O impacto da compactação do RocksDB na vida útil de SSDs QLC em workloads NoSQL

Descubra como o ajuste fino das estratégias de compactação no RocksDB reduz o write amplification e previne a exaustão prematura de SSDs QLC em bancos de dados.
Um banco de dados não é um arquivo de vídeo. Quando você grava um arquivo de mídia em um disco, o sistema operacional aloca blocos sequenciais e o controlador do SSD agradece. Quando você opera um banco de dados NoSQL de alta performance, o cenário é brutalmente diferente. O motor de armazenamento recebe um fluxo caótico de inserções, atualizações e exclusões. Para lidar com isso, motores modernos utilizam estruturas baseadas em logs, mas essa arquitetura cobra um preço alto na camada física do armazenamento.
O uso de SSDs baseados em memória NAND QLC (Quad-Level Cell) em datacenters explodiu devido ao baixo custo por terabyte. No entanto, colocar um banco de dados NoSQL rodando RocksDB com configurações padrão em cima de um array QLC é uma receita garantida para a destruição prematura do hardware. A compactação agressiva do software colide violentamente com a física sensível das células de alta densidade.
Resumo em 30 segundos
- O motor RocksDB gera uma amplificação de escrita severa devido ao seu processo padrão de compactação em níveis (Leveled Compaction).
- SSDs QLC possuem blocos de apagamento massivos e baixa tolerância a ciclos de gravação, tornando-os altamente vulneráveis a cargas de trabalho não otimizadas.
- Alterar a estratégia para Universal Compaction e alinhar o tamanho das SSTables com a geometria física do SSD pode multiplicar a vida útil do disco em até três vezes.
O esgotamento silencioso do TBW em clusters de alta densidade
A métrica de TBW (Terabytes Written) é o relógio da morte de qualquer SSD. Em ambientes corporativos, administradores de banco de dados frequentemente dimensionam seus clusters NoSQL focando apenas em IOPS e capacidade bruta. O problema surge quando a capacidade é entregue por drives QLC.
A densidade do QLC permite armazenar quatro bits por célula. Isso exige 16 níveis de voltagem distintos para determinar o estado exato dos dados. Essa precisão elétrica degrada a camada de óxido da célula muito mais rápido do que em gerações anteriores. Enquanto um drive corporativo TLC (Triple-Level Cell) pode suportar de 1 a 3 DWPD (Drive Writes Per Day), um drive QLC focado em leitura frequentemente suporta menos de 0.2 DWPD.
O esgotamento do TBW em clusters NoSQL raramente ocorre pela ingestão direta de dados dos usuários. O assassino silencioso atua em segundo plano. É o próprio motor do banco de dados reescrevendo os mesmos dados repetidas vezes para manter a eficiência das consultas de leitura.
A mecânica das LSM-Trees e o castigo dos blocos de apagamento
O RocksDB, motor por trás de bancos como Cassandra (em algumas implementações), CockroachDB e TiKV, utiliza uma arquitetura chamada LSM-Tree (Log-Structured Merge-Tree). Todas as gravações vão primeiro para a memória RAM (MemTable) e para um log sequencial (WAL). Quando a MemTable enche, ela é descarregada no SSD como um arquivo imutável chamado SSTable (Static Sorted Table) no Nível 0.
Até aqui, o SSD QLC está confortável. O problema começa na compactação. Para evitar que as leituras precisem vasculhar milhares de arquivos, o RocksDB funde continuamente SSTables menores em SSTables maiores nos níveis inferiores (Nível 1, Nível 2, etc). Uma única inserção lógica pode ser lida e regravada fisicamente mais de dez vezes ao longo de sua vida útil no banco de dados.
