O custo oculto da paridade: quando o storage de leitura mata a performance de escrita

Uma análise técnica para DBAs sobre por que RAID 5 e SSDs QLC destroem a latência de bancos de dados transacionais e como arquitetar a solução correta.
O maior erro que vejo em arquiteturas de dados modernas não é a escolha do banco de dados, mas onde ele é colocado para "dormir". Existe uma crença perigosa de que um SSD é apenas um disco rígido mais rápido e que qualquer arranjo RAID serve, desde que proteja contra falhas. Se você trata seu subsistema de storage como um repositório de arquivos genérico, você já condenou a performance da sua aplicação antes mesmo de executar o primeiro INSERT.
Um banco de dados não é um arquivo de vídeo. Ele não lê sequencialmente do início ao fim na maior parte do tempo, e certamente não escreve de forma educada. Bancos de dados são bestas de acesso aleatório que exigem garantias de durabilidade física a cada milissegundo. Quando você ignora a física do armazenamento em favor de "custo por terabyte" ou configurações padrão de paridade, você introduz uma latência oculta que nenhuma otimização de query ou aumento de vCPU conseguirá resolver.
Resumo em 30 segundos
- A penalidade da paridade: Em RAID 5 ou 6, uma única operação de escrita lógica obriga o controlador a ler os dados antigos e a paridade antiga antes de escrever os novos. Isso transforma 1 IOPS em 4 ou 6 operações físicas (Read-Modify-Write).
- O gargalo do WAL: Logs de transação (Write Ahead Logs) exigem latência de escrita absoluta. Caches de leitura não ajudam aqui; se o disco engasga no
fsync, o banco inteiro trava.- A mentira do QLC: SSDs de alta densidade dependem de caches SLC minúsculos. Quando esse cache enche durante uma carga de trabalho pesada, a performance cai para níveis de HDD mecânico, criando latência de cauda desastrosa.
O silêncio enganoso da latência de commit
A métrica de vaidade favorita dos vendedores de storage é o throughput (MB/s). Eles adoram mostrar gráficos de leituras sequenciais saturando links de 10GbE ou 25GbE. Para um DBA, isso é irrelevante. O que importa é a latência de commit.
Quando uma aplicação envia um COMMIT, o banco de dados (seja PostgreSQL, MySQL ou SQL Server) não pode confirmar o sucesso até que os dados estejam fisicamente persistidos no Write Ahead Log (WAL) ou Redo Log. Essa é a chamada de sistema fsync() ou fdatasync(). Nesse momento, o banco para e espera o disco.
Se o seu storage tem uma latência média de 0.5ms, mas sofre picos de 20ms devido à contenção de escrita ou overhead de paridade, sua aplicação vai sentir "travadinhas" inexplicáveis. O usuário percebe isso como lentidão na interface, mas o monitoramento de CPU do servidor de banco estará baixo. O gargalo é puramente a física do disco respondendo "sim, eu gravei".
