Runbook de latência: como diagnosticar gargalos de storage sem pânico

Guia SRE para triagem de incidentes de latência em storage. Do alerta de SLO à análise de filas de I/O e saturação, eliminando a cultura de culpa.
O pager toca às 03:14 da manhã. O alerta não é sobre "disco cheio", mas algo muito mais insidioso: a latência do subsistema de armazenamento cruzou o limiar do SLO (Service Level Objective). A aplicação, que depende de leituras randômicas em milissegundos, está engasgando. O instinto natural de muitos administradores de sistemas é culpar o disco ou, pior, reiniciar o servidor. Na engenharia de confiabilidade (SRE), sabemos que reiniciar é apenas adiar o inevitável e culpar o hardware sem evidência é desperdício de orçamento de erro.
A latência de armazenamento é o sintoma final de uma cadeia complexa de eventos probabilísticos. Diagnosticar um gargalo em um pool ZFS, um array All-Flash ou um cluster Ceph exige abandonar a intuição e abraçar a observabilidade baseada em métricas. Não estamos procurando por um "disco ruim" (isso é fácil); estamos caçando a saturação de filas, a contenção de barramento e o vizinho barulhento que está consumindo seus IOPS.
Resumo em 30 segundos
- Médias mentem: Ignorar a latência de cauda (p99/p99.9) esconde a verdadeira experiência do usuário; um disco lento em um array de 100 pode destruir a performance global.
- A Lei de Little é soberana: A latência é função direta do tamanho da fila. Se você envia requisições mais rápido do que o dispositivo consegue processar (Queue Depth), a latência explode exponencialmente.
- Saturação não é apenas % de uso: Em SSDs e NVMe, olhar apenas para "% Util" no
iostaté inútil. Você deve monitorar a latência por operação e a profundidade da fila para entender o gargalo real.
O pico de latência p99 e a violação imediata do SLO
Quando definimos um SLO para armazenamento, raramente nos importamos com a média. A média dilui o sofrimento. Se 99 requisições levam 1ms e 1 requisição leva 10 segundos, a média é aceitável (~100ms), mas aquele 1% dos usuários (ou processos) sofreu um timeout catastrófico.
Em sistemas distribuídos ou arrays RAID, a latência do sistema é frequentemente ditada pelo componente mais lento. Este é o fenômeno da "latência de cauda". Se o seu banco de dados precisa fazer scatter-gather em 10 discos para montar uma resposta, e um desses discos está sofrendo com retries de leitura (ECC correction em andamento), toda a requisição é bloqueada.
