Tempestades de escrita em LLM checkpointing: como arquitetar storage NVMe para clusters de GPU

Entenda a anatomia do gargalo de I/O no treinamento de IA e aprenda a projetar topologias NVMe-oF com GPUDirect Storage para eliminar a ociosidade das GPUs.
O treinamento de Large Language Models (LLMs) expôs uma falha fundamental na forma como arquitetamos infraestrutura de dados. Quando você tem milhares de GPUs processando tensores simultaneamente, o gargalo inevitavelmente muda da computação para o armazenamento. O momento mais crítico dessa operação não é o cálculo matricial, mas o salvamento do estado do modelo.
Chamamos esse evento de tempestade de escrita (write storm). Durante um checkpoint, todas as GPUs do cluster pausam o treinamento e tentam descarregar terabytes de pesos, gradientes e estados do otimizador para o disco no exato mesmo milissegundo. Se a sua arquitetura de storage NVMe não estiver preparada para absorver essa rajada massiva de I/O sequencial, suas GPUs de altíssimo custo ficarão ociosas esperando a confirmação de gravação no disco. Em escala de datacenter, ciclos de GPU ociosos representam uma queima literal de dinheiro.
Resumo em 30 segundos
- Checkpoints de LLMs geram picos massivos de I/O sincronizado que saturam barramentos PCIe e buffers de controladoras tradicionais.
- Empilhar SSDs de consumo em RAID 0 local destrói a vida útil dos discos (DWPD) e não resolve a latência de cauda no cluster.
- A solução definitiva exige NVMe over Fabrics (NVMe-oF) integrado ao GPUDirect Storage para contornar a CPU e gravar direto via RDMA.
A física do barramento PCIe e a saturação de buffers
Para entender a gravidade de uma tempestade de escrita, precisamos olhar para a física do servidor. Um nó de treinamento típico possui oito GPUs conectadas via switches PCIe (Peripheral Component Interconnect Express) ou topologias proprietárias como NVLink. Quando o comando de checkpoint é disparado, a memória HBM (High Bandwidth Memory) das GPUs precisa ser esvaziada para o armazenamento não volátil.
O problema ocorre porque o I/O gerado é altamente sincronizado. Não estamos lidando com o padrão de acesso aleatório típico de um banco de dados transacional (OLTP). Estamos lidando com blocos gigantescos de dados sequenciais sendo empurrados simultaneamente. Isso satura instantaneamente a largura de banda do barramento PCIe Gen4 ou Gen5.
Quando a banda do barramento esgota, os buffers das controladoras de rede (NICs) e das controladoras de armazenamento (HBAs) enchem. Assim que o buffer lota, o sistema operacional começa a enfileirar os pacotes de I/O. É neste exato momento que a latência dispara de microssegundos para dezenas de milissegundos, forçando as GPUs a entrarem em estado de espera (I/O wait).
 Figura: Diagrama ilustrando o gargalo físico no barramento PCIe durante um checkpoint sincronizado de GPUs.
Figura: Diagrama ilustrando o gargalo físico no barramento PCIe durante um checkpoint sincronizado de GPUs.
⚠️ Perigo: Ignorar a topologia NUMA (Non-Uniform Memory Access) ao alocar suas placas de rede e discos NVMe fará com que o tráfego de I/O cruze o barramento de interconexão das CPUs (como o UPI da Intel). Isso adiciona latência desnecessária e reduz a banda efetiva pela metade.
O mito do RAID 0 local com SSDs de consumo
Uma tentativa comum e desastrosa de resolver esse gargalo é instalar múltiplos SSDs NVMe M.2 de consumo diretamente no nó da GPU e configurá-los em RAID 0 via software. A lógica superficial sugere que somar a banda de leitura e escrita de vários discos resolverá o problema do checkpoint. Na prática, essa abordagem falha em dois pilares críticos: durabilidade e latência de cauda.