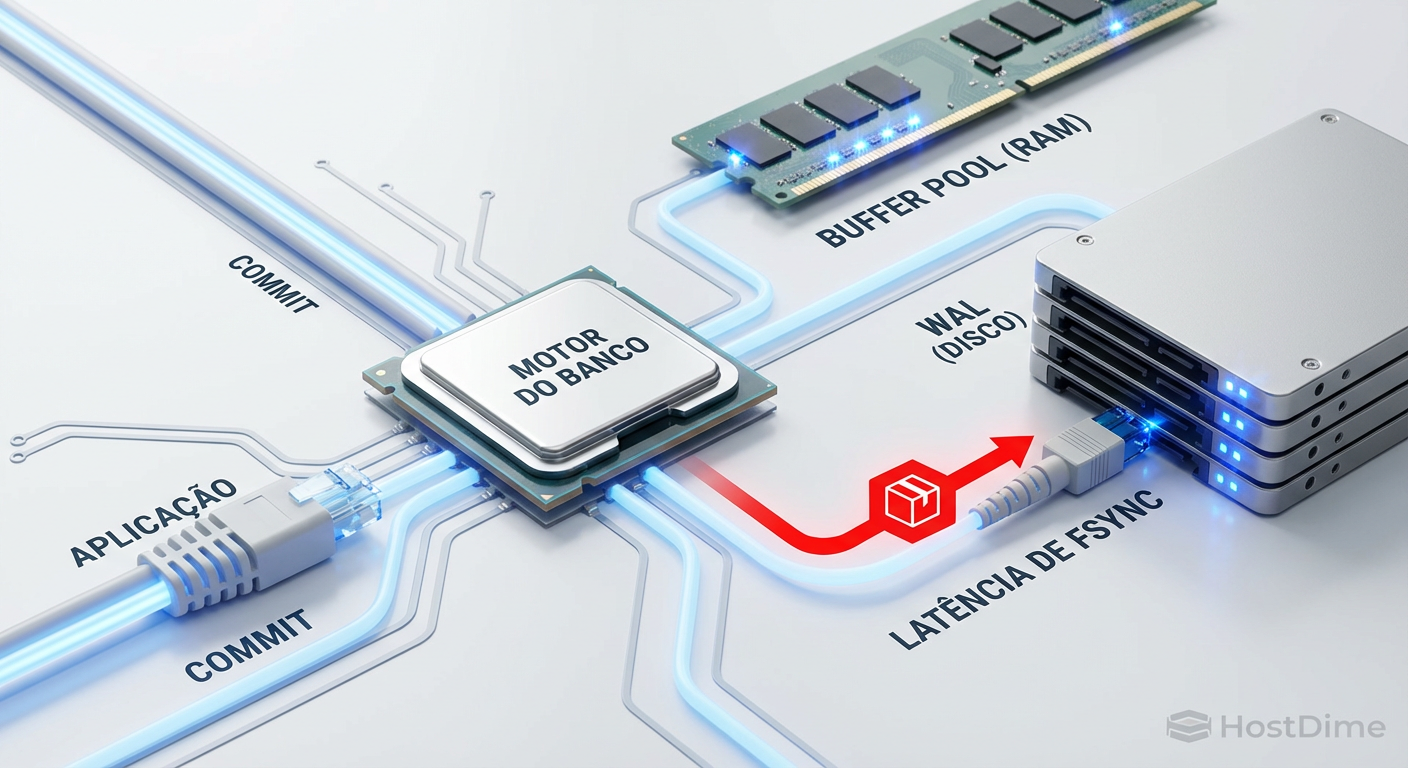 Figura: O gargalo invisível: o banco de dados não libera a transação até que o storage confirme a gravação física no log.
Figura: O gargalo invisível: o banco de dados não libera a transação até que o storage confirme a gravação física no log.
A matemática cruel do ciclo read-modify-write no RAID 5
Aqui é onde a economia de custos destrói a performance. RAID 5 e RAID 6 são excelentes para servidores de arquivos, backups e data lakes onde a leitura predomina (WORM - Write Once, Read Many). Para um banco de dados transacional (OLTP), eles são veneno.
Em um arranjo RAID 10 (espelhamento + striping), uma escrita lógica resulta em duas escritas físicas. Simples, direto e rápido.
Em um RAID 5, a história é tragicamente diferente. Como a paridade é distribuída, você não pode simplesmente sobrescrever um bloco. O controlador precisa garantir que a paridade continue válida para o novo dado. O processo, conhecido como Read-Modify-Write (RMW), segue esta sequência para uma única escrita aleatória (comum em updates de DB):
Ler o bloco de dados antigo do disco.
Ler o bloco de paridade antigo do disco.
Calcular a nova paridade (XOR entre dado novo, dado antigo e paridade antiga).
Escrever o novo dado.
Escrever a nova paridade.
