Zoned Namespaces: O fim da taxa de indireção em SSDs QLC

Descubra como o padrão NVMe ZNS (TP 4053) elimina a amplificação de escrita, reduz a latência de cauda e viabiliza o uso de flash QLC em workloads de alta performance como RocksDB.
O pager toca às 03:14 da manhã. O alerta é claro: violação de SLO na latência de cauda (P99). O dashboard mostra picos de latência de escrita excedendo 500ms em um cluster de banco de dados distribuído que, até então, operava confortavelmente abaixo de 10ms. A carga de trabalho não mudou. O tráfego de rede está estável. A CPU está ociosa.
Ao investigar as métricas de disco, encontramos o culpado silencioso: o Garbage Collection (GC) do firmware do SSD entrou em colisão direta com a compactação do banco de dados. Estamos queimando ciclos de escrita, desgastando células QLC prematuramente e pagando o que chamamos de "taxa de indireção".
Este cenário é comum em infraestruturas que tentam escalar armazenamento de alta densidade (QLC) com padrões de escrita tradicionais. A indústria de armazenamento respondeu a isso não com mais cache ou controladores mais rápidos, mas com uma mudança arquitetural na especificação NVMe: Zoned Namespaces (ZNS).
Resumo em 30 segundos
- O Problema: SSDs convencionais possuem uma camada de tradução (FTL) que causa amplificação de escrita (WAF) severa, especialmente nociva em memórias QLC sensíveis.
- A Causa: A "colisão de logs" ocorre quando o banco de dados tenta organizar dados sequencialmente, mas o SSD os espalha internamente, forçando limpezas agressivas.
- A Solução: O ZNS remove a FTL complexa, expondo a geometria física do disco ao host e permitindo um WAF próximo de 1.0, o que viabiliza o uso de QLC em alta performance.
O conflito: Log-Structured Merge Trees vs. Firmware
Para entender por que precisamos de ZNS, primeiro precisamos dissecar a falha do modelo atual. A maioria dos bancos de dados modernos de alta performance (RocksDB, Cassandra, ScyllaDB) utiliza estruturas LSM-tree (Log-Structured Merge-tree). O princípio é elegante: transformar escritas aleatórias em escritas sequenciais em memória, que são então despejadas no disco em arquivos imutáveis (SSTables).
Teoricamente, isso deveria ser perfeito para SSDs. Na prática, é um desastre de eficiência devido à abstração de "Dispositivo de Bloco".
O sistema operacional vê o SSD como uma grande matriz linear de blocos lógicos (LBAs). Quando o banco de dados escreve sequencialmente, ele acredita estar ajudando o disco. No entanto, dentro do SSD, a Flash Translation Layer (FTL) está mapeando esses LBAs para páginas físicas (PBA) de maneira dinâmica.
Quando o banco de dados decide apagar ou compactar dados antigos, ele invalida blocos lógicos. O controlador do SSD, desconhecendo a lógica da aplicação, vê apenas "buracos" em suas páginas físicas. Isso aciona o Garbage Collection interno do drive, que copia dados válidos para novos blocos e apaga os antigos.
Temos aqui o fenômeno "Log-on-Log":
O Host faz GC (Compactação da LSM-tree).
O Dispositivo faz GC (Limpeza de blocos NAND).
O resultado é uma Amplificação de Escrita (WAF - Write Amplification Factor) composta. Se sua aplicação tem WAF de 3.0 e o SSD tem WAF de 4.0, a amplificação total é multiplicativa. Você está escrevendo 12 vezes mais dados na mídia física do que a aplicação solicitou.
 Figura: Comparação do fluxo de dados: A ineficiência do "Log-on-Log" em SSDs convencionais versus o alinhamento direto no ZNS.
Figura: Comparação do fluxo de dados: A ineficiência do "Log-on-Log" em SSDs convencionais versus o alinhamento direto no ZNS.
A física do QLC e a falácia do Over-provisioning
A situação se agrava com a memória QLC (Quad-Level Cell). Para armazenar 4 bits por célula, a margem de tensão é minúscula e a durabilidade é significativamente menor que TLC ou MLC. Além disso, os blocos de apagamento (Erase Blocks) em QLC são massivos, muitas vezes na casa de dezenas de megabytes.