Discos de consumo não são projetados para o ciclo de trabalho de IA. A métrica fundamental aqui é o DWPD (Drive Writes Per Day). Um SSD NVMe focado em leitura pode ter um DWPD de 0.3. Em um cluster de treinamento de LLM, onde checkpoints de múltiplos terabytes ocorrem a cada poucas horas, você esgotará a vida útil das células de memória flash NAND (seja TLC ou QLC) em questão de semanas. Quando a controladora do SSD percebe a degradação, ela entra em ciclos agressivos de garbage collection, o que destrói o desempenho de escrita.
Além disso, o RAID 0 local cria ilhas de armazenamento. Se um nó falhar, os pesos daquele checkpoint específico ficam inacessíveis para o resto do cluster, exigindo a reconstrução do estado a partir de um checkpoint global mais antigo, desperdiçando horas de treinamento.
| Característica | RAID 0 Local (SSDs Consumo) | Storage Compartilhado (NVMe-oF Enterprise) |
|---|---|---|
| Durabilidade (DWPD) | Baixa (0.3 a 1.0) | Alta (3.0 a 10.0+) |
| Resiliência a Falhas | Nenhuma (Falha de 1 disco perde tudo) | Alta (Erasure Coding, Alta Disponibilidade) |
| Acesso Global | Não (Isolado no nó) | Sim (Acessível por todo o cluster) |
| Latência de Cauda | Imprevisível sob carga contínua | Previsível e controlada |
| Form Factor Típico | M.2 (Propenso a thermal throttling) | U.2, U.3 ou E1.S / E3.S |
Para cargas de trabalho de IA, o padrão da indústria migrou para formatos corporativos como o E1.S (Enterprise and Datacenter Standard Form Factor). O E1.S permite maior densidade de armazenamento, hot-swap e, crucialmente, dissipação térmica superior, evitando que o disco reduza sua velocidade (thermal throttling) durante uma gravação contínua de 15 minutos.
Implementando NVMe over Fabrics e GPUDirect Storage
A arquitetura correta para absorver tempestades de escrita exige a separação entre computação e armazenamento, sem sacrificar a latência. É aqui que entra o NVMe over Fabrics (NVMe-oF) rodando sobre redes RDMA (Remote Direct Memory Access), como RoCE v2 (RDMA over Converged Ethernet) ou InfiniBand.
O NVMe-oF permite que o protocolo NVMe seja encapsulado e transmitido pela rede. No entanto, o verdadeiro salto de performance ocorre quando integramos isso ao GPUDirect Storage (GDS). Em um fluxo de I/O tradicional, os dados saem da memória da GPU, vão para a memória do sistema (RAM), passam pela CPU (bounce buffer) e só então são enviados para a placa de rede em direção ao storage. Esse caminho desperdiça ciclos de CPU e dobra o tráfego no barramento de memória.
Com o GPUDirect Storage, estabelecemos um caminho direto de DMA (Direct Memory Access) entre a memória HBM da GPU e a placa de rede (NIC). Os dados fluem da GPU diretamente para os arrays de storage NVMe remotos, ignorando completamente a CPU e a memória do host.
 Figura: Comparativo do caminho de dados tradicional versus o bypass de CPU proporcionado pelo GPUDirect Storage.
Figura: Comparativo do caminho de dados tradicional versus o bypass de CPU proporcionado pelo GPUDirect Storage.
💡 Dica Pro: Para que o GPUDirect Storage funcione com eficiência máxima, você precisa de um sistema de arquivos paralelo compatível, como Lustre, IBM Storage Scale ou soluções modernas baseadas em DAOS (Distributed Asynchronous Object Storage). Sistemas de arquivos tradicionais como NFS não conseguem orquestrar I/O direto da GPU em escala.
Medindo a latência no percentil 99 e a taxa de utilização
Como arquitetos de workloads, não podemos confiar na latência média. A latência média esconde os picos que causam o travamento do cluster. Em um ambiente distribuído, a velocidade do checkpoint é ditada pelo nó mais lento. Se 99 nós gravarem seus dados em 10 segundos, mas um nó levar 45 segundos devido a um gargalo de I/O, todo o cluster ficará ocioso por 35 segundos.
