Rpo E Rto Como Definir Metas Realistas

Muitas empresas caem na armadilha de buscar RPO e RTO próximos de zero sem entender as implicações. Um RPO de zero significa que você não pode perder *nenhum* d...
Rpo E Rto Como Definir Metas Realistas
A Falsa Promessa do "Sempre Ligado"
Muitas empresas caem na armadilha de buscar RPO e RTO próximos de zero sem entender as implicações. Um RPO de zero significa que você não pode perder nenhum dado. Um RTO de zero significa que o serviço deve estar disponível instantaneamente após uma falha. Atingir esses objetivos é possível, mas tem um custo proibitivo. Imagine replicar cada transação em tempo real para múltiplos data centers, com failover automático em frações de segundo. A complexidade e o custo dessa infraestrutura são astronômicos, e muitas vezes injustificáveis para a maioria das aplicações.
O problema é que a busca incessante por RPO/RTO zero leva a decisões ruins: arquiteturas excessivamente complexas, dependência de tecnologias caras e, ironicamente, maior probabilidade de falhas devido à própria complexidade.
Entendendo a Engrenagem: RPO e RTO em Detalhes
RPO (Recovery Point Objective) define a idade máxima aceitável dos dados que serão recuperados após um incidente. Em outras palavras, é o quão "para trás" você pode voltar no tempo. Se o RPO é de 1 hora, você pode perder, no máximo, os dados da última hora. Se é de 24 horas, pode perder os dados do último dia. O RPO é diretamente ligado à frequência dos seus backups ou replicação.
RTO (Recovery Time Objective) define o tempo máximo aceitável para restaurar um serviço após um incidente. É o tempo que leva para colocar o sistema de volta em funcionamento. Se o RTO é de 15 minutos, o serviço deve estar operacional em, no máximo, 15 minutos após a falha. O RTO é influenciado pela complexidade do processo de recuperação, a infraestrutura disponível e a automação.
A relação entre RPO, RTO e o custo da infraestrutura é inversamente proporcional: quanto menores o RPO e RTO, maior o investimento necessário.