Em um SSD convencional, para mitigar o impacto do GC em blocos tão grandes, os fabricantes aumentam o Over-provisioning (OP). Em drives Enterprise, é comum ver 28% ou mais de capacidade reservada apenas para manobras de background.
⚠️ Perigo: Confiar apenas em Over-provisioning para resolver problemas de latência em QLC é uma armadilha. O OP amortece picos médios, mas não elimina a latência de cauda quando o drive está cheio e sob carga de escrita sustentada. A física da NAND exige tempo para apagar blocos, e nenhum buffer de DRAM infinito pode esconder isso para sempre.
O custo desse OP é imenso. Você compra 100TB de flash cru, mas só pode usar 70TB efetivamente, apenas para manter a "ilusão" de um dispositivo de bloco aleatório que o sistema operacional espera. Estamos desperdiçando densidade e dinheiro para sustentar uma abstração legada dos tempos dos discos rígidos rotacionais.
Zoned Namespaces: Expondo a realidade física
A especificação NVMe Zoned Namespaces (TP 4053), ratificada em 2020, propõe uma solução radical: remover a mentira.
Em um SSD ZNS, o espaço de endereçamento lógico é dividido em Zonas. Existem regras estritas para interagir com essas zonas:
Escrita Sequencial Obrigatória: Dentro de uma zona, as escritas DEVEM ser sequenciais. Você não pode escrever no LBA 0, depois no 10, depois no 5. Deve ser 0, 1, 2, 3...
Reset Explícito: Para reescrever dados, a zona inteira deve ser resetada (apagada). Não há sobrescrita de bloco único (in-place update).
Isso soa como uma restrição, mas é uma libertação. Ao alinhar o tamanho da Zona Lógica com o tamanho do Bloco de Apagamento Físico (ou um múltiplo dele) da NAND, eliminamos a necessidade do SSD adivinhar onde colocar os dados.
O fim da Tabela de Mapeamento (L2P)
Em SSDs convencionais, a FTL mantém uma tabela de mapeamento gigantesca (L2P - Logical to Physical) na DRAM do controlador (geralmente 1GB de DRAM para cada 1TB de Storage). Isso consome energia, espaço e custo.
Com ZNS, como a relação entre LBA e local físico é fixa dentro da zona, essa tabela de tradução global desaparece quase completamente. O controlador do SSD se torna mais simples, mais barato e consome menos energia. A responsabilidade de "onde colocar os dados" sobe para o Host (Sistema Operacional ou Aplicação).
Tabela Comparativa: SSD Convencional vs. ZNS
| Característica | SSD Convencional (Block Device) | SSD Zoned Namespaces (ZNS) |
|---|---|---|
| Interface | NVMe (Padrão) | NVMe (Command Set ZNS) |
| Padrão de Escrita | Aleatório permitido | Sequencial obrigatório por zona |
| Gestão de GC | Firmware do SSD (Caixa Preta) | Host / Aplicação (Controlado) |
| WAF (Write Amp) | Alto (2.0x - 4.0x típico) | Próximo de 1.0x |
| Uso de DRAM | Alto (Tabela L2P grande) | Mínimo (Apenas buffers) |
| Over-provisioning | Necessário (7% a 28%+) | Mínimo / Inexistente (0%) |
| Latência de Cauda | Imprevisível (Picos de GC) | Determinística |
Implementação: O ecossistema de software
A adoção de ZNS não é "plug-and-play" para sistemas legados. Você não pode simplesmente formatar um SSD ZNS com NTFS ou ext4 antigo e esperar que funcione. O sistema de arquivos precisa ser Zone-Aware.
Suporte no Kernel Linux
O suporte para Zoned Block Devices amadureceu significativamente. O kernel Linux (a partir da versão 5.9) possui a infraestrutura necessária no subsistema de blocos para expor zonas. Sistemas de arquivos como F2FS (Flash-Friendly File System) e Btrfs receberam patches para suportar dispositivos zoneados nativamente. O F2FS, em particular, é um candidato excelente, pois sua estrutura de log já se alinha naturalmente com o conceito de zonas.
O caso do RocksDB e ZenFS
O "estado da arte" para SREs que gerenciam grandes volumes de dados é pular o sistema de arquivos tradicional completamente.
O projeto ZenFS é um backend de sistema de arquivos para o RocksDB que fala diretamente com dispositivos ZNS.