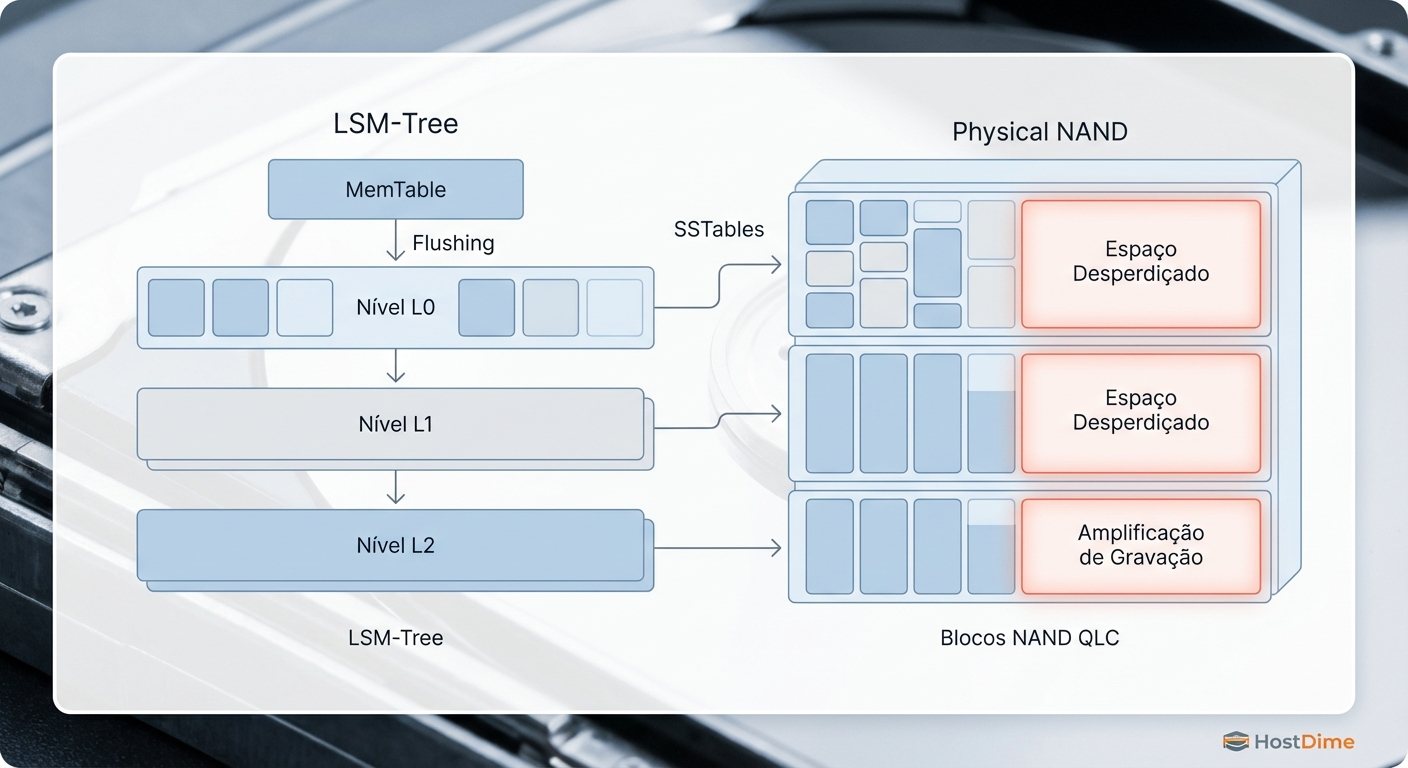 Figura: Diagrama ilustrando o desalinhamento entre as SSTables geradas pela LSM-Tree e os blocos físicos de apagamento em um SSD QLC.
Figura: Diagrama ilustrando o desalinhamento entre as SSTables geradas pela LSM-Tree e os blocos físicos de apagamento em um SSD QLC.
Na camada física do SSD QLC, os dados só podem ser gravados em páginas (geralmente 16KB), mas só podem ser apagados em blocos inteiros. Os blocos de apagamento no QLC são gigantescos, frequentemente ultrapassando 32MB ou 64MB. Se o RocksDB grava um arquivo de 2MB e depois o invalida durante uma compactação, o controlador do SSD (FTL - Flash Translation Layer) precisa mover dezenas de megabytes de dados válidos vizinhos para limpar aquele bloco. Esse processo é conhecido como Garbage Collection.
A combinação da amplificação de escrita do RocksDB (software) com a amplificação de escrita do Garbage Collection (hardware) cria um efeito multiplicador devastador para a vida útil do QLC.