Por isso, precisamos focar na latência de cauda, especificamente no percentil 99 (P99) e P99.9. Para validar a arquitetura de storage antes de colocar o modelo em produção, utilizamos ferramentas de geração de carga sintética como o fio (Flexible I/O Tester).
Ao configurar o fio para simular um checkpoint, devemos usar blocos de tamanho grande (ex: 1MB a 4MB), profundidade de fila (queue depth) elevada e I/O estritamente sequencial. O objetivo é saturar a rede e os discos para observar como a controladora de storage lida com a pressão contínua.
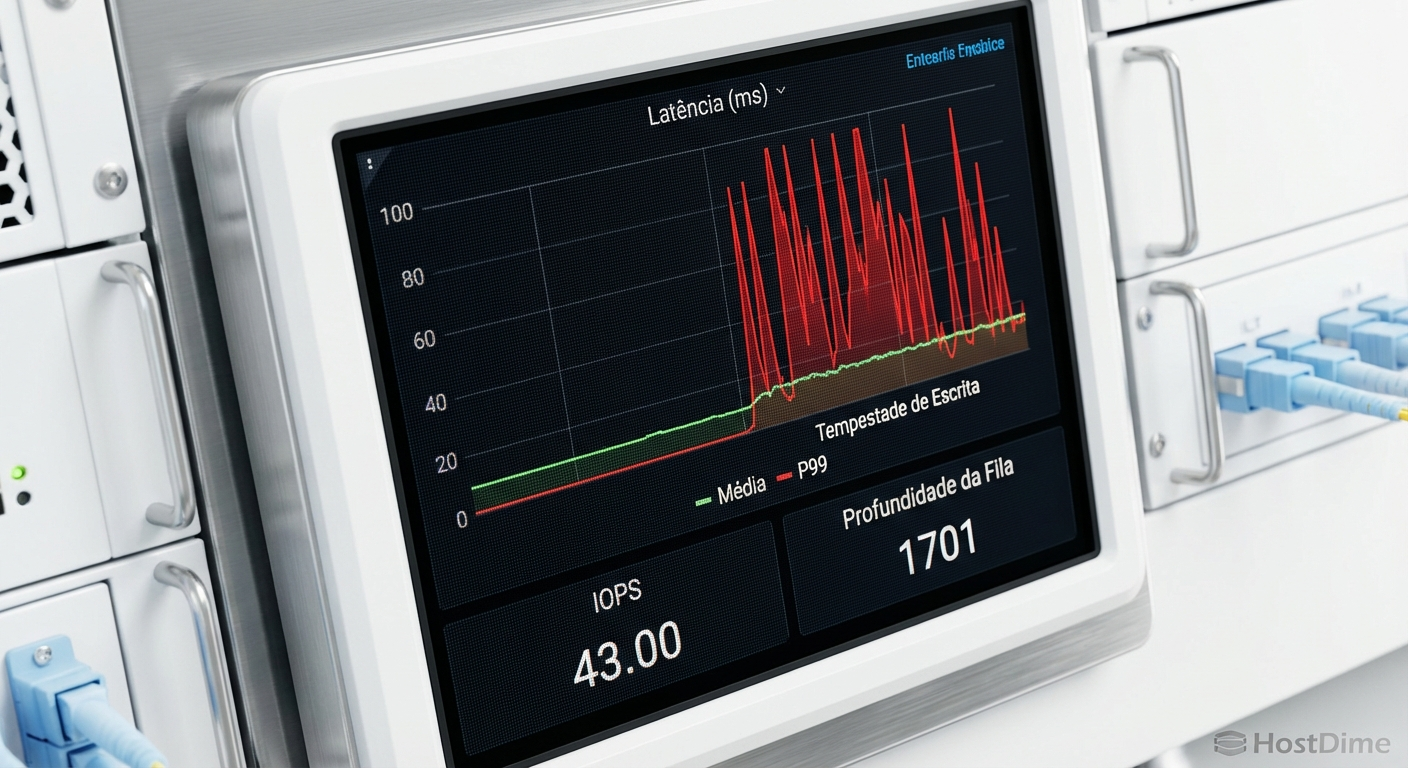 Figura: Dashboard de monitoramento evidenciando os picos de latência de cauda (P99) que ficam ocultos ao observar apenas a latência média.
