O fim do abismo de latência: Como o CXL redefine a hierarquia de memória

Análise técnica para arquitetos de workload: como o protocolo CXL elimina o gargalo entre DRAM e NVMe, transformando o barramento PCIe em extensão de memória coerente.
Se você gerencia bancos de dados de alta performance ou clusters de virtualização densos, conhece a dor física de observar a métrica de IO Wait. Durante décadas, vivemos reféns de uma lacuna brutal na arquitetura de computadores: o abismo entre a memória DRAM (rápida, volátil e cara) e o armazenamento persistente (lento, barato e massivo).
Não importa quão rápido seja o seu array All-Flash NVMe; para a CPU, buscar dados em um SSD é como viajar para outro continente. O protocolo CXL (Compute Express Link) chegou para destruir essa barreira, não tornando o disco mais rápido, mas transformando a interface PCIe em um canal de memória legítimo.
Resumo em 30 segundos
- O Problema: Existe um "vazio" de performance entre a RAM (nanossegundos) e o SSD NVMe (microssegundos). O NVMe, por mais rápido que seja, ainda exige interrupções e overhead de I/O.
- A Solução: O CXL permite conectar memória DRAM via slots PCIe (como se fossem discos), mantendo a coerência de cache com a CPU.
- O Impacto: Servidores podem ter Terabytes de RAM expandida com custo menor e latência semelhante a um acesso NUMA, eliminando a necessidade de swap em disco.
A física da latência: Por que o NVMe não é RAM
Para entender a revolução do CXL, precisamos ser honestos sobre a física dos semicondutores. Muitos administradores caem na armadilha de marketing de que "SSDs NVMe de classe Storage Class Memory (SCM)" podem substituir a RAM. Isso é tecnicamente incorreto devido à forma como a CPU endereça os dados.
A memória RAM é endereçada por byte. A CPU executa instruções LOAD e STORE diretamente nos endereços de memória. É um acesso síncrono. Já o armazenamento (mesmo o NVMe mais rápido) é endereçado por bloco. Para ler um dado do NVMe, a CPU precisa:
Criar uma solicitação de I/O.
Enviar para a fila do driver NVMe.