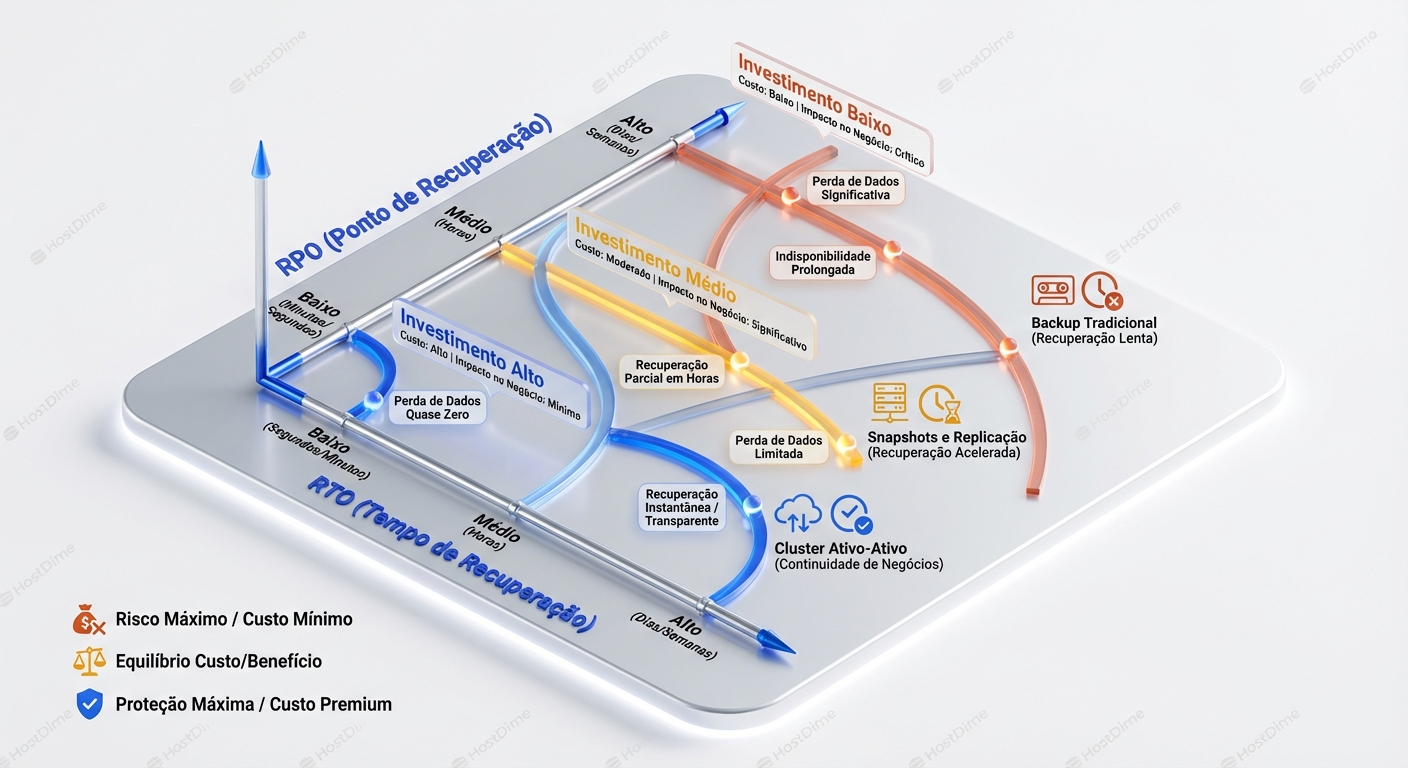
O Efeito Borboleta: Como Pequenas Perdas se Transformam em Desastres
Para entender a importância de definir RPO e RTO realistas, considere o impacto de uma perda de dados em diferentes áreas do negócio:
E-commerce: Um RPO de 24 horas significa perder todas as transações do último dia. Isso inclui pedidos, pagamentos, informações de clientes e atualizações de estoque. O impacto direto é a perda de receita, a insatisfação dos clientes e o dano à reputação da marca.
Banco: Um RPO de 1 hora pode significar a perda de milhares de transações financeiras, incluindo transferências, pagamentos e depósitos. As consequências podem ser multas regulatórias, processos judiciais e a perda da confiança dos clientes.
Hospital: Um RPO de 15 minutos pode significar a perda de dados vitais de pacientes, como resultados de exames, histórico médico e informações de medicação. Isso pode comprometer a segurança dos pacientes e levar a erros de diagnóstico e tratamento.
Indústria: Um RPO de 8 horas pode significar a perda de dados de produção, como configurações de máquinas, dados de qualidade e informações de rastreamento. Isso pode levar a interrupções na produção, perda de produtividade e o não cumprimento de prazos de entrega.
O RTO também tem um impacto significativo. Um RTO de 24 horas para um sistema crítico pode paralisar as operações da empresa, levando à perda de receita, a interrupção de serviços e o dano à reputação.
Da Teoria à Prática: Definindo Metas Realistas
O processo de definição de RPO e RTO deve começar com uma análise de impacto no negócio (BIA - Business Impact Analysis). O BIA é um processo sistemático que identifica os processos críticos da empresa e avalia o impacto de uma interrupção em cada um deles.
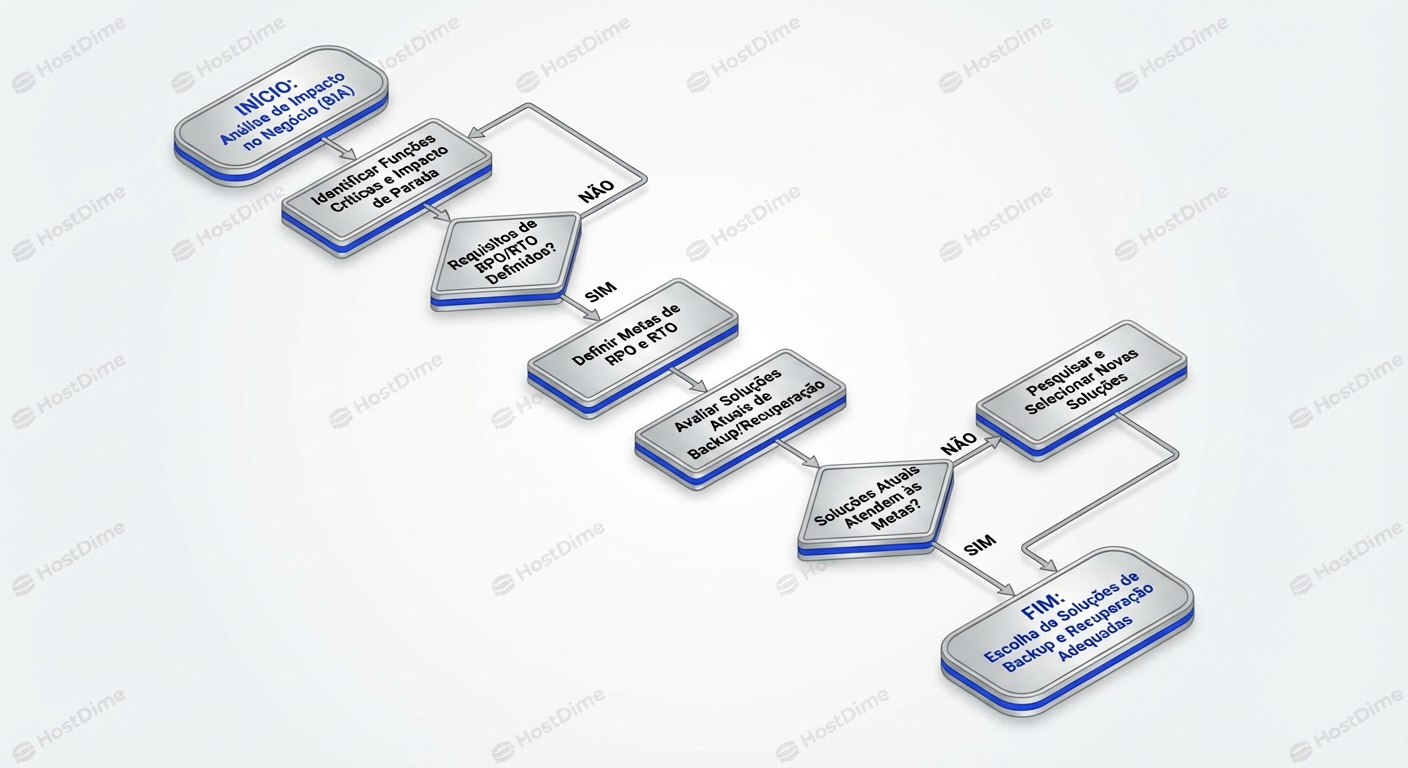
O BIA deve responder às seguintes perguntas:
- Quais são os processos críticos da empresa? Identifique os processos que são essenciais para a operação da empresa e que, se interrompidos, podem causar um impacto significativo.