Por que overprovisioning e drives TLC não resolvem a raiz do problema
A resposta instintiva de muitos arquitetos de infraestrutura ao notar o desgaste rápido é aplicar força bruta. A primeira tática é aumentar o overprovisioning, deixando 20% ou 30% do disco não particionado para dar mais espaço de manobra ao Garbage Collection do SSD. A segunda tática é abandonar o QLC e voltar para drives TLC mais caros.
Ambas as abordagens tratam o sintoma, não a doença. O overprovisioning melhora a performance sustentada e reduz a amplificação de escrita do hardware, mas não faz absolutamente nada para impedir que o RocksDB continue regravando os mesmos dados desnecessariamente. Voltar para o TLC destrói a viabilidade financeira de clusters de petabytes.
| Característica | SSD Enterprise TLC | SSD Enterprise QLC | Impacto no RocksDB Padrão |
|---|---|---|---|
| Bits por Célula | 3 | 4 | QLC exige maior precisão de voltagem. |
| Resistência (DWPD) | 1.0 a 3.0 | 0.1 a 0.8 | QLC esgota rapidamente com alto WAF. |
| Tamanho do Bloco de Apagamento | ~16MB | ~64MB+ | QLC sofre mais com arquivos pequenos. |
| Custo por Terabyte | Alto | Baixo | QLC viabiliza clusters NoSQL densos. |
| Cenário Ideal | Mixed Workloads | Read-Intensive | RocksDB precisa ser ajustado para QLC. |
A verdadeira solução exige que o administrador do banco de dados desça ao nível da configuração do motor de armazenamento e altere o comportamento de compactação para respeitar a física do disco subjacente.
Ajustando a compactação e o tamanho das SSTables para alinhar com o hardware
O RocksDB utiliza por padrão a estratégia Leveled Compaction. Ela é fantástica para otimizar a velocidade de leitura, pois mantém limites estritos de tamanho para cada nível da árvore. No entanto, para manter essa organização rigorosa, ela move dados constantemente, gerando um Write Amplification Factor (WAF) que pode chegar a 30x.
Para mídias sensíveis como o QLC, a mudança para Universal Compaction é mandatória em cargas de trabalho com alta ingestão de dados. A compactação universal foca em reduzir a amplificação de escrita. Em vez de forçar os dados a descerem por níveis estritos, ela agrupa arquivos de tamanhos semelhantes e os funde de uma só vez. Isso pode aumentar ligeiramente a latência de leitura e o uso temporário de espaço em disco, mas derruba o WAF do software para a casa de 5x a 10x.