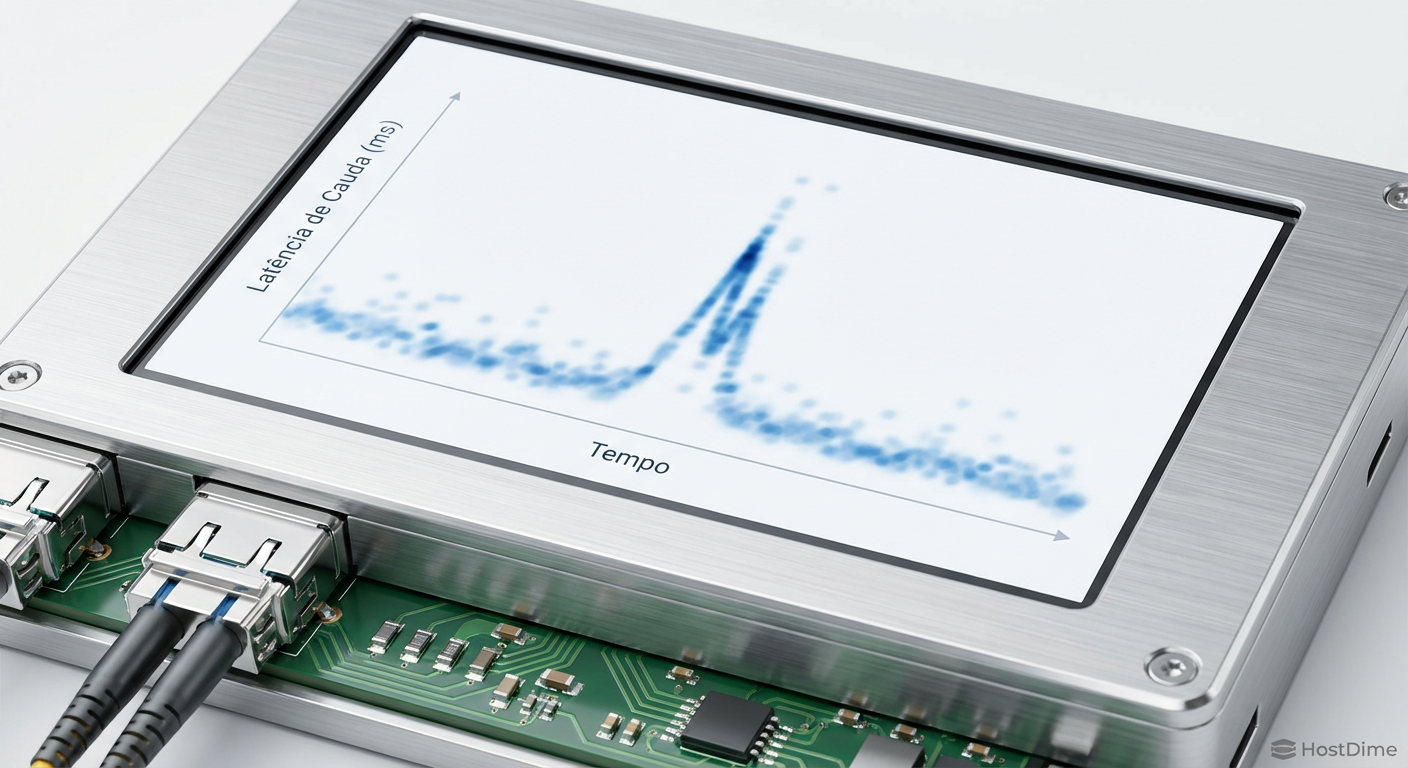 Fig. 2: Heatmap demonstrando como picos esporádicos de latência (outliers) são invisíveis em gráficos de médias simples.
Fig. 2: Heatmap demonstrando como picos esporádicos de latência (outliers) são invisíveis em gráficos de médias simples.
O gráfico acima ilustra o perigo. Enquanto a linha de base (média) parece estável, os pontos de calor (outliers) mostram eventos onde o tempo de serviço do disco excedeu 500ms. Para uma aplicação transacional esperando respostas em NVMe (usualmente <100µs), isso é uma eternidade geológica. O diagnóstico começa por parar de olhar para o avg_lat e focar obsessivamente nos percentis superiores.
💡 Dica Pro: Configure seus alertas do Prometheus ou Zabbix para disparar baseados na queima do Error Budget do p99. Se a latência p99 > 50ms por 5 minutos, isso é um incidente. Se a média subir, mas o p99 se mantiver estável, é apenas carga, não necessariamente um problema.
A física por trás da saturação de fila no controlador do disco
Para entender por que o armazenamento fica lento, precisamos revisitar a Lei de Little: $L = \lambda W$. O número médio de itens no sistema ($L$) é igual à taxa média de chegada ($\lambda$) multiplicada pelo tempo médio que um item gasta no sistema ($W$).
No contexto de um SSD NVMe ou um HDD SAS:
Chegada ($\lambda$): As IOPS que sua aplicação está enviando.
Tempo no Sistema ($W$): A latência real (tempo de serviço + tempo de espera na fila).
Itens no Sistema ($L$): A Queue Depth (QD).
O controlador de um disco (seja o firmware de um SSD Enterprise ou a placa lógica de um HDD) tem um limite físico de quantas operações pode processar simultaneamente. Um HDD mecânico, limitado pela física de mover uma cabeça de leitura, tem um paralelismo efetivo próximo de 1 (ou ligeiramente maior com NCQ - Native Command Queuing). Um SSD NVMe moderno pode ter 64.000 filas com 64.000 comandos cada.
O problema ocorre quando o software (sistema operacional ou hypervisor) inunda o dispositivo. Quando a fila de entrada enche, o tempo de espera ($W$) sobe não linearmente. O dispositivo não está "quebrado"; ele está saturado.
