Tempestades de PFC em NVMe-oF: diagnóstico e mitigação em redes RoCEv2
Análise de SRE sobre como o Priority Flow Control pode paralisar infraestruturas de storage NVMe-oF. Aprenda a identificar tempestades de broadcast e configurar watchdogs para garantir a confiabilidade do RoCEv2.
A latência é a nova indisponibilidade. Em arquiteturas de armazenamento distribuído modernas, onde NVMe-oF (NVMe over Fabrics) promete tempos de resposta na casa dos microssegundos, a rede deixa de ser apenas um tubo e torna-se parte integrante do barramento de I/O. No entanto, a busca pelo "zero packet loss" em redes Ethernet através do RoCEv2 (RDMA over Converged Ethernet v2) introduziu um modo de falha catastrófico e muitas vezes invisível: a tempestade de PFC (Priority Flow Control).
Quando um cluster de storage NVMe apresenta picos de latência de cauda (p99) inexplicáveis ou timeouts de I/O em massa, raramente o problema está no disco físico. O culpado geralmente é um mecanismo de proteção de rede que funcionou "bem demais", paralisando o tráfego legítimo em uma tentativa desesperada de evitar o descarte de pacotes.
Resumo em 30 segundos
- O Problema: O RoCEv2 exige uma rede sem perdas (lossless). O PFC atinge isso pausando o tráfego quando os buffers enchem, mas pode causar travamentos em cascata (tempestades) se um nó for lento ou falhar.
- O Sintoma: Latência de disco dispara para segundos, throughput cai a zero e o cluster parece "congelado", mesmo com discos saudáveis.
- A Solução: Implementar PFC Watchdogs nos switches para descartar pacotes de fluxos travados e utilizar ECN (Explicit Congestion Notification) para gerenciar o congestionamento antes que a pausa seja necessária.
A mecânica do RoCEv2 e a fragilidade do lossless
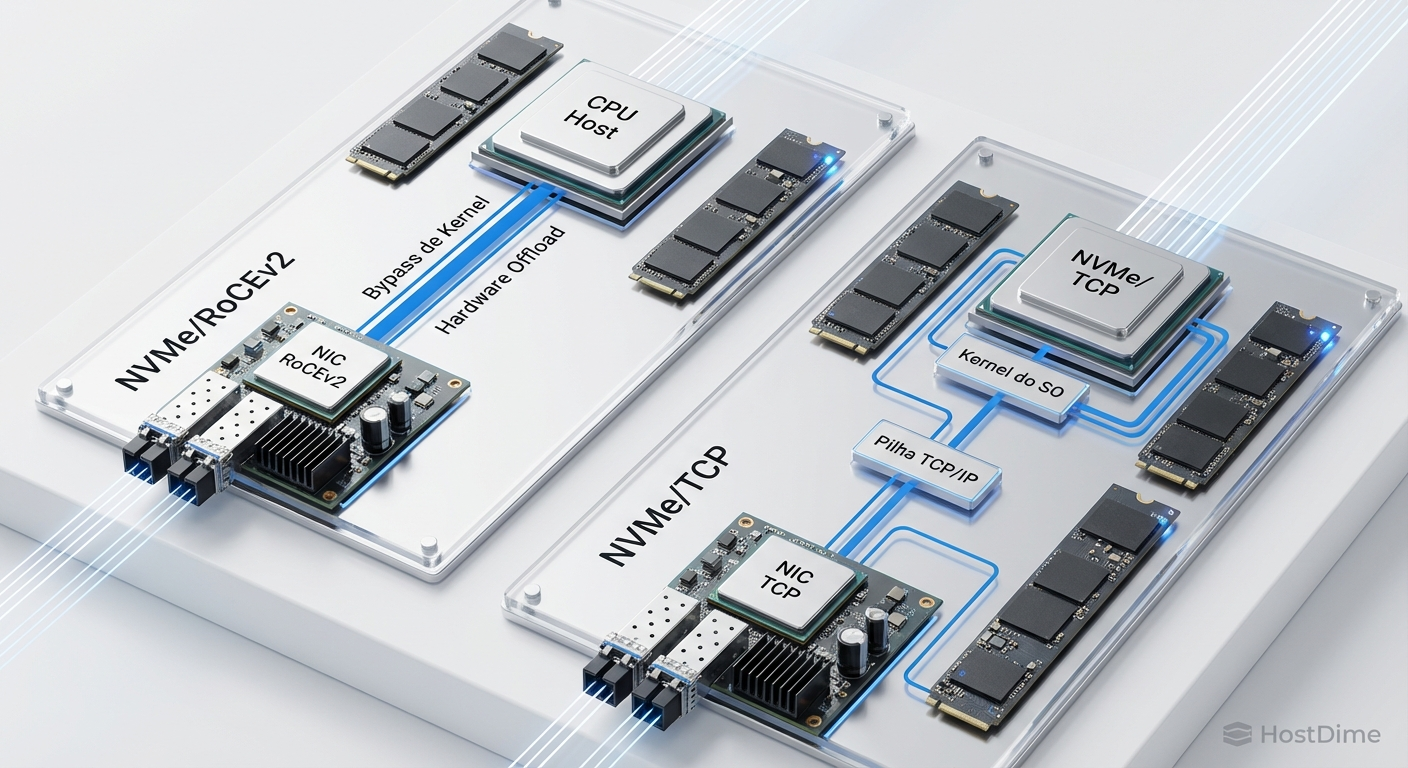
O protocolo NVMe foi desenhado para paralelismo massivo e baixa latência, eliminando a pilha de software legada do SCSI. Quando estendemos isso para a rede via NVMe-oF com transporte RDMA (RoCEv2), transferimos dados diretamente da memória de uma máquina para outra, sem envolver a CPU (kernel bypass).