- Qual é o impacto financeiro de uma interrupção em cada processo? Calcule o custo da interrupção em termos de perda de receita, multas regulatórias, perda de produtividade e outros custos.
- Qual é o impacto não financeiro de uma interrupção em cada processo? Avalie o impacto em termos de reputação da marca, satisfação dos clientes, conformidade regulatória e outros fatores não financeiros.
- Qual é o tempo máximo aceitável de interrupção para cada processo? Determine o tempo máximo que cada processo pode ficar interrompido sem causar um impacto inaceitável.
- Qual é a quantidade máxima de dados que pode ser perdida para cada processo? Determine a quantidade máxima de dados que pode ser perdida sem comprometer a integridade do processo.
Com base nos resultados do BIA, você pode definir RPO e RTO realistas para cada processo crítico. Lembre-se que RPO e RTO não são números absolutos, mas sim metas que devem ser alcançadas com um nível aceitável de risco e custo.
Onde a Batalha é Vencida ou Perdida: Cenários Reais
Cenário 1: E-commerce com RPO/RTO ambiciosos (mas atingíveis)
- RPO: 5 minutos.
- RTO: 10 minutos.
- Solução: Replicação síncrona de dados para um data center secundário, com failover automático em caso de falha. Monitoramento constante da saúde dos sistemas e testes regulares de failover.
- Justificativa: A perda de dados e a interrupção do serviço podem causar um impacto significativo na receita e na reputação da marca. O investimento em uma solução de alta disponibilidade é justificado pelo retorno potencial.
Cenário 2: Aplicação interna com RPO/RTO moderados
- RPO: 4 horas.
- RTO: 2 horas.
- Solução: Backup incremental diário para um storage local e backup completo semanal para a nuvem. Processo de recuperação documentado e testado regularmente.
- Justificativa: A aplicação é importante, mas a perda de dados e a interrupção do serviço não causam um impacto crítico no negócio. Uma solução de backup e recuperação mais simples e econômica é suficiente.
Cenário 3: Aplicação de teste com RPO/RTO relaxados
- RPO: 24 horas.