O RocksDB gera SSTables (arquivos sequenciais).
O ZenFS mapeia cada SSTable diretamente para uma Zona ZNS.
Quando o RocksDB decide apagar um arquivo SSTable, o ZenFS envia um comando de
Zone Resetpara a zona correspondente.
Não há adivinhação. Não há GC no firmware. O WAF do dispositivo cai para 1.0.
💡 Dica Pro: Ao implementar ZNS com ZenFS, configure o tamanho alvo dos arquivos SSTable do RocksDB para coincidir com o tamanho da zona do SSD (ou divisores exatos). Isso garante que não haja desperdício de espaço no final de uma zona parcialmente escrita.
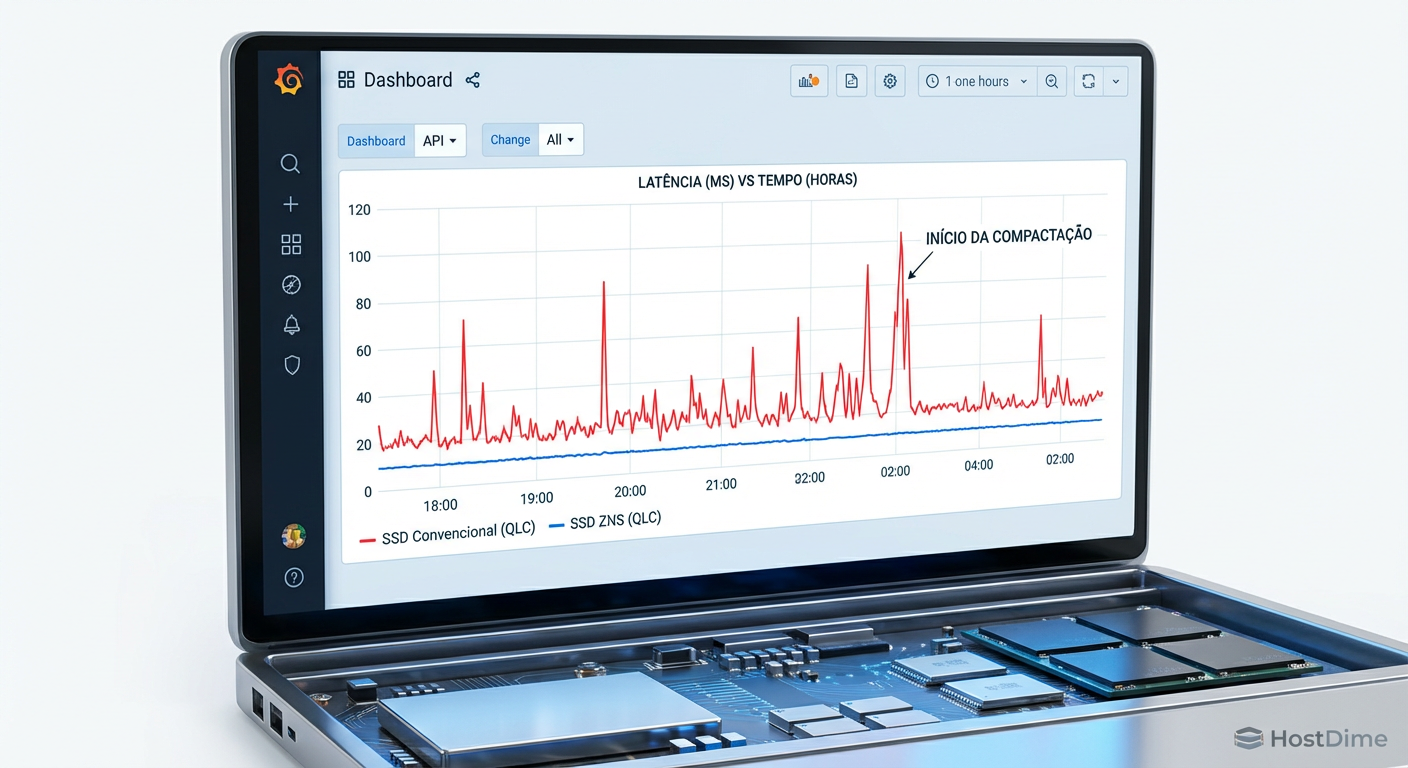 Figura: Monitoramento de latência: A estabilidade do ZNS frente aos picos imprevisíveis de um SSD convencional durante cargas de trabalho intensas.