Sofrer uma interrupção de contexto.
Aguardar o DMA (Direct Memory Access) copiar o bloco do SSD para a RAM.
Só então ler o dado.
Essa "dança" do I/O custa caro. Enquanto um acesso à DRAM local leva cerca de 80 a 100 nanossegundos, um acesso a um SSD NVMe Enterprise de ponta leva cerca de 80 a 100 microssegundos. A diferença é de três ordens de magnitude.
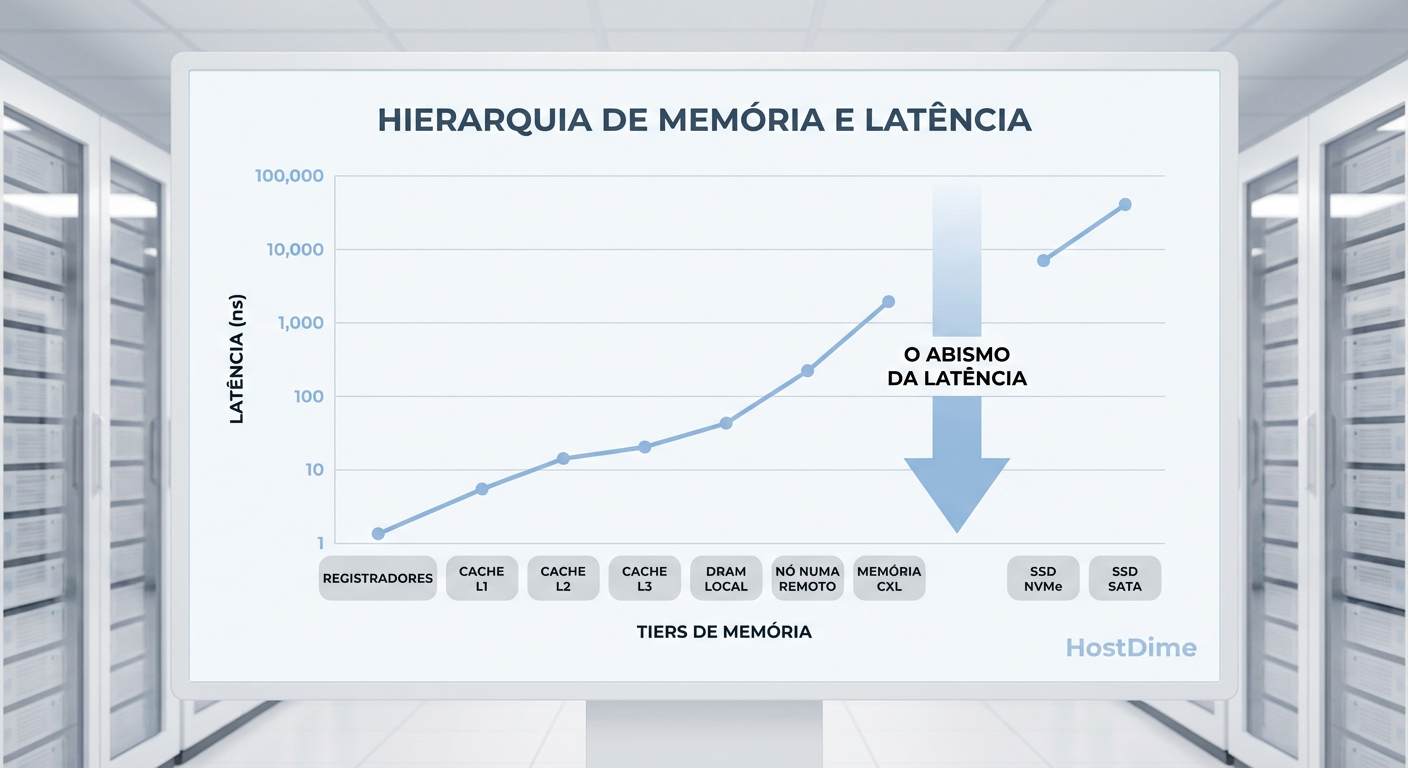 Figura: Gráfico em escala logarítmica ilustrando o "Abismo de Latência" entre as tecnologias de memória (acesso direto) e armazenamento (acesso por bloco).
Figura: Gráfico em escala logarítmica ilustrando o "Abismo de Latência" entre as tecnologias de memória (acesso direto) e armazenamento (acesso por bloco).
💡 Dica Pro: Nunca dimensione o swap do seu banco de dados contando com a velocidade do NVMe. Se o Oracle ou PostgreSQL começar a fazer paging agressivo, a latência de transação vai explodir, não importa se você usa PCIe Gen5. O banco de dados precisa de endereçamento por byte, não por bloco.
O protocolo CXL: Coerência de cache via PCIe
O CXL (Compute Express Link) resolve esse problema desacoplando a memória do slot DIMM físico. Ele utiliza a camada física do PCIe (a partir da geração 5.0), mas fala um protocolo diferente.
Ao conectar um dispositivo CXL, não estamos apenas "espetando" um cartão. Estamos estendendo o mapa de memória do processador. O CXL opera com três sub-protocolos, mas para nós, arquitetos de storage e memória, o CXL.mem é o que importa.
Como funciona o CXL.mem
Diferente do NVMe, onde a CPU fala com um controlador de disco, no CXL.mem a CPU (Host) pode acessar dados na memória do dispositivo (Device) usando instruções de carga/armazenamento diretas. O controlador CXL garante a coerência de cache.
Se uma linha de cache na CPU for modificada, o dispositivo CXL sabe disso. Isso permite que tratemos dispositivos conectados via PCIe como se fossem pentes de memória RAM adicionais, visíveis pelo Sistema Operacional como um nó NUMA (Non-Uniform Memory Access) sem processadores, apenas com memória.