💡 Dica Pro: Em termos de IOPS, isso é conhecido como "Write Penalty". No RAID 5, a penalidade é 4 (2 leituras + 2 escritas). No RAID 6, a penalidade sobe para 6. Se seu banco precisa de 2.000 IOPS de escrita, seu backend de discos em RAID 5 precisa entregar 8.000 IOPS físicos reais.
Isso satura as filas do controlador e aumenta a latência drasticamente. Em cargas de trabalho mistas, onde o banco está tentando ler páginas de dados e escrever logs simultaneamente, o RMW canibaliza a largura de banda disponível para as leituras, matando a performance geral.
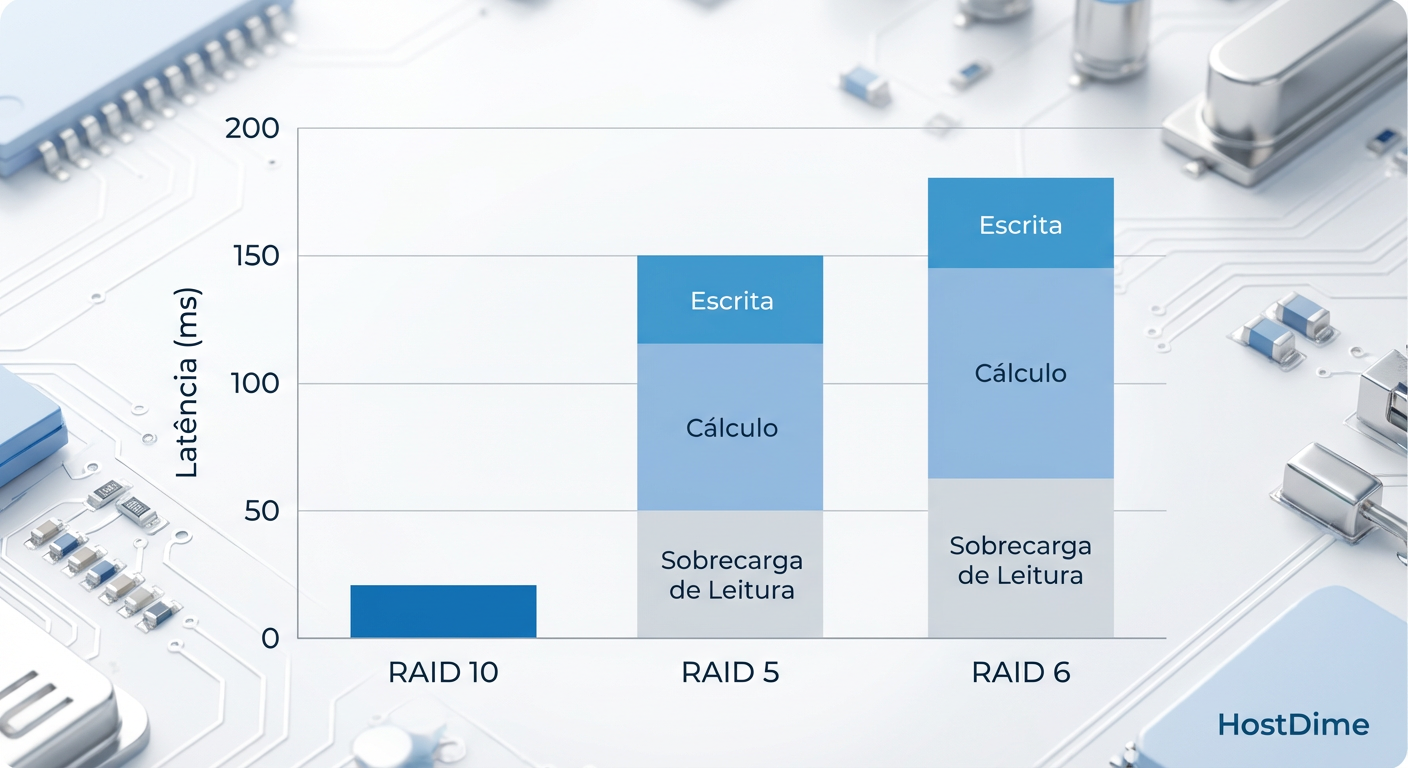 Figura: A penalidade de escrita: visualizando o custo adicional de I/O imposto pelos cálculos de paridade em workloads aleatórios.