⚠️ Perigo: Em ambientes virtualizados (VMware/Proxmox), existe o problema da "fila dupla". O sistema operacional Guest tem sua fila, o Hypervisor tem outra, e o HBA físico tem uma terceira. Latência observada no Guest pode ser puramente tempo de espera na fila do Hypervisor, enquanto o disco físico está ocioso. Sempre correlacione métricas do host e do guest.
Aplicação das quatro métricas douradas para isolar o ruído
O Google SRE Book introduziu as "Four Golden Signals". Adaptá-las para o contexto de block storage é a maneira mais rápida de isolar a causa raiz.
 Fig. 1: As quatro métricas douradas adaptadas para diagnóstico de subsistemas de armazenamento.
Fig. 1: As quatro métricas douradas adaptadas para diagnóstico de subsistemas de armazenamento.
1. Latência (Latency)
Não trate leitura e escrita como iguais.
Sintoma: Latência de escrita alta em SSDs geralmente indica Garbage Collection agressivo ou esgotamento do cache SLC.
Sintoma: Latência de leitura alta em HDDs geralmente indica fragmentação ou busca mecânica excessiva (thrashing).
Ação: Segmente seus gráficos por
r_awaitew_await(no Linux).
2. Tráfego (Traffic)
Aqui medimos a demanda.
IOPS: Crítico para bancos de dados e cargas randômicas.
Throughput (MB/s): Crítico para streaming, backup e ingestão de logs.
O Erro Comum: Um disco pode estar saturado com apenas 100 IOPS se forem leituras randômicas de 4KB em um HDD, ou pode estar livre com 500MB/s se for uma leitura sequencial. O contexto do tamanho do bloco (block size) é vital.
3. Erros (Errors)
Erros em storage não são apenas falhas totais.
Hard Errors: O disco sumiu do barramento (/dev/sdX não existe).
Soft Errors: Retries de SCSI, timeouts de comando, erros de CRC no cabo SAS/SATA.
Observabilidade: Verifique os contadores de interface (phy counters). Um cabo SAS mal encaixado pode causar retransmissões que se manifestam como latência alta, não como queda do disco.
4. Saturação (Saturation)
A métrica mais complexa.
Em HDDs, a saturação é frequentemente visível quando a utilização (%util) chega a 100%.
Em SSDs/NVMe, %util é irrelevante devido ao paralelismo interno. A verdadeira medida de saturação é a Queue Length (tamanho da fila). Se a fila ativa é consistentemente maior que 1, você tem contenção.
Por que adicionar discos cegamente agrava a contenção de I/O
Uma reação de pânico comum durante um incidente de latência é "adicionar mais vdevs ao pool" ou "expandir o volume". Isso assume que o gargalo é a capacidade de processamento dos discos individuais. Frequentemente, não é.
Se o gargalo for o controlador de armazenamento (HBA/RAID Card), o barramento PCIe ou a CPU do storage server (interrupções), adicionar mais discos apenas aumenta a sobrecarga de gerenciamento.
O Custo das Interrupções
Cada operação de I/O gera uma interrupção na CPU (embora interrupt coalescing e polling em drivers NVMe modernos tentem mitigar isso). Se sua CPU já está saturada lidando com context switching de I/O, adicionar mais discos rápidos (como NVMe) vai piorar a latência da aplicação, pois a CPU gastará mais tempo atendendo o hardware do que rodando o código do negócio.
Contenção de Cache (ARC/L2ARC)
Em sistemas como ZFS ou TrueNAS, adicionar discos giratórios lentos a um pool que sofre de cache miss não resolve o problema. Se a latência é alta porque sua Working Set Size (WSS) excede a RAM (ARC), a solução é adicionar memória ou um dispositivo de cache rápido (L2ARC/SLOG), não mais discos de dados. Adicionar discos de dados apenas aumenta a largura de banda teórica, mas não resolve a latência de busca randômica se os metadados não estiverem em cache.
Validação da correção através de testes sintéticos com fio
Após identificar que o problema era, por exemplo, um Noisy Neighbor (uma VM de backup rodando no mesmo datastore que o banco de dados), e mover a carga, como provamos a resolução? "Parece mais rápido" não é engenharia.
Usamos ferramentas de I/O sintético como o fio para validar a performance sem a variabilidade da aplicação. O objetivo é reproduzir o padrão de acesso que causou o incidente.