Tabela Comparativa: NVMe vs. CXL (Memória)
| Característica | NVMe (Storage) | CXL (Memory Expander) |
|---|---|---|
| Semântica de Acesso | Leitura/Escrita de Blocos (I/O) | Load/Store (Byte Addressable) |
| Latência Típica | ~80.000 ns (80 µs) | ~170 - 250 ns |
| Visibilidade no OS | Dispositivo de Bloco (/dev/nvme0n1) |
Memória do Sistema (NUMA Node) |
| Persistência | Sim (NAND Flash) | Não (Geralmente DRAM volátil) |
| Overhead de Software | Alto (Stack de I/O, Interrupções) | Zero/Mínimo (Hardware gerenciado) |
Dispositivos Tipo 3 e o fim da "Memória Órfã"
No datacenter moderno, enfrentamos o problema da "memória órfã" (stranded memory). Você compra um servidor com 1TB de RAM para um banco de dados, mas a CPU atinge 100% de uso consumindo apenas 400GB de RAM. Os outros 600GB estão presos naquele chassi, desperdiçados, enquanto o servidor vizinho está sofrendo OOM Kill (Out of Memory) por falta de RAM.
O CXL introduz os Dispositivos Tipo 3 (Expansores de Memória). Eles podem vir em formatos tradicionais de placas PCIe, mas a indústria de storage está convergindo para o uso de formatos EDSFF (Enterprise & Data Center Standard Form Factor), especificamente o E1.S e o E3.S.
Imagine um servidor onde as baias frontais não são apenas para SSDs. Você pode popular metade das baias com SSDs NVMe para armazenamento e a outra metade com módulos E3.S CXL contendo DRAM.
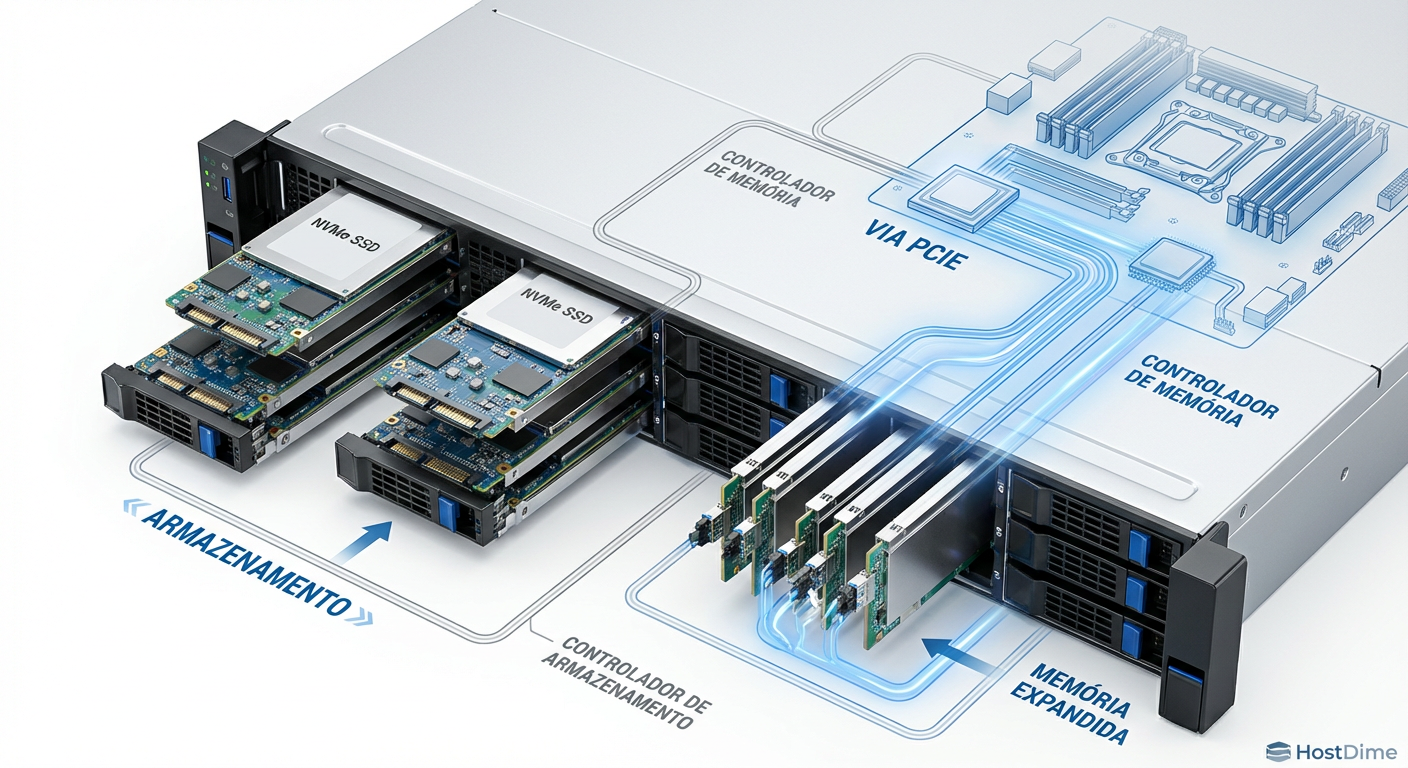 Figura: Diagrama técnico de um chassi de servidor híbrido utilizando baias EDSFF tanto para armazenamento NVMe quanto para expansão de memória via módulos CXL E3.S.
Figura: Diagrama técnico de um chassi de servidor híbrido utilizando baias EDSFF tanto para armazenamento NVMe quanto para expansão de memória via módulos CXL E3.S.