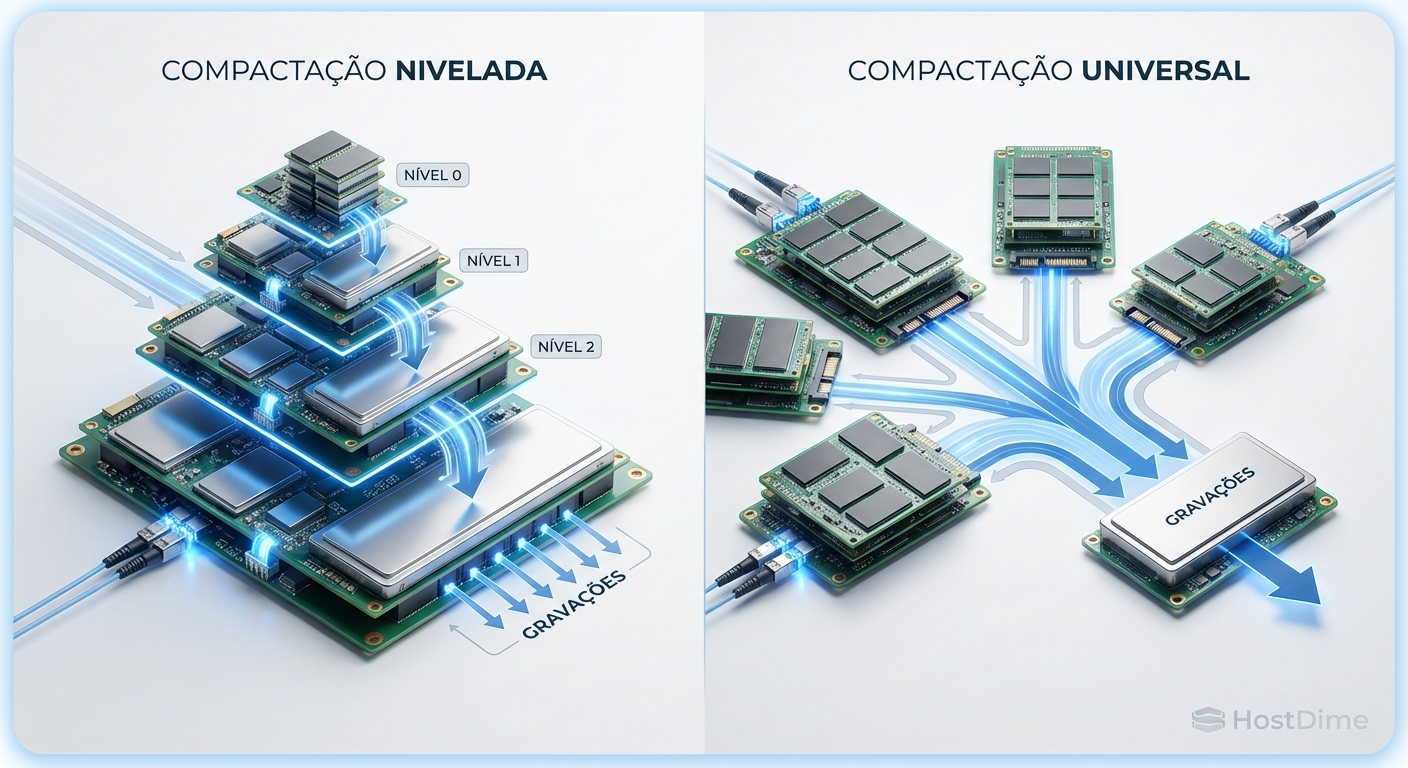 Figura: Comparativo visual do fluxo de dados: Leveled Compaction (foco em leitura) vs Universal Compaction (foco em preservação de mídia).
Figura: Comparativo visual do fluxo de dados: Leveled Compaction (foco em leitura) vs Universal Compaction (foco em preservação de mídia).
Além da estratégia, o tamanho dos arquivos gerados é crítico. O parâmetro target_file_size_base define o tamanho das SSTables. O padrão histórico do RocksDB de 64MB foi pensado para HDDs ou SSDs antigos. Em drives QLC modernos, onde o bloco de apagamento físico pode ter 64MB, gravar arquivos menores que isso garante que um único arquivo ocupará frações de vários blocos físicos.
💡 Dica Pro: Ajuste o
target_file_size_basepara alinhar com a geometria do seu SSD. Valores entre 128MB e 256MB frequentemente reduzem a fragmentação no nível do FTL do disco. Arquivos maiores significam que, quando o RocksDB deletar uma SSTable antiga, o SSD poderá apagar blocos físicos inteiros sem precisar fazer Garbage Collection de dados válidos.
Monitorando a amplificação de escrita via telemetria e atributos SMART
Você não pode otimizar o que não pode medir. Acompanhar a degradação do disco exige cruzar os dados lógicos do banco com os dados físicos do hardware.
No lado do RocksDB, a telemetria interna fornece os números exatos do que o software está fazendo. Consultando as estatísticas do banco, você deve monitorar os contadores bytes_written (dados lógicos enviados pela aplicação) e compact_write_bytes (dados físicos gravados no disco devido à compactação). A divisão do segundo pelo primeiro revela o WAF exclusivo do software.
No lado do sistema operacional, ferramentas como o nvme-cli são indispensáveis. O comando nvme smart-log /dev/nvme0n1 expõe os atributos vitais do drive. O campo data_units_written mostra o que o host enviou, enquanto contadores específicos do fabricante (frequentemente acessíveis via logs de telemetria estendida) mostram as gravações reais na NAND.
⚠️ Perigo: Se o seu WAF combinado (Software + Hardware) ultrapassar 15x em um array QLC, seu cluster está em risco iminente de falha em cascata. Quando um drive atinge o limite de TBW e entra em modo de apenas leitura, a reconstrução dos dados sobrecarregará os drives vizinhos, que provavelmente possuem o mesmo nível de desgaste.