Figura: A penalidade de escrita: visualizando o custo adicional de I/O imposto pelos cálculos de paridade em workloads aleatórios.
O abismo do cache SLC e a saturação em drives QLC
A indústria de storage tem empurrado agressivamente a tecnologia NAND QLC (Quad-Level Cell) para o data center, prometendo densidade e custo baixo. Para mascarar a performance nativa medíocre do QLC (que é lento para escrever porque precisa gerenciar 16 estados de voltagem por célula), os fabricantes usam uma porção do drive como cache pSLC (pseudo-SLC).
O pSLC é rápido. Ele aceita dados na velocidade máxima da interface (NVMe/SAS). O problema surge quando o banco de dados decide fazer um bulk load, uma reindexação ou simplesmente opera em alta carga constante.
Quando o cache pSLC enche, o drive entra em um estado de "folding". Ele precisa, simultaneamente:
Escrever os novos dados que chegam na velocidade lenta da NAND QLC nativa.
Mover os dados do cache pSLC para a área QLC para liberar espaço.
Nesse momento, a performance de escrita cai de um penhasco. Um drive que prometia 2.000 MB/s pode cair repentinamente para 80 MB/s ou menos — pior que um HDD mecânico de 7200 RPM. Para o banco de dados, isso se manifesta como um aumento súbito no w_await (tempo de espera de escrita), travando todas as sessões ativas.
⚠️ Perigo: Nunca utilize SSDs QLC para volumes de WAL ou TempDB sem verificar explicitamente o gráfico de "Sustained Write Performance" na folha de dados. O número de "Burst Performance" é irrelevante para bancos de dados em produção.
Por que adicionar cache de leitura ignora a física do WAL
Frequentemente vejo administradores tentando resolver problemas de lentidão de escrita adicionando mais cache de leitura (L2ARC no ZFS, bcache ou simplesmente mais RAM para o Buffer Pool). Isso é um diagnóstico fundamentalmente errado.
O Write Ahead Log (WAL) é um fluxo de escrita sequencial, append-only. O banco de dados raramente lê o WAL, exceto durante a recuperação de falhas ou replicação. Otimizar a leitura não ajuda em nada a velocidade com que o disco consegue persistir esses bits magnéticos ou células flash.
Além disso, caches de escrita em controladores RAID ou SSDs (DRAM cache on-disk) só são seguros se houver proteção contra perda de energia (PLP - Power Loss Protection). Sem capacitores dedicados no drive ou bateria na controladora (BBU), desativar o fsync ou confiar no cache volátil é jogar roleta russa com a integridade dos seus dados. Se a energia cair, a transação confirmada desaparece, e seu banco corrompe.
Arquitetura de isolamento: separando logs e dados em RAID 10
A solução para mitigar o custo da paridade e a contenção de recursos não é mágica, é isolamento físico ou lógico de workloads. O padrão de acesso aos arquivos de dados (.mdf, /base) é aleatório. O padrão de acesso aos logs (.ldf, /pg_wal) é sequencial. Misturá-los no mesmo array de discos é ineficiente.
A arquitetura de referência para alta performance deve seguir esta hierarquia:
Logs de Transação (WAL/Redo): Devem residir no storage mais rápido e com menor latência de escrita possível. Idealmente, um par de SSDs NVMe Enterprise (Endurance DWPD > 3) em RAID 1. Isso garante redundância sem a penalidade de paridade do RAID 5. O acesso sequencial aqui não deve competir com as buscas aleatórias das queries.
Arquivos de Dados: Podem residir em um pool maior. RAID 10 é o padrão ouro. Se o orçamento for extremamente apertado e a carga de leitura for 90%+, RAID 5 com SSDs Enterprise pode ser tolerado, mas esteja ciente do risco de reconstrução (rebuild) lento e impacto na performance durante falhas.