Figura: Monitoramento de latência: A estabilidade do ZNS frente aos picos imprevisíveis de um SSD convencional durante cargas de trabalho intensas.
Reduzindo o WAF e estendendo a vida útil
Para um Engenheiro de Confiabilidade, a métrica de ouro aqui não é apenas a performance, mas a durabilidade.
Considere um drive QLC com capacidade de 3.000 ciclos de P/E (Program/Erase).
Cenário Convencional (WAF 3.0): Para cada 1TB de dados úteis escritos, você consome 3TB da vida útil da flash.
Cenário ZNS (WAF 1.0): Para cada 1TB de dados úteis, você consome 1TB da vida útil.
Efetivamente, a migração para ZNS triplica a vida útil do seu hardware sem trocar o componente físico. Isso altera fundamentalmente o TCO (Total Cost of Ownership) de clusters de armazenamento. Permite o uso de QLC em cenários de escrita intensiva que antes eram domínio exclusivo de TLC ou até SLC, simplesmente removendo a ineficiência do software intermediário.
Perspectivas e Alerta Operacional
O Zoned Namespaces representa a maturidade da tecnologia Flash. Paramos de fingir que SSDs são discos magnéticos rápidos e começamos a tratá-los como a mídia única que são.
Para 2026 e além, a previsão é que o ZNS se torne o padrão de facto para armazenamento em hiperescala e datacenters focados em eficiência. A complexidade de gerenciamento de zonas está sendo rapidamente absorvida por bibliotecas de software (como SPDK e xNVMe), tornando a barreira de entrada menor a cada release do kernel.
No entanto, um alerta operacional: a transição exige validação completa da pilha de software. Aplicações que dependem de in-place updates frequentes (como bancos de dados relacionais legados rodando sobre sistemas de arquivos não otimizados) terão performance degradada ou simplesmente não funcionarão em ZNS sem uma camada de emulação (como o dm-zoned), o que derrota o propósito da tecnologia.
Como SREs, nossa função é identificar onde a abstração falha. No caso do armazenamento QLC, a abstração de bloco falhou. O ZNS é a correção arquitetural necessária.
Referências & Leitura Complementar
NVM Express Base Specification 2.0: Seções referentes ao Command Set Zoned Namespaces.
NVMe TP 4053: A proposta técnica original que definiu o ZNS.
SNIA (Storage Networking Industry Association): Whitepapers sobre Zoned Storage e a API Zoned Block Device.
Bjørling, M., et al. (2021): "ZNS: Avoiding the Block Interface Tax for Flash-based SSDs" (Paper acadêmico fundamental apresentado na USENIX ATC).
Western Digital & Samsung Datasheets: Especificações de drives eSSDs (Enterprise SSDs) com suporte a ZNS (ex: Ultrastar DC ZN540).
O que é NVMe Zoned Namespaces (ZNS)?
É uma extensão do padrão NVMe (TP 4053) que divide o espaço de armazenamento em zonas que devem ser escritas sequencialmente. Isso transfere a responsabilidade do posicionamento de dados do controlador do SSD para o software do host, eliminando a necessidade de uma camada de tradução de flash (FTL) complexa e opaca.Como o ZNS afeta a vida útil de SSDs QLC?
Ao garantir que as gravações sejam sequenciais e alinhadas com a geometria física da memória NAND, o ZNS reduz o Fator de Amplificação de Escrita (WAF) para próximo de 1.0. Isso evita ciclos de programação/apagamento desnecessários causados pelo Garbage Collection interno, aumentando drasticamente a durabilidade e a vida útil efetiva do QLC.O ZNS requer mudanças no sistema operacional?
Sim. O suporte a Zoned Block Devices foi introduzido no kernel Linux 5.9 e continua evoluindo. Além disso, aplicações como bancos de dados precisam usar sistemas de arquivos compatíveis (como F2FS ou Btrfs em modo zoneado) ou backends de armazenamento específicos (como ZenFS para RocksDB) para gerenciar as zonas corretamente.
Rafael Junqueira
Engenheiro de Confiabilidade (SRE)
"Transformo caos em estabilidade via observabilidade. Defensor da cultura blameless e focado em SLIs e SLOs. Se algo falhou, revisamos o sistema, nunca a pessoa."