Exemplo de um teste controlado para validar latência de escrita randômica (comumente o calcanhar de Aquiles de bancos de dados):
fio --name=validacao_pos_incidente \
--ioengine=libaio \
--rw=randwrite \
--bs=4k \
--direct=1 \
--size=10G \
--numjobs=1 \
--iodepth=16 \
--runtime=60 \
--time_based \
--group_reporting
Análise dos parâmetros:
--direct=1: Ignora o cache de página do SO. Queremos testar o disco/rede, não a RAM.--rw=randwrite: Simula o pior cenário para a maioria dos storages.--iodepth=16: Garante que estamos pressionando a fila o suficiente para expor latência sob carga, mas sem saturar artificialmente um array enterprise.
Se os resultados do fio mostrarem latência p99 dentro do SLO estabelecido, o incidente pode ser encerrado. Caso contrário, a investigação deve descer para a camada física (firmware, cabeamento, backplane).
O caminho para a antifragilidade
Diagnosticar latência de storage não é sobre adivinhar qual disco está piscando a luz vermelha. É um exercício de isolamento de variáveis em um sistema complexo. O objetivo final de um SRE não é apenas consertar o incidente de hoje, mas garantir que o sistema possa degradar graciosamente no futuro.
A recomendação para equipes de infraestrutura é investir pesadamente em observabilidade granular. Se você não consegue ver a latência por disco individual e correlacioná-la com a latência da aplicação em tempo real, você está voando às cegas. A próxima vez que o pager tocar, não reinicie. Meça, isole e corrija a causa raiz sistêmica. A cultura de post-mortem sem culpa depende de dados, e os dados estão nos logs do seu controlador, esperando para serem lidos.
Referências & Leitura Complementar
Gregg, Brendan. Systems Performance: Enterprise and the Cloud, 2nd Edition. (Capítulo sobre Discos e Sistemas de Arquivos). Addison-Wesley, 2020.
Google SRE Team. Site Reliability Engineering: How Google Runs Production Systems. (Capítulo sobre Monitoramento de Sistemas Distribuídos). O'Reilly Media, 2016.
NVM Express. NVM Express Base Specification 2.0. (Seção sobre Queue Arbitration e Command Handling). NVMe.org.
SNIA. Solid State Storage Performance Test Specification (PTS). Storage Networking Industry Association.
Perguntas Frequentes
1. Por que meu SSD mostra 100% de utilização mas a latência está baixa?
Em SSDs modernos, a métrica %util do iostat é frequentemente enganosa. Ela apenas indica que há pelo menos uma I/O em andamento. Como SSDs são massivamente paralelos, estar "ocupado" não significa estar "cheio". Monitore a Queue Depth e a latência média de serviço (r_await/w_await) para a verdade real.
2. O que é "Latência de Cauda" (Tail Latency) e por que devo me preocupar? Latência de cauda refere-se aos tempos de resposta mais lentos (o percentil 99 ou 99.9). Em storage, isso é crítico porque uma única leitura lenta pode bloquear uma transação inteira de banco de dados, fazendo com que a CPU fique ociosa esperando o disco (I/O Wait), desperdiçando recursos caros.
3. Devo usar RAID 5/6 para performance? Geralmente não para cargas de escrita randômica. RAID 5/6 (ou RAIDZ1/Z2) introduz uma penalidade de paridade significativa ("Write Penalty"). Para cada escrita lógica, o sistema precisa ler, calcular e escrever paridade. Para alta performance e baixa latência, RAID 10 (espelhamento + striping) é o padrão ouro da indústria.
4. Como a temperatura afeta a latência do NVMe? SSDs NVMe possuem mecanismos de Thermal Throttling. Se o controlador superaquecer (comum acima de 70°C-80°C), ele reduzirá drasticamente a velocidade de clock para se proteger, causando picos massivos de latência. Monitoramento térmico é parte do monitoramento de performance.

Rafael Junqueira
Engenheiro de Confiabilidade (SRE)
"Transformo caos em estabilidade via observabilidade. Defensor da cultura blameless e focado em SLIs e SLOs. Se algo falhou, revisamos o sistema, nunca a pessoa."