TempDB / Espaço Temporário: Frequentemente esquecido, mas crítico. O banco usa isso para sorts e hashes que não cabem na RAM. Requer alta IOPS de escrita e leitura aleatória. Nunca coloque isso em discos mecânicos ou arrays QLC saturados. RAID 0 é aceitável aqui se a persistência não for necessária após reboot, mas RAID 10 é mais seguro para disponibilidade.
 Figura: Segregação de workload: a única maneira de garantir que a latência de log não seja afetada por scans de tabelas gigantes.
Figura: Segregação de workload: a única maneira de garantir que a latência de log não seja afetada por scans de tabelas gigantes.
Validação forense: interpretando w_await e filas de disco no Linux
Não confie na minha palavra; confie no kernel do Linux. Quando você suspeitar que o storage está matando sua performance, esqueça o top e vá direto para o iostat -x 1.
Existem três colunas que contam a história real do sofrimento do seu banco de dados:
w_await (Write Await): O tempo médio (em milissegundos) que uma solicitação de escrita espera para ser servida. Em um sistema saudável com SSDs, isso deve ser consistentemente abaixo de 1-2ms. Se você ver valores de 10ms, 50ms ou picos de 100ms em um volume RAID 5, você está vendo a penalidade de RMW acontecendo ao vivo.
avgqu-sz (Average Queue Size): O tamanho médio da fila de solicitações. Se este número for consistentemente maior que 1 (ou maior que o número de dispositivos físicos no array), significa que as solicitações estão chegando mais rápido do que o storage consegue processar. É o sintoma clássico de saturação.
%util: Embora útil, cuidado. Em arrays RAID ou SSDs modernos, 100% de utilização não significa necessariamente que o disco está morto, pois eles têm paralelismo interno. Mas 100% de utilização combinado com alto
w_awaité a confirmação de gargalo.
💡 Dica Pro: Use o comando
iostat -x -k -p [device] 2durante um pico de carga. Observe se ow_awaitdispara enquanto or_await(leitura) permanece baixo. Se isso acontecer, seu gargalo é especificamente a capacidade de absorção de escrita (write endurance/cache exhaustion) ou a penalidade de paridade.
O veredito da infraestrutura
A tentação de economizar em storage é grande. Discos são caros e a paridade RAID 5/6 parece oferecer um "almoço grátis" de capacidade extra. Mas em bancos de dados, não existe almoço grátis, apenas dívida técnica com juros compostos na forma de latência.
Se você está arquitetando uma solução de banco de dados crítica, pare de tratar IOPS como uma commodity genérica. Entenda que uma escrita de banco de dados é uma operação cirúrgica que exige confirmação imediata. Mova seus logs para RAID 1 ou 10, evite QLC para cargas transacionais e monitore a latência de escrita como se a vida da sua aplicação dependesse disso — porque depende.
Referências & Leitura Complementar
SNIA (Storage Networking Industry Association): "Solid State Storage Performance Test Specification (PTS)" — Padrões para medição real de performance em estado estável vs. estado fresco (FOB).
PostgreSQL Documentation: "Reliability and the Write-Ahead Log" — Explicação detalhada sobre a dependência do
fsynce a física da durabilidade dos dados.JEDEC JESD218: "Solid-State Drive (SSD) Requirements and Endurance Test Method" — A norma técnica que define como a vida útil e a retenção de dados dos SSDs (TBW/DWPD) são calculadas.
Linux Kernel Documentation: "I/O statistics fields" — Definições técnicas das métricas do
iostat(kernel 2.6+).

Roberto Lemos
Arquiteto de Workloads
"Projeto infraestrutura onde o perfil de I/O dita as regras. Sei que a latência do acesso aleatório de um banco difere da vazão sequencial de vídeos. Mapeio o hardware exato para cada aplicação."