O futuro do armazenamento denso exige co-design entre software e flash
A indústria de armazenamento reconheceu que esconder a complexidade da memória flash atrás de uma camada de tradução (FTL) opaca atingiu seu limite. Para extrair o máximo de mídias densas e baratas, o software precisa conversar diretamente com o hardware.
Duas tecnologias emergentes estão redefinindo essa relação. A primeira é o ZNS (Zoned Namespaces), um padrão NVMe que divide o SSD em zonas sequenciais. Em um drive ZNS, o SSD não faz Garbage Collection. O RocksDB (através de backends específicos como o ZenFS) assume a responsabilidade de gravar sequencialmente nas zonas e resetá-las quando os dados são invalidados. Isso elimina completamente a amplificação de escrita do hardware.
A segunda inovação é o FDP (Flexible Data Placement), formalizado no padrão NVMe TP4146. O FDP é menos radical que o ZNS. Ele mantém o FTL tradicional, mas permite que o RocksDB "marque" os dados. O banco de dados pode instruir o SSD a colocar dados com expectativa de vida semelhante (por exemplo, SSTables do mesmo nível de compactação) nos mesmos blocos físicos de apagamento.
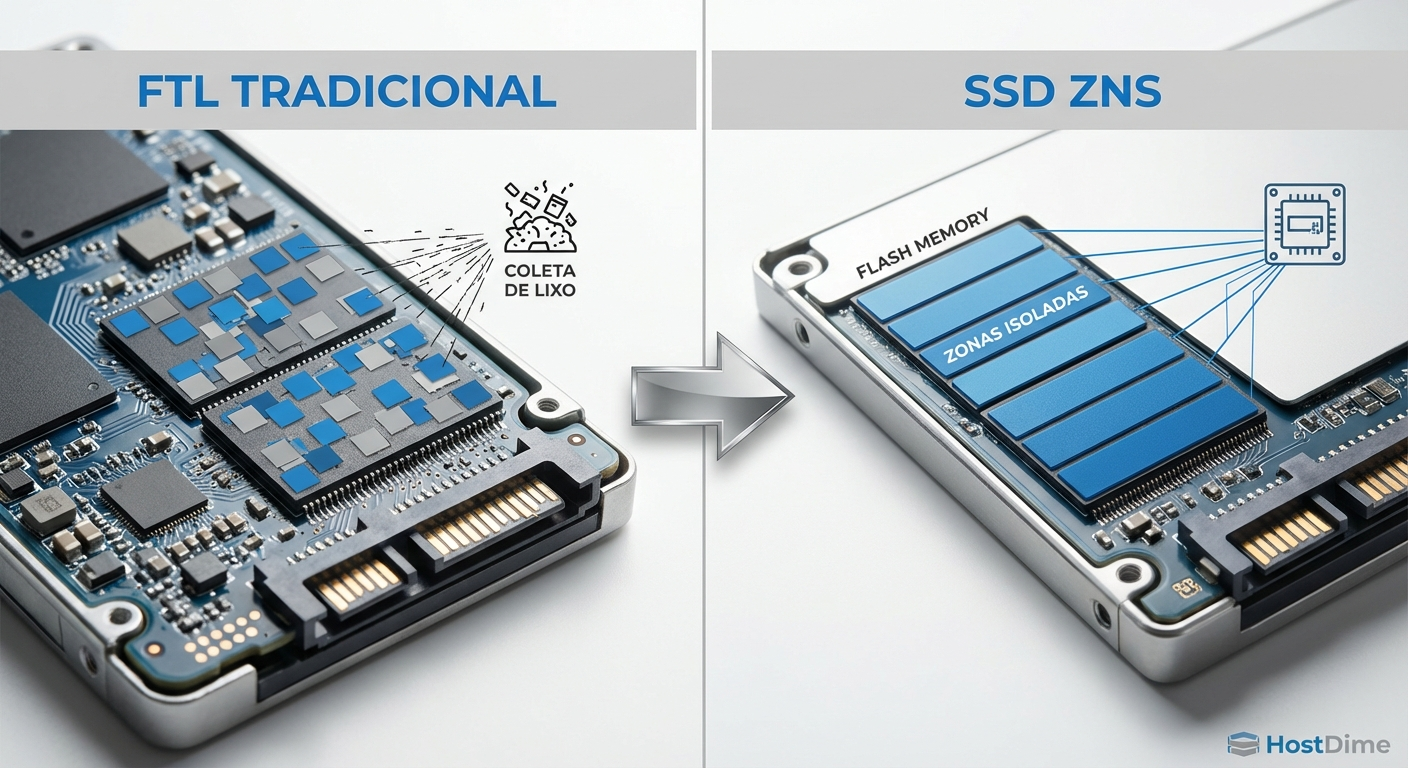 Figura: Arquitetura tradicional baseada em FTL versus o modelo ZNS, onde o host gerencia o posicionamento dos dados.
