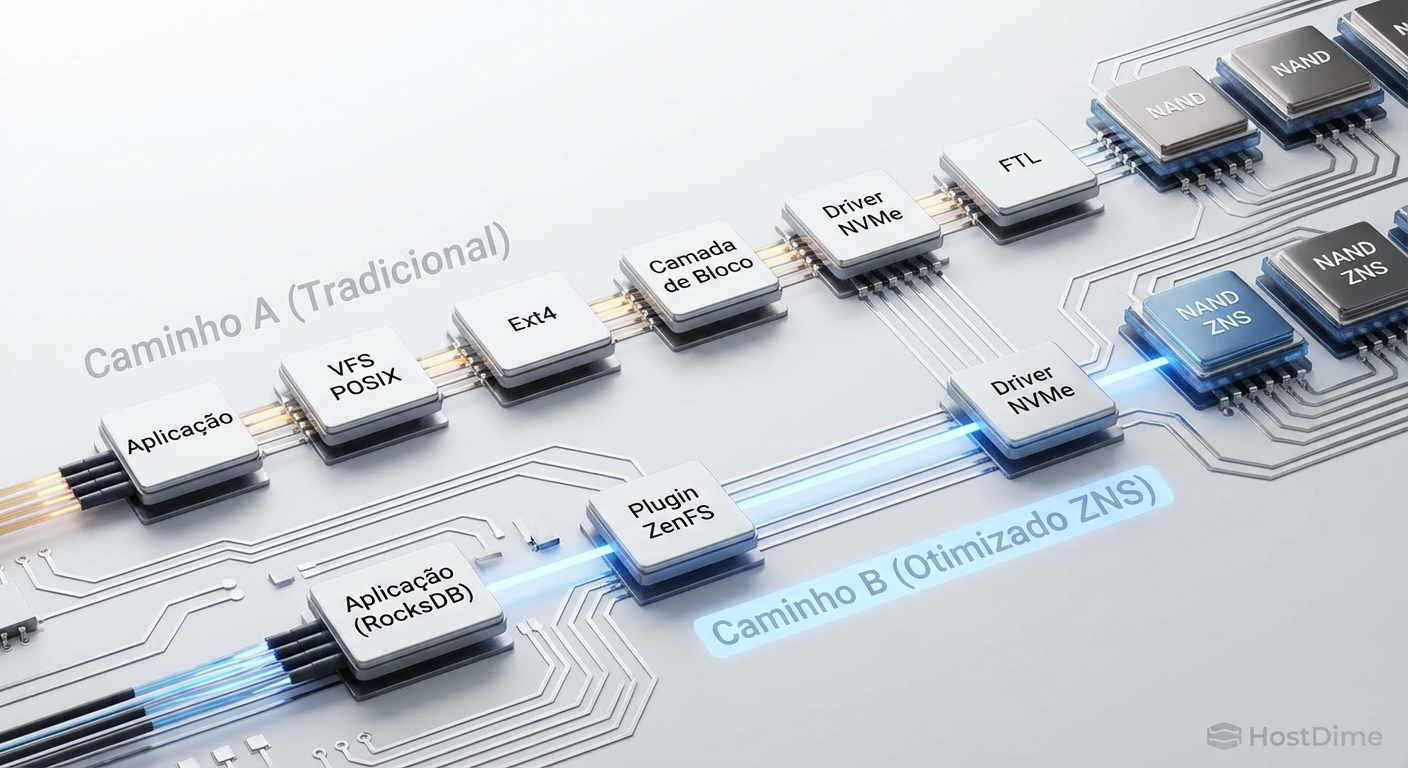 Figura: Bypass da stack de armazenamento: RocksDB com ZenFS comunicando-se diretamente com o NVMe ZNS.
Figura: Bypass da stack de armazenamento: RocksDB com ZenFS comunicando-se diretamente com o NVMe ZNS.
A verdadeira revolução do ZNS, no entanto, ocorre quando fazemos o bypass completo do sistema de arquivos (POSIX). Bancos de dados baseados em LSM-Trees (Log-Structured Merge-Trees), como o RocksDB, já gravam dados sequencialmente em arquivos SSTable. Utilizando plugins como o ZenFS, o RocksDB pode alocar zonas do NVMe diretamente via interface de caracteres do kernel.
Nesse cenário, eliminamos o overhead do VFS (Virtual File System), eliminamos o page cache redundante e eliminamos a FTL. O banco de dados fala quase diretamente com o silício. O resultado é um ganho massivo de throughput de gravação e uma latência de leitura imune a picos de background.
O veredito arquitetural para o data center
A abstração de blocos lógicos foi útil durante a transição dos discos magnéticos para o estado sólido, mas seu custo computacional tornou-se insustentável para cargas de trabalho intensivas. Manter uma FTL complexa em cada drive de um storage array significa desperdiçar terabytes de capacidade em over-provisioning e queimar ciclos de CPU lidando com a imprevisibilidade do hardware.
A adoção do NVMe ZNS representa a maturidade da engenharia de storage. Ao aceitar a assimetria da memória flash e transferir o gerenciamento de zonas para o host, eliminamos a amplificação de escrita e estabilizamos a latência de cauda. Para provedores de nuvem, datacenters corporativos e arquiteturas de banco de dados de alta performance, o ZNS não é apenas uma otimização de driver. É a fundação necessária para extrair cada IOPS e cada milissegundo de performance do silício que você comprou.
Referências & Leitura Complementar
NVM Express Base Specification 2.0: Seção sobre Zoned Namespaces Command Set.
SNIA (Storage Networking Industry Association): Zoned Storage Technical Work Group (TWG) Architecture.
Kernel.org: Documentação oficial do subsistema de blocos do Linux para Zoned Block Devices (ZBD).
Western Digital Zoned Storage: Especificações técnicas e whitepapers sobre a implementação do ZenFS no RocksDB.
O que é Write Amplification Factor (WAF) em SSDs NVMe?
É a proporção matemática entre os dados gravados fisicamente nas células de memória NAND e os dados lógicos enviados pelo sistema operacional. Um WAF alto (ex: 3.0 ou mais) consome ciclos de gravação desnecessários, reduz drasticamente a vida útil do disco e gera picos imprevisíveis de latência devido ao Garbage Collection interno roubando IOPS da sua aplicação.Como o NVMe ZNS difere de um SSD NVMe tradicional?
Em um SSD NVMe block-based tradicional, uma camada de software interna chamada FTL (Flash Translation Layer) gerencia o mapeamento de blocos lógicos para físicos e executa o Garbage Collection de forma autônoma, agindo como uma caixa preta. No padrão ZNS, o disco é dividido em zonas de gravação estritamente sequenciais e o sistema operacional (host) assume o controle direto do posicionamento dos dados, eliminando a FTL pesada do hardware e acabando com a imprevisibilidade.Quais sistemas de arquivos do Linux suportam NVMe ZNS nativamente?
No ecossistema atual do kernel Linux, o F2FS (Flash-Friendly File System) e o Btrfs possuem suporte nativo e maduro para dispositivos block-zoned, pois utilizam arquiteturas log-structured. Além disso, bancos de dados de alta performance como o RocksDB podem fazer bypass completo do sistema de arquivos POSIX utilizando plugins como o ZenFS para gravar diretamente nas zonas do NVMe, zerando o overhead de software.
André Linhares
Engenheiro de Performance (Kernel/IO)
"Vivo no kernel space caçando latência com eBPF. Para mim, context switches excessivos são inimigos pessoais e cada ciclo de CPU desperdiçado é uma ofensa técnica."