- RTO: 8 horas.
- Solução: Backup diário para um storage local. Recuperação manual em caso de falha.
- Justificativa: A aplicação não é crítica e a perda de dados e a interrupção do serviço não causam um impacto significativo no negócio. Uma solução de backup e recuperação básica é suficiente.
O Tiro Sai Pela Culatra: RPO/RTO irrealisticamente baixos
- RPO: 0 segundos.
- RTO: 0 segundos.
- Solução: Tentativa de usar tecnologias complexas e caras como "storage replication" em distâncias continentais com latência alta.
- Resultado: Falhas frequentes devido à complexidade da solução, custos exorbitantes e, ironicamente, RPO/RTO piores do que se tivessem adotado uma solução mais simples e realista. A latência inerente à distância física torna a replicação síncrona impraticável, levando a corrupção de dados e falhas de sincronização.
Detectando Problemas Antes da Explosão: Sinais de Alerta
Sinais de Saúde:
- Backups realizados com sucesso e dentro do tempo esperado.
- Testes de recuperação realizados regularmente e com resultados positivos.
- Monitoramento constante da saúde dos sistemas e da infraestrutura de backup e recuperação.
- Documentação atualizada dos processos de backup e recuperação.
- Equipe treinada e capacitada para executar os processos de backup e recuperação.
Sinais de Perigo:
- Falhas frequentes nos backups.
- Testes de recuperação com resultados negativos ou demorados.
- Falta de monitoramento da saúde dos sistemas e da infraestrutura de backup e recuperação.
- Documentação desatualizada dos processos de backup e recuperação.
- Falta de treinamento da equipe responsável pelos processos de backup e recuperação.
- Aumento da latência na replicação de dados.
- Alertas de erros de sincronização nos sistemas de replicação.
- Reclamações dos usuários sobre a lentidão dos sistemas.
Ferramentas do Ofício: Diagnóstico e Monitoramento
Para garantir que seus RPO e RTO estão sendo cumpridos, é fundamental monitorar a saúde dos seus sistemas e da sua infraestrutura de backup e recuperação. Algumas ferramentas úteis incluem:
- Monitoramento de backups: Utilize ferramentas de monitoramento para verificar se os backups estão sendo realizados com sucesso e dentro do tempo esperado. Verifique os logs de backup em busca de erros e alertas.
grep "error" /var/log/backup.log grep "warning" /var/log/backup.log - Monitoramento de replicação: Monitore a latência e o status da replicação de dados. Verifique se os dados estão sendo replicados corretamente e se não há erros de sincronização.
# Exemplo de comando para verificar o status da replicação (específico para a tecnologia utilizada) # (Substitua pelo comando correto para sua solução de replicação) replication_status_command - Testes de recuperação: Realize testes de recuperação regularmente para verificar se os sistemas podem ser restaurados dentro do RTO definido. Documente os resultados dos testes e identifique áreas de melhoria.
- Monitoramento de performance: Monitore a performance dos sistemas para identificar gargalos e problemas que possam afetar o RTO. Utilize ferramentas de monitoramento de sistema (ex:
top,htop,iostat) para identificar o uso excessivo de recursos.# Exemplo de uso do iostat para monitorar o uso do disco iostat -xz 1 - Alertas: Configure alertas para serem notificado em caso de falhas ou problemas. Utilize ferramentas de monitoramento para enviar alertas por e-mail, SMS ou outros canais.
O Veredito Final: Resiliência Realista
Definir RPO e RTO realistas é um exercício de equilíbrio entre o custo da infraestrutura, o risco de perda de dados e a tolerância à interrupção do serviço. Não existe uma fórmula mágica que funcione para todas as empresas. O importante é entender o impacto de uma interrupção no seu negócio e definir metas que sejam alcançáveis e justificáveis.
Fuja da armadilha do "RPO/RTO zero". Em vez disso, concentre-se em construir uma infraestrutura resiliente, com backups regulares, replicação de dados e processos de recuperação bem definidos e testados. Lembre-se que a melhor defesa contra a perda de dados é a preparação. Invista em treinamento, documentação e monitoramento. E, acima de tudo, seja realista.

André Linhares
Engenheiro de Performance (Kernel/IO)
"Vivo no kernel space caçando latência com eBPF. Para mim, context switches excessivos são inimigos pessoais e cada ciclo de CPU desperdiçado é uma ofensa técnica."