Isso permite um dimensionamento granular. Precisa de mais 512GB de RAM para o SAP HANA? Não precisa abrir o servidor e trocar pentes DIMM (se é que sobraram slots). Basta inserir módulos CXL nas baias frontais ou traseiras.
Tiering de Memória: A nova arquitetura
A introdução do CXL cria uma nova camada na hierarquia. Agora temos:
Near Memory: DRAM conectada diretamente ao soquete da CPU (DDR5 DIMMs). Latência mínima, largura de banda máxima.
Far Memory: DRAM conectada via CXL. Latência ligeiramente maior (semelhante a acessar a memória de outro soquete CPU em um sistema dual-socket), mas capacidade massiva.
O papel do Kernel e do Hypervisor
Para que isso funcione sem degradar a performance, o tiering de memória deve ser inteligente. O Kernel do Linux (e hypervisors como VMware vSphere 8+) está evoluindo para gerenciar páginas de memória dinamicamente.
Páginas Quentes (Hot Pages): Dados acessados frequentemente são movidos ou mantidos na Near Memory (DDR5 local).
Páginas Mornas/Frias (Warm/Cold Pages): Dados que ocupam espaço mas são acessados com menor frequência são migrados transparentemente para a Far Memory (CXL).
⚠️ Perigo: A latência do CXL é baixa, mas a largura de banda é limitada pelas pistas PCIe. Um slot PCIe 5.0 x16 oferece teóricos 64 GB/s (bidirecional), enquanto um canal de memória DDR5 pode superar isso facilmente em conjunto. Cargas de trabalho sensíveis a bandwidth (como HPC puro) devem priorizar DIMMs locais. Cargas sensíveis a capacidade (como In-Memory Databases e Caching) são os candidatos ideais para CXL.
Validação de Performance: O teste do "Salto NUMA"
Ao arquitetar soluções com CXL, a regra de ouro para estimativa de performance é a do "Salto NUMA".