Figura: Arquitetura tradicional baseada em FTL versus o modelo ZNS, onde o host gerencia o posicionamento dos dados.
Essas tecnologias, combinadas com novos formatos físicos de servidores como o E1.S (Enterprise and Datacenter Standard Form Factor, desenhado para alta densidade e dissipação térmica eficiente), representam o estado da arte para infraestruturas NoSQL.
O veredito arquitetural
Tratar um SSD NVMe de alta capacidade como um disco rígido rápido é um erro de engenharia que custa caro. A adoção de mídias QLC em datacenters é um caminho sem volta para lidar com o crescimento exponencial dos dados. Contudo, a viabilidade dessa arquitetura depende inteiramente da sintonia fina do motor de armazenamento.
A recomendação para qualquer DBA operando clusters RocksDB em escala é auditar imediatamente as métricas de amplificação de escrita. A transição para a compactação universal e o redimensionamento das SSTables não são apenas ajustes de performance, são medidas de sobrevivência do hardware. O futuro do armazenamento corporativo pertence às equipes que entendem que o banco de dados e o silício do SSD operam como um único ecossistema integrado.
Referências & Leitura Complementar
RocksDB Tuning Guide: Repositório oficial do RocksDB no GitHub, seção de otimização de compactação e WAF.
NVMe Zoned Namespaces (ZNS): Especificação técnica da NVM Express (NVMe Command Set Specification).
Flexible Data Placement (FDP): NVM Express TP4146, detalhando a alocação de dados orientada pelo host.
SNIA (Storage Networking Industry Association): Publicações sobre arquitetura de SSDs corporativos e gerenciamento de ciclo de vida de NAND Flash.
O que é Write Amplification Factor (WAF) no contexto de bancos de dados?
É a razão matemática entre a quantidade de dados fisicamente gravados nos chips de memória do SSD e a quantidade de dados lógicos que o banco de dados solicitou gravar. Em arquiteturas baseadas em LSM-Tree, como o RocksDB, o WAF atinge níveis críticos devido aos processos contínuos de compactação em background, onde os mesmos dados são lidos e regravados múltiplas vezes para manter a árvore otimizada.Por que os SSDs QLC são mais vulneráveis ao write amplification?
A arquitetura NAND QLC armazena 4 bits por célula, exigindo níveis de voltagem extremamente precisos. Isso reduz drasticamente sua tolerância a ciclos de programa/apagamento (P/E cycles) quando comparado ao padrão TLC. Além disso, a geometria do QLC exige blocos de apagamento muito maiores. Se o motor de armazenamento enviar pequenas gravações aleatórias ou fragmentadas, o controlador do SSD precisará mover enormes quantidades de dados válidos apenas para limpar um bloco, causando um desgaste desproporcional e acelerado da mídia.Qual a diferença entre Leveled Compaction e Universal Compaction no RocksDB?
A Leveled Compaction é desenhada para otimizar a velocidade de leitura. Ela mantém limites estritos de tamanho para cada nível de dados, o que força o motor a mover e regravar arquivos constantemente, gerando um WAF altíssimo. Já a Universal Compaction sacrifica uma pequena fração da performance de leitura para focar na redução do WAF. Ela agrupa arquivos de tamanhos semelhantes e os processa em lotes maiores, sendo a configuração obrigatória para workloads com alta taxa de gravação (write-heavy) rodando em mídias sensíveis ao desgaste, como o QLC.
Roberto Lemos
Arquiteto de Workloads
"Projeto infraestrutura onde o perfil de I/O dita as regras. Sei que a latência do acesso aleatório de um banco difere da vazão sequencial de vídeos. Mapeio o hardware exato para cada aplicação."