Para que o RDMA funcione eficientemente sobre Ethernet, a rede não pode perder pacotes. Diferente do TCP, que lida bem com retransmissões, o RDMA sofre penalidades severas de desempenho se houver packet loss. Para resolver isso, a indústria adotou o IEEE 802.1Qbb, ou Priority Flow Control (PFC).
O PFC divide o tráfego Ethernet em 8 classes de prioridade (CoS). Se o buffer de recepção de uma prioridade específica (digamos, a prioridade 3 usada para Storage) encher, o receptor envia um quadro de pausa (Pause Frame) para o emissor, dizendo: "Pare de enviar tráfego na prioridade 3".
O efeito dominó (Head-of-Line Blocking)
O sistema funciona perfeitamente em pequena escala. O problema surge quando temos congestionamento sustentado ou um "slow drainer" (um servidor recebendo dados lentamente devido a problemas de CPU, PCIe ou disco ruim).
O Servidor A (lento) enche seu buffer e envia PAUSE para o Switch ToR.
O Switch ToR para de enviar para o Servidor A, mas continua recebendo dados de outros lugares destinados a ele. O buffer do switch enche.
O Switch ToR envia PAUSE para o Switch Spine.
O Switch Spine para o tráfego na prioridade 3 para toda a porta conectada ao ToR.
Neste ponto, qualquer outro servidor conectado àquele Spine que tente enviar dados na prioridade 3 será bloqueado, mesmo que seu destino não seja o Servidor A. O congestionamento se espalha viralmente, criando uma "tempestade de PFC".
 Figura: Diagrama de propagação de contrapressão (Backpressure): um receptor lento inicia uma cadeia de comandos de pausa que satura os buffers dos switches, bloqueando tráfego de nós saudáveis.
Figura: Diagrama de propagação de contrapressão (Backpressure): um receptor lento inicia uma cadeia de comandos de pausa que satura os buffers dos switches, bloqueando tráfego de nós saudáveis.
Diagnóstico: métricas que importam
Como SREs, não podemos confiar em reclamações de usuários ("o sistema está lento"). Precisamos de observabilidade. O diagnóstico de tempestades de PFC exige monitoramento granular nos switches e nas placas de rede (NICs/HCAs).
Se você monitora apenas largura de banda e erros de CRC, você está cego para este problema. As métricas vitais residem nos contadores de controle de fluxo.
Contadores essenciais
Em um ambiente Linux com NICs Mellanox (ConnectX-5 ou superior), por exemplo, ethtool -S é seu melhor amigo. Procure por:
rx_pfc_pause_frames: Quantas vezes este nó pediu para o vizinho parar.tx_pfc_pause_frames: Quantas vezes o vizinho (switch) mandou este nó parar.rx_pfc_pause_duration: Tempo total que o tráfego ficou parado.
💡 Dica Pro: A existência de quadros de pausa não é necessariamente ruim; é o mecanismo funcionando. O problema é a taxa e a duração. Um contador incremental constante é normal. Um salto de milhões de quadros em segundos indica uma tempestade.
Tabela comparativa: comportamento saudável vs. patológico
| Métrica | Comportamento Saudável (Micro-bursts) | Comportamento Patológico (PFC Storm) |
|---|---|---|
| Frequência de Pausa | Esporádica, correlacionada a picos de escrita. | Contínua, sustentada por segundos ou minutos. |
| Impacto na Latência | Aumento marginal na latência média. | Latência de cauda (p99) dispara (ms para s). |
| Throughput | Mantém-se próximo ao line-rate. | Cai drasticamente, oscilando perto de zero. |
| Escopo | Isolado a um par de nós ou rack. | Espalha-se por múltiplos racks ou pods. |
Mitigação: quebrando o ciclo de feedback
Aumentar os buffers dos switches não resolve o problema; apenas adia o inevitável e aumenta a latência máxima. Para mitigar tempestades de PFC, precisamos de mecanismos que atuem antes da saturação total ou que quebrem o travamento quando ele ocorrer.