Em um servidor dual-socket tradicional, se a CPU 0 precisa acessar dados que estão na RAM conectada à CPU 1, ela atravessa o link de interconexão (UPI na Intel, Infinity Fabric na AMD). Isso adiciona latência. O CXL se comporta de maneira quase idêntica.
Testes práticos com hardware CXL 1.1/2.0 mostram latências de acesso na casa dos 170ns a 250ns. Comparado aos 80ns da memória local, é mais lento. Porém, comparado aos 80.000ns de um SSD NVMe, é instantâneo.
Para um banco de dados, isso significa que você pode expandir o Buffer Pool para tamanhos antes impossíveis economicamente. Em vez de ler do disco, o banco busca na memória CXL. Mesmo sendo 2x mais lento que a RAM local, ainda é 500x mais rápido que ler do flash.
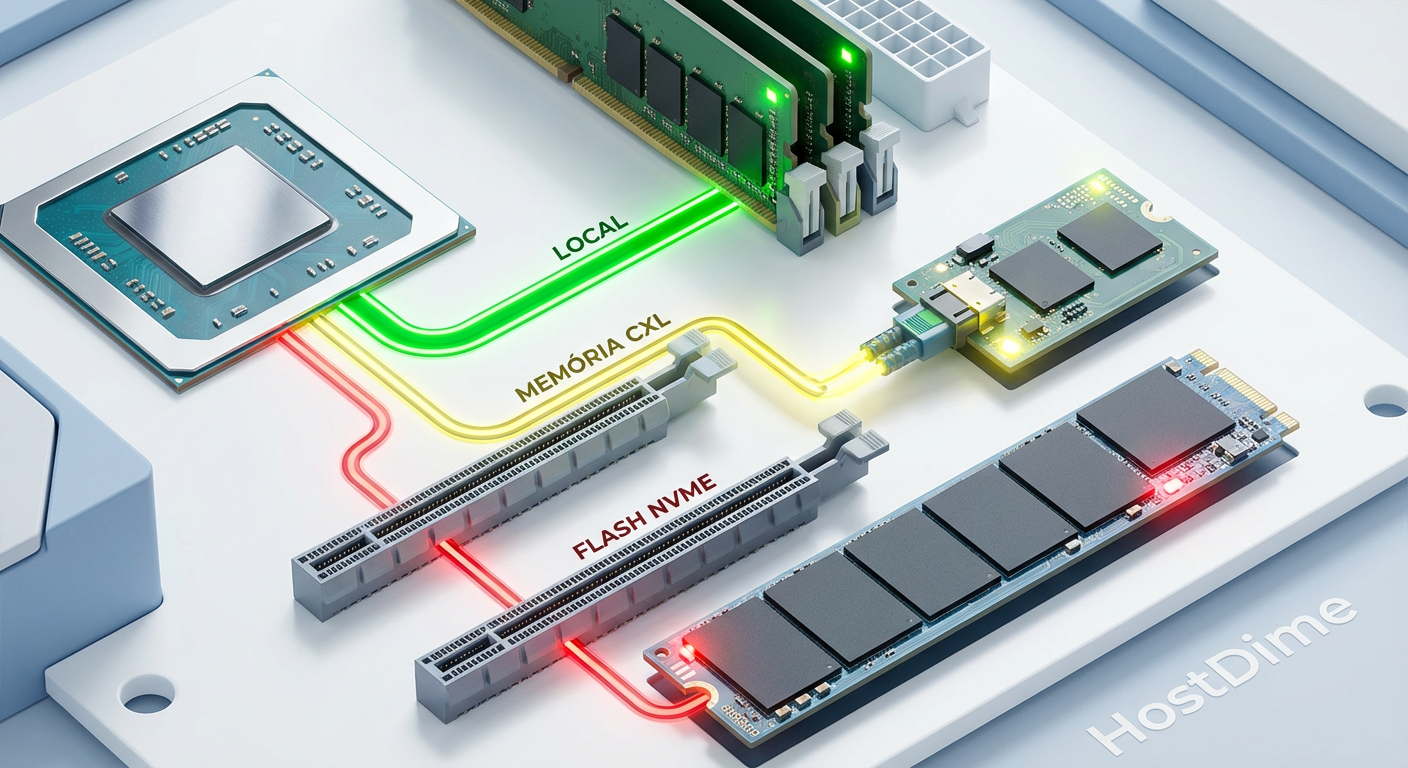 Figura: Comparativo visual dos caminhos de dados: Acesso direto à DRAM (Near Memory), acesso via CXL (Far Memory) e acesso via NVMe (Storage I/O).