Figura: Dashboard de monitoramento evidenciando os picos de latência de cauda (P99) que ficam ocultos ao observar apenas a latência média.
Durante o treinamento real, a ferramenta de escolha é o NVIDIA Nsight Systems. Ele permite perfilar a execução e visualizar exatamente a linha do tempo das GPUs. Se você observar grandes blocos vazios na linha do tempo de computação (CUDA cores ociosos) alinhados com picos de atividade nas APIs de sistema de arquivos (POSIX I/O), você tem a confirmação visual de que seu storage está estrangulando seu treinamento.
Recomendação Arquitetural
Tratar o armazenamento como um cidadão de segunda classe em projetos de Inteligência Artificial é o caminho mais rápido para o fracasso financeiro do projeto. O custo de ter dezenas de GPUs H100 ou A100 ociosas esperando por discos lentos supera rapidamente qualquer economia feita na compra de SSDs inadequados ou redes legadas.
Projete seu storage para o pior cenário possível: a tempestade de escrita sincronizada. Exija discos NVMe Enterprise com alto DWPD, adote formatos modernos como E1.S para densidade e refrigeração, e implemente NVMe-oF com GPUDirect Storage desde o dia zero. A eficiência do seu cluster de IA não é medida apenas por quantos teraflops ele processa, mas por quão rápido ele consegue salvar o que aprendeu.
Referências & Leitura Complementar
NVM Express Base Specification 2.0: Documentação oficial do protocolo NVMe, detalhando o funcionamento de filas de submissão e completude.
SNIA Solid State Storage Performance Test Specification (PTS): Metodologia padrão da indústria para condicionamento e teste de SSDs corporativos, essencial para entender degradação de performance.
NVIDIA GPUDirect Storage Design Guide: Arquitetura de referência para implementação de bypass de CPU em clusters de alta performance.
JEDEC Solid State Drive Requirements and Endurance Test Method (JESD218): Padrões de teste para classificação de DWPD e retenção de dados em memórias flash.
O que causa a tempestade de escrita (write storm) no treinamento de LLMs?
Durante o treinamento, o estado do modelo (pesos e otimizadores) precisa ser salvo periodicamente para evitar perda de progresso em caso de falha de hardware. Como milhares de GPUs gravam esses dados simultaneamente, gera-se um pico massivo de I/O que satura a infraestrutura de storage.Qual a diferença entre usar um NAS tradicional e NVMe-oF para clusters de GPU?
Um NAS tradicional usa protocolos como NFS ou SMB que adicionam overhead de CPU e latência de rede. O NVMe over Fabrics (NVMe-oF), especialmente aliado ao GPUDirect Storage, permite que as GPUs gravem dados diretamente nos discos NVMe remotos via RDMA, ignorando a CPU do host e reduzindo drasticamente a latência.Por que o DWPD (Drive Writes Per Day) é crítico em discos para IA?
Checkpoints frequentes de modelos massivos geram petabytes de gravações mensais. Discos NVMe de consumo ou de leitura intensiva com baixo DWPD esgotam sua vida útil rapidamente nesse cenário, exigindo SSDs Enterprise com alta tolerância a gravação mista e sequencial contínua.
Roberto Lemos
Arquiteto de Workloads
"Projeto infraestrutura onde o perfil de I/O dita as regras. Sei que a latência do acesso aleatório de um banco difere da vazão sequencial de vídeos. Mapeio o hardware exato para cada aplicação."