1. Implementação de PFC Watchdog
O PFC Watchdog é um mecanismo de segurança nos switches. Ele monitora quanto tempo uma fila de prioridade está em estado de pausa. Se esse tempo exceder um limite configurado, o switch toma uma decisão drástica: ele descarta todos os pacotes daquela fila e libera o buffer.
Isso viola o princípio "lossless"? Sim. Mas em um cenário de tempestade, a rede já está inutilizável. O Watchdog sacrifica os pacotes do fluxo problemático para salvar o restante do cluster.
Configuração típica: Detectar travamento após 100-200ms.
Ação: Dropar pacotes e enviar um alerta SNMP/Syslog.
2. Notificação Explícita de Congestionamento (ECN/DCQCN)
Enquanto o PFC é reativo (para tudo!), o ECN é proativo. Ele utiliza os bits do cabeçalho IP (campo ToS/DSCP) para marcar pacotes quando o buffer do switch começa a encher, mas antes de estar cheio.
Quando o receptor (target NVMe) vê um pacote com o bit de congestionamento marcado (CE - Congestion Experienced), ele notifica o emissor (initiator) através de um pacote CNP (Congestion Notification Packet). O emissor então reduz sua taxa de transmissão voluntariamente.
Isso cria um loop de controle de fluxo suave, mantendo os buffers dos switches vazios o suficiente para absorver micro-bursts sem acionar o PFC brutal.
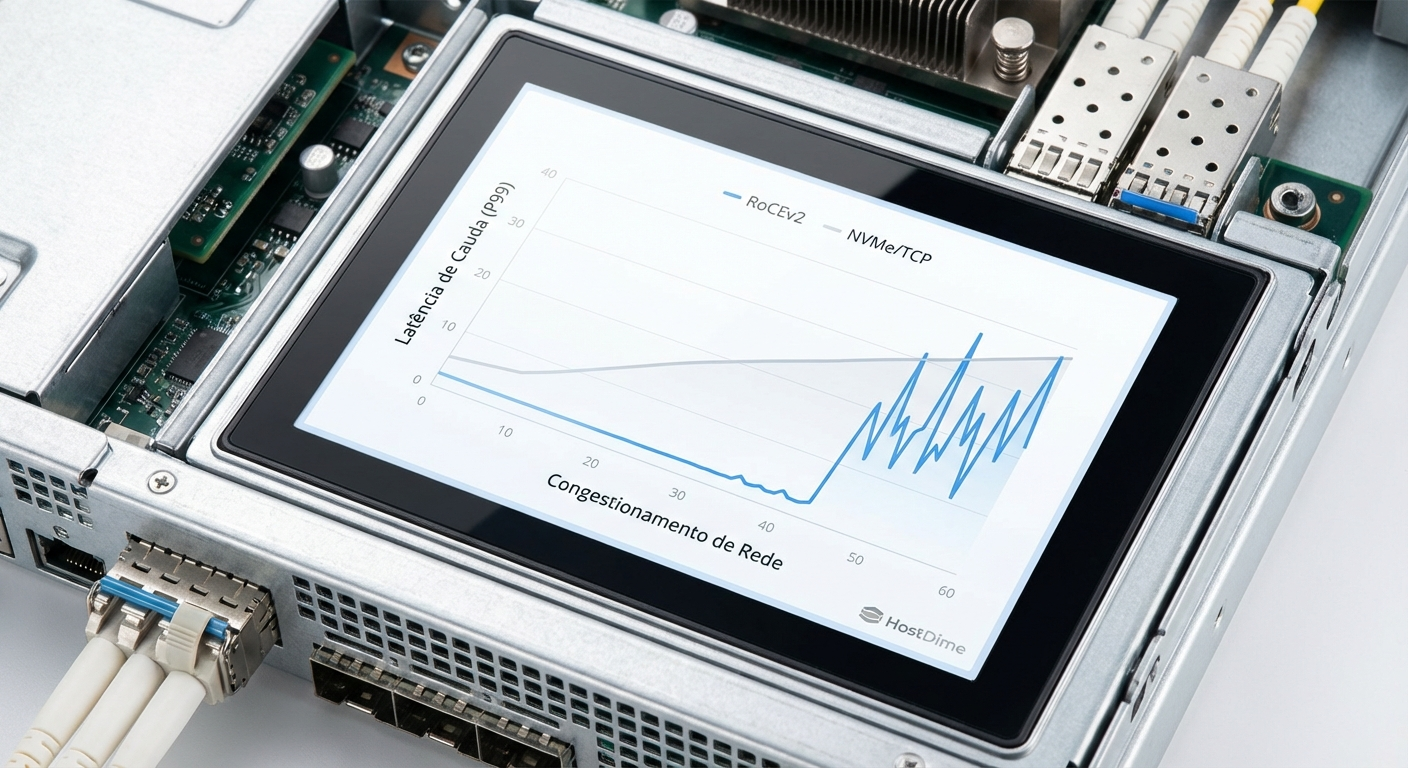 Figura: Comparação visual: PFC atua como um sinal vermelho abrupto parando o tráfego, enquanto ECN funciona como um limitador de velocidade dinâmico, ajustando o fluxo antes que o congestionamento ocorra.