Figura: Comparativo visual dos caminhos de dados: Acesso direto à DRAM (Near Memory), acesso via CXL (Far Memory) e acesso via NVMe (Storage I/O).
O futuro: Memory Pooling e Desagregação
O "Santo Graal" do CXL, previsto nas especificações 3.0 e 3.1, é o Memory Pooling. Com switches CXL, poderemos ter um chassi dedicado apenas com memória (um JBOM - Just a Bunch of Memory).
Vários servidores poderão se conectar a esse switch e alocar memória dinamicamente. Se o Servidor A precisa de mais 100GB para um pico de processamento noturno, o switch aloca. Quando o processo termina, a memória volta para o pool e pode ser usada pelo Servidor B. Isso elimina o superdimensionamento vertical e reduz drasticamente o TCO (Custo Total de Propriedade) de infraestrutura de memória.
O veredito do arquiteto
Estamos diante da maior mudança na arquitetura de servidores desde a introdução do x86-64. O CXL não vai substituir a memória DIMM principal tão cedo, nem vai matar o armazenamento NVMe para dados frios. Ele preenche o vácuo.
Para DBAs e Arquitetos de Storage, a recomendação é clara: comece a planejar suas especificações de hardware futuras considerando o suporte a CXL. Em breve, a pergunta "quanto de memória esse servidor suporta?" deixará de ser limitada pelos slots na placa-mãe e passará a ser limitada apenas pelo seu orçamento e slots PCIe disponíveis.
Prepare seus workloads. O conceito de "swap" está prestes a se tornar obsoleto para aplicações de alta performance, substituído por camadas de memória hierárquica reais e coerentes.
Referências & Leitura Complementar
Compute Express Link™ (CXL™) Consortium: CXL 3.1 Specification. Disponível em computeexpresslink.org.
SNIA (Storage Networking Industry Association): Persistent Memory and CXL: The New Hierarchy. Whitepaper técnico.
JEDEC: DDR5 SDRAM Standard (JESD79-5). Contexto sobre larguras de banda de memória local.
PCI-SIG: PCI Express® Base Specification Revision 6.0. Base física para o transporte CXL.
O CXL substitui a memória DRAM tradicional (DIMM)?
Não. O CXL atua como uma camada de "Far Memory". Ele é ligeiramente mais lento que a DRAM local (conectada diretamente ao soquete da CPU), mas oferece capacidade massiva e custo menor, preenchendo o vazio entre a RAM principal e o armazenamento NVMe.Qual a diferença real de latência entre CXL e NVMe?
A diferença é de ordens de magnitude. O acesso via CXL ocorre na casa dos 170-250 nanossegundos (semelhante a um acesso NUMA remoto), enquanto o NVMe mais rápido opera na casa dos 80-100 microssegundos (devido ao overhead de interrupções e pilha de I/O).O que são dispositivos CXL Tipo 3?
São expansores de memória. Eles podem ter o formato de um SSD (como E1.S ou E3.S) ou placa PCIe, mas contêm chips DRAM e um controlador CXL. O sistema operacional os enxerga como memória RAM adicional (sem CPU), não como disco.
Roberto Lemos
Arquiteto de Workloads
"Projeto infraestrutura onde o perfil de I/O dita as regras. Sei que a latência do acesso aleatório de um banco difere da vazão sequencial de vídeos. Mapeio o hardware exato para cada aplicação."