Figura: Comparação visual: PFC atua como um sinal vermelho abrupto parando o tráfego, enquanto ECN funciona como um limitador de velocidade dinâmico, ajustando o fluxo antes que o congestionamento ocorra.
⚠️ Perigo: Configurar DCQCN (Data Center Quantized Congestion Notification) é complexo. Se os parâmetros de alpha e beta (taxa de redução e recuperação) forem mal ajustados, você pode subutilizar drasticamente sua rede de 100/400Gbps.
Validando SLOs de armazenamento
Como engenheiros de confiabilidade, não nos importamos apenas se "está funcionando", mas se está dentro dos objetivos de nível de serviço. Para NVMe-oF, seus SLIs (Service Level Indicators) devem incluir métricas de rede.
Se o seu SLO de latência de disco é "99% das leituras abaixo de 500µs", uma tempestade de PFC fará você queimar seu error budget em minutos.
Recomendação de monitoramento para o dashboard do Grafana:
Taxa de Pausa por Host: Alerta se
rate(rx_pfc_pause_frames)> X por segundo.Disparos de Watchdog: Alerta crítico se qualquer switch registrar
pfc_watchdog_events. Isso significa que houve perda de dados para salvar a malha.Congestionamento ECN: Monitorar a taxa de pacotes marcados com CE. Isso indica se sua rede está operando no limite da capacidade.
O futuro é roteado?
Embora o RoCEv2 com PFC e ECN seja o padrão atual para alta performance em Enterprise Storage, a complexidade operacional é alta. A indústria começa a olhar para o NVMe/TCP como uma alternativa viável. Com as otimizações recentes de hardware e software, o NVMe/TCP oferece performance próxima ao RDMA, mas utilizando a robustez do controle de congestionamento do TCP, eliminando a necessidade de uma rede lossless e o pesadelo do PFC.
Até que essa transição ocorra, a higiene da sua rede RoCEv2 depende de:
Isolamento estrito de tráfego de armazenamento em filas de prioridade dedicadas.
Uso mandatório de ECN/DCQCN.
PFC Watchdogs ativos como última linha de defesa.
Não deixe que um cabo ruim derrube seu datacenter inteiro. Culpe o sistema que permite a propagação da falha, e projete a rede para conter o dano.
Referências & Leitura Complementar
IEEE 802.1Qbb: Priority-based Flow Control - O padrão base para Ethernet sem perdas.
RFC 3168: The Addition of Explicit Congestion Notification (ECN) to IP.
NVIDIA/Mellanox Community: "Understanding PFC and RoCEv2 Congestion Management" - Documentação técnica essencial para tuning de NICs ConnectX.
SNIA (Storage Networking Industry Association): Especificações de NVMe over Fabrics.
Perguntas Frequentes (FAQ)
O que é uma tempestade de PFC em redes de storage?
É um evento catastrófico onde um dispositivo de rede (NIC ou switch) trava enviando quadros de pausa continuamente. Isso propaga o congestionamento por toda a malha (backpressure), paralisando o tráfego de armazenamento de nós que nem sequer estão envolvidos no problema original.É possível usar NVMe-oF sem Priority Flow Control (PFC)?
Sim. Você pode utilizar o transporte **NVMe/TCP**, que lida com a perda de pacotes nativamente via TCP e não exige uma rede lossless. Outra opção é implementar RoCEv2 apenas com ECN (Explicit Congestion Notification) em redes "Lossy" altamente tunadas, embora o PFC ainda seja o padrão recomendado para garantir a performance máxima do RDMA.Como o ECN ajuda a mitigar problemas de PFC?
O ECN (Explicit Congestion Notification) atua como um aviso prévio. Ele sinaliza o congestionamento marcando pacotes antes que o buffer do switch encha completamente. Isso permite que os emissores reduzam a taxa de transmissão suavemente, evitando a necessidade de o switch enviar um comando de pausa brutal (PFC) que paralisaria a fila.
Rafael Junqueira
Engenheiro de Confiabilidade (SRE)
"Transformo caos em estabilidade via observabilidade. Defensor da cultura blameless e focado em SLIs e SLOs. Se algo falhou, revisamos o sistema, nunca a pessoa."